案例数据
在“工资影响因素”的调查问卷中,调查了每个人的起始工资、工作经验、受教育年限、受雇月数、职位等级以及当前工资六个方面。
分析目的
目的是建立以当前工资为因变量的回归模型,并得出结论。[案例来源于:SPSS统计分析(第5版)卢纹岱,朱红兵主编,案例有一些变动 具体请看分析。]
二、数据清理在数据分析之前,首先需要进行数据查看,包括数据中是否有异常值,无效样本等。如果有异常值则需要进行处理,然后再进行分析。另外如果数据中有无效样本也需要进行处理后再进行分析。无效样本会干扰分析研究,扭曲数据结论等,因而在分析前先对无效样本进行标识显示尤其必要。异常值的鉴别与处理一般分为三个部分,其中分别是判断标准,鉴别方法以及异常值的处理,以下从这三个方面进行说明。
异常值的判断标准如下:

检验数据是否有异常值的方法:

异常值处理方法:

此案例对于异常值参照的标准为大于±3个标准差

使用描述分析进行查看发现没有异常值。


除了对异常值处理外,还需要对于无效样本的检查:如果数据来源为问卷,则很可能出现无效样本,因为填写问卷的样本是否真实填写无从判定;如果数据库下载或者使用二手数据等,也可能出现大量缺失数据等无效样本。以下从无效样本场景、SPSSAU设置标准、处理三方面进行说明。
1.常见场景

2.设置标准

3.无效样本的处理
设置好无效样本后,默认会新生成一个标题,用来标识那些样本是有效,那些是无效,在分析的时候直接进行筛选下就好。

本次案例分析将以相同数字大于70%为标准进行检验,结果显示没有无效样本。

散点图
做数据的散点图,观察因变量与自变量之间是否具有线性特点。

从上图中可以看出,当前工资和起始工资、受教育年限、职位等级以及工作经验均存在线性关系,其中Y轴为因变量当前工资,X轴为自变量,但是从图中观察到对于“起始工资和当前工资”及“工作经验和当前工资”可能存在异常值,进行数据复查后发现,数据均在可接受范围内,所以不进行处理。
相关性分析
相关分析是研究有没有关系,回归分析是研究影响关系。明显地,相关分析是基础,然后再进行回归分析。首先需要知道有没有相关关系;有了相关关系,才可能有回归影响关系;如果没有相关关系,是不应该有回归影响关系的。

从上表可知,利用相关分析去研究当前工资和受教育年限, 职位等级, 起始工资, 工作经验共4项之间的相关关系,使用Pearson相关系数去表示相关关系的强弱情况。具体分析可知:
当前工资与受教育年限, 职位等级, 起始工资, 工作经验共4项之间的相关关系系数值呈现出显著性。具体分析请看SPSSAU智能分析:

F检验

从上表可以看出,离差平方和为1461615.460,残差平方和为579191.966,而回归平方和为882423.494。回归方程的显著性检验中,统计量F=178.635,对应的p值远远小于0.05,被解释变量的线性关系是显著的,可以建立模型。建立模型后,需要查看模型拟合优度是否可以,其中就可以查看R方与调整R方值。
R方和调整R方

从上表可知,将起始工资,受教育年限,职位等级,工作经验作为自变量,而将当前工资作为因变量进行线性回归分析,从上表可以看出,模型R方值为0.604,调整R方为0.600,其中R方是决定系数,模型拟合指标。反应Y的波动有多少比例能被X的波动描述。调整R方也是模型拟合指标。当x个数较多是调整R比R更为准确。意味着起始工资,受教育年限,职位等级,工作经验可以解释当前工资的60.4%变化原因。可见,模型拟合优度较好,说明被解释变量可以被模型解释的部分较多。接下来查看变量是否具有多重共线性。
VIF值

VIF值用于检测共线性问题,一般VIF值小于10即说明没有共线性(严格的标准是5),有时候会以容差值作为标准,容差值=1/VIF,所以容差值大于0.1则说明没有共线性(严格是大于0.2),VIF和容差值有逻辑对应关系,因此二选一即可,一般描述VIF值。在【线性回归】分析时,SPSSAU会智能判断共线性问题并且提供解决建议。 结果中可以看出,变量的VIF值均小于5,所以此案例不存在多重共线性的问题。
但是如果存在多重共线问题,建议三种解决方法一是使用逐步回归分析(让模型自动剔除掉共线性过高项);二是使用岭回归分析(使用数学方法解决共线性问题),三是进行相关分析,手工移出相关性非常高的分析项(通过主观分析解决),然后再做线性回归分析。
DW值
D-W值也称Durbin-Watson值,一般对于时间序列分析才会考虑DW值:
-
当残差与自变量互为独立时,DW≈2;
-
当相邻两点的残差为正相关时,DW<2;
-
当相邻两点的残差为负相关时,DW>2;
AIC和BIC
最后针对模型中的AIC值与BIC值说明如下:
AlC值是衡量统计模型拟合优良性的一种标准,AIC越小,模型越好。BIC值一可有效防止模型精度过高造成的模型复杂度过高。接下来对模型结果进行一一分析。
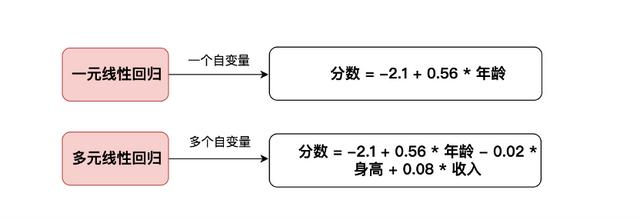
五、模型结果模型公式

从上表可知,将起始工资,受教育年限,工作经验,职位等级作为自变量,而将当前工资作为因变量进行线性回归分析,从上表可以看出,模型公式为:当前工资=-41.634 0.425*起始工资 6.176*受教育年限-0.051*工作经验 29.819*职位等级。
回归系数

上图所示,回归方程的常数项约为-41.63,以及起始工资、受教育年限、工作经验以及职位等级的非标准化系数分别为0.425、6.176、-0.051、29.819。表中4个变量的p值均小于0.05,并且VIF值均正常,因此4个变量可以显示在模型中。
coefPlot

coefPlot展示具体的回归系数值和对应的置信区间,可直观查看数据的显著性情况,如果说置信区间包括数字0则说明该项不显著,如果置信区间不包括数字0则说明该项呈现出显著性。所以上图中四个分析项的置信区间都不包括0,都呈现显著性。
标准化系数
起始工资、受教育年限、工作经验以及职位等级的标准化系数分别为0.163、0.320、-0.096、0.415. 标准化系数一般可用于比较自变量对Y的影响程度。系数值越大说明该变量对Y的影响越大。可以看出模型中职位等级对当前工资影响较大。
模型预测-预测因变量

总结来看,模型公式为:当前工资=-41.634 0.425*起始工资 6.176*受教育年限-0.051*工作经验 29.819*职位等级(案例数据分析结果仅供参考)。
残差图

上图为残差正态分布图(P-P图),由上图可以看出残差的分布符合大致正态分步。说明回归结果就数据而言是较为可靠的。
六、模型综述通过数据清理发现数据适合做回归分析,然后对模型进行分析与总结。,比如多重共线性等,经过分析,得到起始工资、工作经验、受教育年限、受雇月数、职位等级4个自变量以及当前工资因变量之间的关系,对预测模型进行分析。回归分析不只是线性回归,还包括曲线回归、非线性回归等,这些知识的学习还需要大家进行查看相关资料自行摸索。
,