前面已经提到了矩阵和向量的乘法运算,这里再对矩阵相乘的概念进行重述。矩阵相乘是基本且常用的运算之一。这里定义矩阵X和矩阵A相乘得到矩阵Y。在定义乘法运算的过程中,需要使X的列数与A的行数相等。将乘法运算写为如下形式。
Y=AX或Y=A.X (1.17)
式(1.17)展示了两种矩阵乘法的书写习惯,前一种是线性代数里常用的矩阵乘法书写形式,后一种在张量分析中常用,代表向量的点乘运算。式(1.18)为写1成分量的形式。
(1.18)

这里有两点需要解释,有时会用字母加下标的方式来表示矩阵元素。而矩阵相乘的过程中,在一部分文献中会写成约定求和的方式,即省略求和符号而用相同的指标/代表求和。对于矩阵的乘法来说,还有其他的乘法形式,如矩阵的哈达玛积( Hadamard Product ) ,就是矩阵的对应元素相乘,其形式如下。
(1.19)
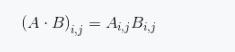
这里需要注意的是,式(1.19)中相同指标并不代表求和,而仅是元素相乘。与之相类似的是矩阵的加法运算,其代表着矩阵对应元素相加。
(1.20)

矩阵运算本身也有着类似于数字运算的法则。
(1)分配率
A(B C)=AB AC
(2)结合律:
(AB)C=A(BC)
(3) 交换律:矩阵运算无交换律。
1 矩阵分块运算和线性变换
回顾如下一种简单的等式。
(1.21)
Y=ax b
这是一种简单的表示形式,它代表x和y之间存在某种关系。如果将x与y看成二维空间中的坐标,那么式(1.21)则代表了空间中的某一条直线。写成矩阵的乘法与加法,则形式如下。
(1.22)
Y=AX B
式(1.22)实际上代表对矩阵X进行线性变换后得到Y的过程。因此矩阵的线性变换实际上就是对式(1.21)的扩展。这代表X与Y之间存在某种简单的关系。取Y,X, B的某一列向量r,y,b,则公式如下。
(1.23)
y=Ax b
这代表着对向量 进行线性变换。在给出式(1.22)的过程中,我们需要解释一个细节,就是矩阵的分块运算。对于矩阵的乘法及加法运算,都可以分解为对子矩阵进行相乘运算。例如将式(1.22)中矩阵的每一列看作一个子矩阵(向量) ,那么 可以写成分块形式。式(1.23)中X就来自于x1~xn。
(1.24)
X=[x1,...,xn]
将Y,B均写成类似的形式,那么X与A的乘法可以写成如下形式。
(1.25)

这就是矩阵的分块运算。当然,分块运算还有其他划分形式,读者可参考线性代数的相关内容。如果令y=0,那么式(1.23)就变成了如下形式。
(1.26)
Ax=-6
式(1.26)是一个标准的线性方程组。从矩阵分块运算的角度来看,将n个未知数的m组方程写成了式(1.23)所示的紧凑形式。矩阵可以简化公式的书写。假设.4矩阵是m行n列的,则严格来说还需要Rank (A) =min(m, n)
(1) 如果m=n,那么代表未知数个数与方程个数是相等的,这是一个适定方程。
(2)如果m<n,那么代表未知数个数大于方程个数,这是一个欠定方程。
(3)如果m >n,那么代表未知数个数小于方程个数,这是一个超定方程。
这就有了3种典型问题。对于适定问题,如果矩阵行列式不等于0,那么方程有唯一解(空间中的一个点) ;对于欠定方程,方程具有无穷多个解(一个空间曲面) ;对于超定方程,仅有近似解。机器学习问题应当都是超定问题,也就是方程个数是多于未知数个数的。但是也有些情况例外,比如深度学习模型,未知数个数可能是大于方程个数的。
现在列举一个简单的例子。假设在二维空间中有(1.0, 1.1) (2.0, 1.9) (3.0,3.1) (4.0, 4.0)共4个点,求解这4个点所在的直线。如果直线方程为y=ax b ,那么将4个数据点代入后会得到4个方程,而未知数有a.6两个,因此这就是一个典型的超定问题。此时,对于a、6取得任何值都无法很好地描述通过4个点的直线。但若取a=1,b=0,此时虽然无法精确地描述z和y的关系,但是通过这种方式可以得到(1.0, 1.0),与数据点相比(1.0, 1.1)十分接近,因此得到了近似意义(最小二乘)上的解。这是一个非常典型的机器学习问题。从这个例子可以看到,实际上机器学习就是一个从数据中寻找规律的过程。而假设数据符合直线分布就是我们给定的模型,求解给定模型参数的过程称为优化。这里不需要读者对机器学习问题进行更多的思考,我们在之后还会进行更详细的阐释。这里只是说明机器学习问题大部分情况下是一个超定问题,但由于可训练参数(也就是未知数)较多,在训练样本(每个训练数据都是一个方程)不足的情况下深度学习模型可能并非超定问题,此时会面临过拟合风险,因此对于机器学习尤其是深度学习需要海量(数量远超未知数的个数,未知数也就是可训练参数的个数)的样本才能学习到有价值的知识。
1.2矩阵分解
上面提到空间中某一坐标向量可以写成多个向量相加的形式。
(1.27)

对于一组不全为0的向量而言,如果其中的任意一个向量都不能由其他向量以式(1.27)的方式表示,那就代表这组向量线性无关或这组向量是线性独立的。
线性独立的概念很重要。如果几个向量线性不独立,即某个向量可以用其他向量表示,那么这个向量就没有存储的必要。举个简单的例子。
(1.28)

式(1.28)代表向量

仍是线性相关的,也就是说,我们仅需存储3个向量其中的两个就可以恢复第3个向量。这种恢复是无损的,是信息压缩最原始的思想。这里加强约束,式(1.27)中等式右边各个向量

之间的关系如下。
(1.29)

式(1.29)中描述的向量是互相正交的关系,并且是单位向量。
(1.30)

单位向量:长度为1的向量。
向量正交:两个向量内积为0。
坐标基向量是最简单的单位向量。
因此,实际上式(1.27)就是对坐标向量进行的坐标基展开,这是在空间中所用到的概念。当然,并不是所有坐标基向量都是正交的,同样也未必是单位向量。
对于一组矩阵的向量

来说,其中的每个向量都可以用其他多个向量以加权求和的方式表示。
(1.31)

其中,

代表第j个单位向量的第i个元素。同样地

代表第k个向量的第i个元素。此时式(1.31)实际上可以表示为矩阵相乘的形式。
(1.32)
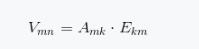
式(1.32)中由向量

组成的矩阵V可以分解为两个矩阵A,E的乘积表示。如果m >k,也就是说,我们可以用少于m个数字来表示向量V,这是一个标准的数据压缩过程。此时, A可以代表矩阵V的特征,如果要恢复V的话,还需要保存E。但是机器学习中通常只需A即可,因为其带有V的信息。
从前面的内容可以知道,式(1.32)是对矩阵进行的线性变换,这个变换的目的在于信息压缩。这个过程中需要的是求解矩阵E。如果W=E^T,则信息压缩方式可以写为如下形式。
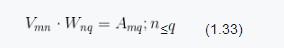
W称为变换矩阵。这是通过矩阵的线性变换来完成数据压缩的过程。
1.3方阵的线性变换:特征值分解
特征值分解是最简单的一种矩阵分解形式,也是矩阵算法中最常用的。特征值分解是对方阵而言的。下面将某个矩阵A分解成3个矩阵相乘的形式。
(1.34)

这是一个矩阵相乘的逆运算,也是一个典型的欠定问题,因为矩阵分解并不是唯一的。为了解决这种非唯一性问题,我们对分解后的矩阵加入约束条件。第一个约束就是特征值分解中E矩阵是正交矩阵。
(1.35)

此时,式(1.33)中的变换矩阵W即为E。另外一个约束就是对角矩阵A ,对角线上的元素称为特征值。E中的向量则称为特征向量。
对于特征值分解而言,其本身具有明确的几何意义。如果将矩阵A当作1.1.2节中的仿射变换矩阵,那么前面提到的坐标与矩阵.4相乘实际上代表了对空间的旋转拉伸变换。由此仿射变换本身可以分解为旋转与拉伸。因此式(1.34)中所得到的矩阵,E代表了对空间的旋转变换, A则代表了对空间的拉伸变换。在此,以二维情况进行简单阐述,如图1.9所示。

图1.9 仿射变换图示
1.4非方阵线性变换:奇异值分解
作为矩阵的分解算法,特征值分解最主要的缺陷在于它只能应用于方阵。非方阵情况下的矩阵分解算法,比较有代表性的是奇异值分解(SVD)。
(1.36)

SVD的求解过程可以用特征值分解进行,这就需要将矩阵转换为方阵。
(1.37)

对B进行特征值分解,利用对应元素相等可以得到如下关系。
(1.38)

根据式(1.36)可以得到M的值如下。
(1.39)

由此3个矩阵已经完全确定。因此,有人说矩阵的特征值分解是SVD的基础。同时可以看到,矩阵A在变换为矩阵M的过程中,相当于对矩阵A进行一次线性变换。
1.5其他线性变换:字典学习
对于SVD分解而言,有一个非常大的问题就是约束过于严格,如矩阵与V为正交矩阵,这就导致在计算的过程中,为了满足分解条件,信息压缩的质量可能会降低。因此,产生了另外一个更加宽泛的约束方式.
(1.40)

假设条件N足够稀疏,此时M就称为字典。在这种情况下弱化了正交性假设,所得到的信息压缩效果会更加出色。
本文节选自《深度学习算法与实践》

本书旨在为读者建立完整的深度学习知识体系。全书内容包含3个部分,第一部分为与深度学习相关的数学基础;第二部分为深度学习的算法基础以及相关实现;第三部分为深度学习的实际应用。通过阅读本书,读者可加深对深度学习算法的理解,并将其应用到实际工作中。 本书适用于对深度学习感兴趣并希望从事相关工作的读者,也可作为高校相关专业的教学参考书。
,




