对于采样率为Fs,长度为M个采样点的音频信号x[n],,通过采样因子P/Q进行重采样后,这个信号的样本数可以增大或者减小。该过程可以分为如下三个步骤[17]:
(1)上采样:在原信号相邻两点内插入P-1个零点,即创建一个有P (M-1) 1个采样点的信号xu[n],当n=1,2,…,M时,xu[P(n-1) 1] = x[n];否则,xu[n]=0。
(2)插值:xu[n]和一个低通插值滤波器h[n]作卷积:xi[n]= xu[n]h[n]。
(3)下采样:每隔Q-1个点抽取一个点,即创建有Q个点的信号xd[n],当n=1,2,…, 1时,xd[n]=xi[1 Q (n-1)],则重采样信号y[n]=xd[n]。(符号表示向下取整数)
不同类型的重采样算法都可以分为上述三个过程,它们的唯一的区别就在于步骤2中所采用的插值滤波器的不同。其中,线性插值是最简单的插值算法,如式(4-1)。另外,常见的插值还包括样条插值、三次方插值等。
注意事项:
1.上采样时,会造成镜像信息,因此需要使用低通滤波器滤除(线性插值本身就是低通滤波器,因此不需要额外处理)。
2.下采样时,可能会造成频谱混淆,因此在下采样之前用低通去混淆滤波器滤除。
3.重采样算法非常消耗时间,使用多相滤波器与一些条件限制,可以大大提高运算速度。
开源代码:
1.http://code.google.com/p/falab/
该段代码是针对单声道音频的重采样,不能直接分包(分段)处理。
对于多声道音频的重采样,需要自己改写,可以支持多声道、分段重采样。
2.ffmpeg内部集成了一套重采样代码。
可以处理多声道音频的重采样,可以分段处理。但是存在一些bug。有些声道转起来会出问题、不支持,例如双声道转单声道。
3.speex也集成了重采样接口
下采样时,对离散信号再次进行P抽样(类似连续信号抽样);然后进行抽取。
抽样,会引起频谱周期性偏移扩展, 2pi/P。
抽取,相当于时域压缩,傅里叶变换对应于频域拉伸P倍。

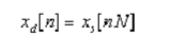



【免费分享】资料内容包括《Andoird音视频开发必备手册 学习文档资料包 音视频最新学习视频 大厂面试真题 2022最新学习路线图》点击链接加卫星领取FFmpegWebRTCRTMPRTSPHLSRTP播放器-音视频流媒体高级开发

C 音视频学习交流裙788280672


-pi~pi; 原始离散信号截止频率, -w0~w0, 扩展后 -w0*p~w0*p; w0*p <=pi;
滤波器截止频率:w0<= pi/P; 对原始信号进行提前滤波操作。
抽取,相对于原始离散信号,频谱发生拉伸,容易造成混叠。
同理,对于内插过程:
内插的插零操作,相当于时域拉伸,对应于频谱压缩,造成镜像;
第二步,通过低通滤除镜像。

原始信号-pi~pi,重复出现。
压缩N倍,则 原始信号 -pi*N~pi*N, 压缩到 -pi*pi;
有效带宽 -w~w;则压缩后变成了, -w/N~-w/N, -pi~pi压缩成 -pi/N~pi/N;其它镜像通过低通滤波器滤除掉。
截止频率为 pi/N
内插值的过程,相当于低通滤波。
【免费视频】关于音视频开发系列、音频重采样,推荐一个非常好的学习地址,先关注不迷路!点击免费报名,开启你的学习之路吧![给力]
【免费】FFmpeg/WebRTC/RTMP/NDK/Android音视频流媒体高级开发-学习视频教程-腾讯课堂
,




