上上篇文章我们谈到阅读活动一定要以自我为中心,只有自己心中好奇的问题驱动,阅读才会变得好玩、有意义。这篇文章我将讨论如何利用软件辅助阅读,尽力让技术型阅读变成一件令人愉悦的事。
目录
一,什么是技术型阅读概述之,一页页翻书就是传统阅读,利用软件选择自己需要的部分观看,就是技术型阅读。传统阅读就好像蹩脚侦探“地毯式”的逐级排查,而技术型阅读则是福尔摩斯对信息的快速侦测。可以畅想,假如未来计算机能够直接为你定位到需要阅读的板块,那么寻找答案是不是更加简单呢?其实我们已经能够初步做到这一点,只是很多人还在坚守传统阅读的习惯罢了。信息爆炸时代阅读本身便稀缺,如果再一味死读书,终究会落后于时代。因此我想普及有关“半机械化”阅读的经验,让大家也了解到利用软件进行阅读的好处。其实,用软件里的“关键词”在书中检索“答案”,比“方读此,勿慕彼”的笨办法好太多。技术扩展了人类的能力边界,使我们能够比以前读到更多书籍、学到更多知识。
二,OCR 光学字符识别纸质书虽有更好的阅读体验,但寻找答案时却相当麻烦。于技术型阅读而言,电子书自然是唯一选择。很多小伙伴好奇哪种电子书格式最好,个人觉得没有定论。EPUB、MOBI、AZW3、PDF,各有优缺点,根据自己需要选择适合自己的就好。这里我主要想讨论扫描版PDF电子书,理由是:扫描版PDF虽然不支持检索,但格式排版和纸质书一样,十分方便引用,也可以找到同版纸书。只要弥补扫描版PDF不能检索的缺陷,阅读效率就会大大提高。事实上,OCR 即解决扫描PDF书籍检索问题的最佳方案。
维基词条对OCR的解释如下:
光学字符识别(英语:Optical Character Recognition,OCR)是指对文本资料的图像文件进行分析识别处理,获取文字及版面信息的过程。
简单讲,平常我们看到的、可以复制粘贴的知网文献都是OCR技术处理后的双层PDF文件;而那些不能复制、粘贴的扫描版电子书则是没有经过OCR处理、十分孤单的单层PDF文件。换言之,单层PDF在计算机眼中就是一张张图片,只有它变成双层PDF,计算机才能识别沉在图片下层的文字信息。所以,要想实现扫描版PDF的检索功能,就必须用OCR为这个孤单的单层PDF找个对象,让它变成含有文字、排版信息的双层PDF。
OCR软件推荐:PDFelement选择这款软件的原因是它可以全平台使用,且价格喜人。老牌国际大厂的OCR软件动不动就上千,PDFelement只卖三百简直是个小清新(大家最好支持正版哦)。唯一缺点是它OCR的速度较慢,耐心等等就好。下面两张图片我标出了OCR功能在Mac平台和 Windows平台的界面布局,方便萌新初次上手。
Mac 平台
Win 平台
温馨提示:OCR处理后的电子书一定要固定放在某个文件夹中,最好找个云同步盘。不然处理完随手一丢,之后的阅读活动会变得异常艰难。大家肯定也想省心省力对吧?所以平常要养成良好的习惯,定期整理,以后查找资料时会便捷很多。
三,简单检索大家不难发现,OCR之后,书籍的维度就被打开了。只要我们拿着关键词去询问书籍,书籍就能给出比之前无目的阅读精确很多的答案。好比我们翻看《单向度的人》,却只好奇马尔库塞(德:Marcuse)关于“传播”的论述,那么无需把整个书本折腾一遍也能快速找到相关段落。
查找功能
如上图所示,在查找框键入“传播”,即可定位书中所有“传播”的位置,这时我们进行阅读就好。不过千万记得:务必联系上下文,否则看一些艰深书籍很容易断章取义。毕竟,我们的方法只是为了提高效率,而不是投机取巧。实打实的阅读才能为自己带来收益。
四,全盘检索如果你是经常阅读的熟手,很快会察觉到“简单检索”的局限。从知识维度看,“简单检索”虽然有效,但是只聚焦于一本书籍,无法实现书籍网络之间的联动。因此我们需要一款像X光一样透视全部书籍文本的工具,只有这种工具才能满足进阶用户的要求。我费了一番功夫,总算在Mac平台和Windows平台分别找到的两款还算好用的全盘检索软件,推荐给你:
PDF Search这是Mac平台的PDF全盘检索软件,非常适合进阶读者中要求不高的群体。它的操作逻辑十分简单,只要先把所有藏书输入其中、做个索引,再用关键词检索即可。它会将全部书籍中所有包含关键词的信息加以标注,并在打开文件时生成动画引导读者注意。
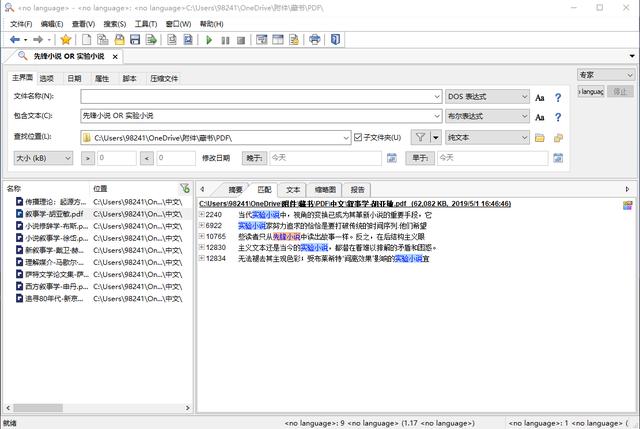
下面我用“先锋小说”做个示范:
可以看到,全部书籍里的“先锋小说”都被检索出来了,甚至按照级别排了序。虽然我并不是很懂这个排序逻辑,但使用时也没产生太大困扰。假如你的书籍特别多,这个软件还可以给书籍标签。如此一来,软件检索时会排除掉你不需要的书籍类目,十分方便。但是,任何事物都不可能完美,它也有不少缺点,尤其对中文支持较差,大致只能做到不影响使用的程度。颜值党可以考虑购买。
FileLocator ProWindows平台的神器,比上面那个好用多了,缺点是长得比较丑。它可以快速检索本地的PDF文件,并为用户提供文内信息的预览。其基础检索功能如下:
直接查询
和PDF Search的基础检索别无二致,唯一区别就在于索引方式不同。不过,你要深度使用这款软件才能体会它的强大之处,仅一个布尔表达式就已经可以将它称为神器。下面我用具体场景给大家展示一下布尔表达式的使用。
四,专家检索
布尔算符表
AND 语法
“A主题和B主题我都要”,软件会检索同时出现AND两边词语的内容。这是最基础的语法,能够有效缩小检索范围。在实际使用中,全文检索的效果一般,主要适用于书籍标题的检索。好比想找索绪尔(法:Saussure)关于语言学的书籍,但忘了具体书名,那么可以用AND语法来查找:
NOT 语法
“我不要A主题”。基本功能是排除已知不需要的主题,缩小检索范围。在书籍少的时候不推荐使用,只有当书籍数量庞大,难以筛选之时,NOT语法才能帮上忙。例如需要了解“叙事”相关主题,但又不想涉及到电影叙事,可以在NOT之后接“影视”、“电影”加以排除:
OR 语法
“A主题和B主题都给我看看”。基本功能是扩大检索范围,适合不明确主题具体用词或多个主题的情况。如“实验小说”和“先锋小说”内涵相近,但不知道书中到底用这两个关键词中的哪个。此时可以用OR语法连接类似的关键词,避免遗漏:
NEAR 语法
“A主题下的B话题我有兴趣”。基本功能是缩小全文查找范围,适用于查找某个主题下的具体话题。例如想找“马原”写的“先锋小说”。可以用NEAR语法表达:
需要注意,NEAR之前的关键词才是搜索的重心。换言之,“马原”只是辅助定位“先锋小说”的一个路标。
LIKE 语法
“比较像A主题的都帮我查查”。基本功能是模糊搜索,适用于某个主题术语有变形的情况。好比键入“先锋小说”,也能检索到“先锋派小说”:
五,小结
总之,无论是完全不需要学习的简单检索,还是拥有较复杂逻辑的专家检索,都能给我们读者带来切实的效率提升。我认为在未来通过软件理解书籍将是现代人的必须掌握的技能。书籍本质是知识,而知识本质是网络。技术型阅读可以从宏观角度把握知识网络的组建,同时,也能够提高读者的主动性,拒绝被动读书的不良习惯。事实上,越从技术角度解构书籍,越是会动用到大脑中的复杂策略,大家可以想一想游戏是不是因为玩家可以运用复杂策略才有了可玩性?书籍其实是一样的道理:接受沉闷的阅读,结果就是头脑闭塞;检索、思考、玩着去阅读,会越来越精于此道。
,