今天把潜变量和降维分析的方法合起来给大家写写,因为这两个东西之间有诸多共同之处。
潜变量为啥需要潜变量呢?考虑一个问题,比如你想测测一个人有多幸福,你怎么测?
估计你会看看这个人:
- 脸上有没有笑容
- 有没有加薪
- 是不是健康
- 爱不爱交际
等等,你试图通过这么一些可以测量的指标来反映一个人的所谓的幸福的状况,这个是我们自然而然想得到的,因为我们心里明白幸福是一个抽象概念,不能直接测,所以叫做潜变量。
降维Dimension Reduction/Compression在机器学习中专门有讲降维的算法,但是在社会科学领域运用较多的还是因子分析和主成分分析。我们一个一个来看:
主成分分析主成分分析是因子分析中提取因子的一个重要技巧,它要做的事就是从一系列的变量中提取成分,每个成分我们都希望它能解释原始数据尽可能多的变异。
记住一句话:成分是原始变量的线性组合。
Components are linear combination of the original variables.
在做主成分分析的时候我们会得到和变量一样多的成分,每个成分都会比前一个成分解释的变异少一点,然后所有成分解释原始数据变异的100%。
理论上我们可以从成分中完全复原我们的原始数据,但是我们的目的是要降维嘛,所以我们通常不会保留所有的成分,只会保留主成分。

上图就是一个主成分分析的示意图,4个原始变量,4个成分,很可能我们就只保留前两个成分就行。
主成分分析实例用到的数据为Harman.5,这个数据集包含5个变量。我们可以用psych包的principal函数进行主成分分析,使用这个函数你只需要给出数据集和你想要保留的主成分个数就行。比如我想2个:
library(psych)
pc = principal(Harman.5, nfactors=2, rotate='none', covar = F)
pc
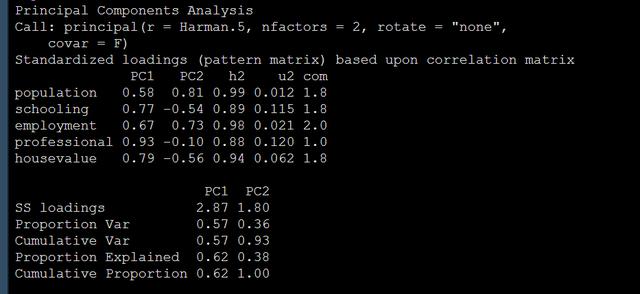
如果你想要5个成分都出来,只需要把nfactors改成5就行。
解释一下结果的输出:
SS loadings,这个是变量在每个成分的载荷平方和sum of the squared loadings,理论上一共有5个成分,这个5个成分的载荷平方和相加为1。
Proportion Var,这个是该成分解释的方差占比。就是用SSloading比上5得到的。
Cumulative Var,这个是累计方法差解释比,可以看到只要2个成分就解释了源数据93%的变异。很棒。
h2,这个是成分解释的变量变异的比例,因为我们只保留了2个主成分,所以不是1,如果保留5个主成分,这个值就应该是1.
u2,这个是1-h2
com,这个是complexity,如果这个值为1就说明这个变量只在一个成分上有载荷,为0就是都没有。
但是我们在看loading的结果,这下就尴尬,我们看到成分1真的很强大,所有的变量在成分11上面的载荷都很高,这样的话我们就没法给成分命名了呀。
上面我们做出来的主成分分析的可视化表达如下:

可以看到成分1和所有的变量联系都挺强的,所以这个方法并不是一个可以解释的好的方法。
因子分析因子分析和主成分分析都是降维的方法,在主成分分析中每个主成分都是所有变量的线性组合。画出图来应该是这个样子的:

但是在因子分析中,上面的关系变了
在因子分析中,我们认为所有的变量都是由因子造成的,当然了这个过程是允许误差存在的,所以在因子分析中会有一个误差项,通过因子并不能完全的复原原始数据,但是主成分是可以的哦。

贴几句原文大家自己体会:
Factor analysis focuses on covariance. PCA focuses on variance.
Factors are the cause of the observed variables, variables are the cause of components.
Factor analysis does not assume perfect measurement of observed variables.
因子分析实操我们还是用同样的数据进行因子分析:
fac = fa(Harman.5, nfactors=2, rotate='none')
fac

同样的道理,如果你要做5因子模型,就将nfactors改成5就行,这儿从结果看2因子模型已经解释了原始数据变异的90%,已经非常好了,同时我们注意第一个因子解释原始数据变异的0.55,第二个解释了0.35,其实差别没那么大。
还要强调的是因子分析的时候默认因子之间是可以有相关的,这个与PCA是不同的。所以就有可能出现一个显变量虽然在因子1上没有载荷在其他因子之间有载荷,但是因子之间有相关,所以显变量和因子1的相关也是抹不掉的。
但是,你如果把因子进行正交旋转orthogonal rotations,那么因子分析就和主成分分析一样了。所以你会看到SPSS中把主成分分析归在因子分析中的。
所以记住因子分析就是非正交旋转的主成分分析。
主成分分析就是正交旋转的因子分析,因子之间不存在相关。
PCA and FA are identical if there is only one factor or the factors are orthogonal
实例辨析两者差异首先我们来做因子分析,并给出载荷:
fac2 = fa(Harman.5, nfactors=2)
fac2$loadings[] %>% round(2)
fac2$Structure[] %>% round(2)


解释一下上面两个结果,两个都是载荷,都差不多,第一个是pattern coefficients,第二个是structure coefficients:
- pattern coefficients: these are the standard loadings you see
- structure coefficients: the correlation of an observed variable with a factor that reflects any association, causal or otherwise.
再来做主成分分析给出载荷:
pc = principal(Harman.5, nfactors=2, rotate= "none" , covar = T)
pc

可以看到两个方法做出来的载荷基本上一样。
小结今天由潜变量引出,给大家写了PCA和FA的异同,希望对大家有启发,感谢大家耐心看完,自己的文章都写的很细,代码都在原文中,希望大家都可以自己做一做,请关注后私信回复“数据链接”获取所有数据和本人收集的学习资料。如果对您有用请先收藏,再点赞转发。
也欢迎大家的意见和建议,大家想了解什么统计方法都可以在文章下留言,说不定我看见了就会给你写教程哦。
如果你是一个大学本科生或研究生,如果你正在因为你的统计作业、数据分析、论文、报告、考试等发愁,如果你在使用SPSS,R,Python,Mplus, Excel中遇到任何问题,都可以联系我。因为我可以给您提供好的,详细和耐心的数据分析服务。
如果你对Z检验,t检验,方差分析,多元方差分析,回归,卡方检验,相关,多水平模型,结构方程模型,中介调节,量表信效度等等统计技巧有任何问题,请私信我,获取详细和耐心的指导。
If you are a student and you are worried about you statistical #Assignments, #Data #Analysis, #Thesis, #reports, #composing, #Quizzes, Exams.. And if you are facing problem in #SPSS, #R-Programming, #Excel, Mplus, then contact me. Because I could provide you the best services for your Data Analysis.
Are you confused with statistical Techniques like z-test, t-test, ANOVA, MANOVA, Regression, Logistic Regression, Chi-Square, Correlation, Association, SEM, multilevel model, mediation and moderation etc. for your Data Analysis...??
Then Contact Me. I will solve your Problem...
加油吧,打工人!
猜你喜欢R数据分析:探索性因子分析
如何做主成分分析和因子分析?它们的区别与联系在哪里?
R数据分析:如何用R做验证性因子分析及画图,实例操练
R数据分析:相关性分析
R数据分析:双因素方差分析与交互作用检验
R数据分析:如何做聚类分析,实操解析
R数据分析:主成分分析及可视化
R数据分析:生存分析的做法与解释续
R数据分析:如何做潜在剖面分析Mplus
R数据分析:用R语言做潜类别分析LCA
,