作者:Jonathan Howe, James Skinner
编译:ronghuaiyang
导读
旋转框相比矩形框可以更好的拟合物体,同时标注起来比分割要方便的多,使用来自NVIDIA的ODTK可以方便的训练,实施和部署旋转框物体检测模型,同时具备多种扩展功能。
图1,国际遥感和摄影测量学会(ISPRS)波茨坦数据集,使用分割掩码标签计算的车辆的旋转包围盒显示为绿色。
利用深度神经网络(DNNs)和卷积神经网络(CNNs)对图像进行目标检测和分类是一个研究很广泛的领域。对于一些应用,这些人工智能方法被认为是足够可靠的,在生产中使用基本不需要干预。流行的方法包括YOLO、SSD、Faster-RCNN、MobileNet、RetinaNet等。
在大多数应用环境中,图像是从一个以自己为中心的视角收集的(比如手机摄像头),大多数目标是垂直对齐的(一个人)或水平对齐的(一辆车)。这意味着图像中的大部分物体可以认为是轴向的,可以用四个包围框参数来描述:xmin、ymin、width和height。
但是,在许多情况下,物体或特征不与图像轴对齐。在这种情况下,这四个参数不能很好地描述物体轮廓。
图2,两个COCO的验证图像。轴对齐框(a)包含了很多天空。旋转框(b)更适合
例如,尝试使用四个边界框参数来描述一个旋转了45度的正方形。边界框的面积是你试图描述的正方形面积的两倍。自己计算一下吧!
对于矩形物体,或者任何高长宽比的物体(又高又瘦,又矮又胖),差别甚至更大。因此,需要一个额外的参数来减少目标的面积和描述它的边界框之间的差异, 物体相对于垂直轴的角度,θ 。现在你可以用xmin,ymin,width,height和θ来描述一个目标的边框。
在现实世界中,有些目标不能被描述为一个简单的矩形,需要更多的参数。添加角度参数有助于描述其位置和轮廓,比轴对齐框更精确。
图3,ODTK检测旋转框的例子。轴对齐的ground truth框(a)相互重叠,每个框都是(person和motorcycle)的混合。ODTK (b)检测到的旋转框解决了这个问题,并且更好地拟合了目标的轮廓。
旋转物体和特征的检测的应用包括遥感(图1)、 “in the wild” 文本检测、医学和工业检测。当你使用轴对齐的边框来训练模型背景时,每个旋转的目标都会包含一些特征,从而降低了模型从背景图像中区分感兴趣的目标的能力。此外,如果目标是近距离的,例如停车场的汽车,背景和附近的目标也包括在目标实例中。
其结果是,当一群目标中存在相同或类似类别时,检测器可能会高估或低估目标的数量。对于依赖于精确值的应用,这显然不是最优的。旋转框可以缓解这些问题,并提供更高的精度和召回率。例如,图3中围绕人物的轴对齐框包含了很多天空和一些摩托车。旋转框里包含了更少的天空和几乎没有摩托车。
旋转目标检测模型和方法常用的检测旋转物体的DNN方法可分为两类:
- 从分割蒙版计算旋转框
- 直接推断旋转框
对于第一种方法,分割掩模通常使用Mask-RCNN计算,这是一个基于Faster-RCNN的网络,在分类和轴对齐的包围框之外还有一个额外的分割头。与Faster-RCNN一样,Mask-RCNN是一个两级检测器,它能推断出建议区域,然后在检测结果中细化。
虽然这种方法可以对轴对齐目标进行高精度的推断,但这种两阶段方法的性能(每秒处理图像)相对较低。此外,使用推断分割掩模计算旋转的包围框,通常使用后处理和OpenCV等标准包,会产生不准确和虚假的结果。
第二种方法,直接推断旋转框,更有吸引力。与分割掩码方法不同,不需要增加低效率和通常会降低精度的后处理。另外,大多数直接推断旋转框的方法都是单阶段检测器,而不是像Faster-RCNN这样的多阶段检测器。
关于这个主题的学术论文很少,公开的repos就更少了。为了在一次检测中推断旋转框,许多技术依赖于比较ground truth和锚(有时称为先验框)。对于轴对齐的检测器,锚的大小、长宽比和比例在进行训练之前由用户定义。
训练期间,如果计算的anchor框和gt框之间的IOU高于0.5,那么这个anchor就用来回归这个和这个gt之间的差别(Δxmin,Δymin,Δwidth,Δheight)。对于轴对齐框,IoU计算非常简单,可以使用NVIDIA GPU以端到端方式加速。下面的PyTorch例子显示了轴对齐框和anchor之间IoU的计算:
inter=torch.prod((xy2-xy1 1).clamp(0),2) boxes_area=torch.prod(boxes[:,2:]-boxes[:,:2] 1,1) anchors_area=torch.prod(anchors[:,2:]-anchors[:,:2] 1,1) overlap=inter/(anchors_area[:,None] boxes_area-inter)在这个代码示例中:
- boxes是ground truth的注解
- anchors是锚框
- xy2 和 xy1 分别是标注框和anchor中左上角最大的和右下角最小的角的坐标
- inter是boxes 和anchors的重叠区域面积
- boxes_area和anchors_area分别是ground truth和锚框的面积
- overlap是IoU
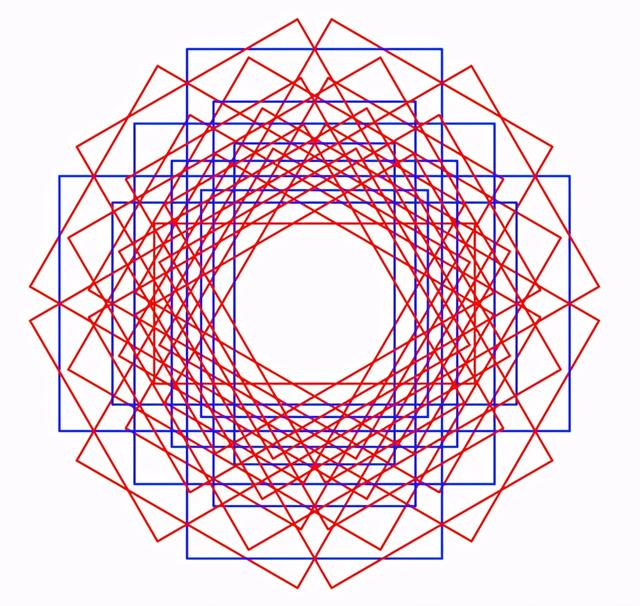
对于旋转框,情况就不同了。首先,为额外的参数angle指定一个或多个值,这增加一个anchor的参数。图4显示了图像特征空间中的单个位置上轴对齐的锚框(蓝色),具有三种比例和三种纵横比。旋转的锚框(红色和蓝色)在三个旋转角度上使用相同的比例和长宽比来显示:-π/6, 0 and π/6其次,最重要的是,IoU的计算不能像前面所示的轴对齐框那样简单地进行。
图4,轴对齐锚框(蓝色),旋转的锚框(红色和蓝色),旋转角度:-π/6, 0和π/6
旋转框的IOU计算
图5,两个旋转矩形的重叠区域为多边形。
图5显示了旋转框交叉点要比轴对齐的框交叉点复杂得多。当两个旋转框重叠时,会构建出一个新的多边形(不一定是四边形),由红色和绿色的顶点描述。红色的顶点表示两个框的边相交的地方,而绿色的顶点包含在两个框内。你必须能够为所有的框都计算出这些点,然后执行IoU计算。
大多数论文依赖于框的光栅化(例如,创建一个图像或mask)来计算这个新的多边形,然后计算IoU。这是一种低效且不准确的方法,因为框所占据的空间必须离散化以进行所有的比较。需要使用精确的分析解决方案来最大化效率和准确性。
为了解决这个问题,我们转向几何方法,顺序切割是一种递归方法,使用一个比较框定义初始多边形。对于每条边,它计算与第二个被比较框的边是否有交集。如果是这样,这些顶点就会被保留下来,并形成新的边,然后这些边会再次与被比较的方框进行比较,直到没有边剩下为止。伪代码如下:
intersectionoftworotatedboxes/polygons(p1,p2): 1.Initializethebox_intersection,settingitastheverticesofp1. 2.Foreachedge(specifiedbythelineequationax by c=0)ofp2,findlineintersectionwithboxintersectionusinghomogeneouscoordinateswhere; intersectionx=(p1.b*p2.c-p1.c*p2.b)/w intersectiony=(p1.c*p2.a-p1.a*p2.c)/w where;w=p1.a*p2.b-p1.b*p2.a 2a.Ifintersectionoccursontheedge,addittotemp_intersection. 2b.Ifintersectionoccurswithintheboundaryoftwoedgecalculations,addittotemp_intersection. 3.Setbox_intersection=temp_intersection. 4.Repeatfrom2.untilnomoreedges.如果在比较两个框时存在一个有两条边以上的多边形,现在可以计算IoU,否则,IoU为零。再一次,为精确计算,其中不规则多边形的面积是由以下公式给出:
然后,IoU通过分割多边形区域来计算,正如前面计算的框和锚的区域的IoU。
与与之对应的轴对齐方法相比,这种递归方法更加复杂。但是,与光栅化框和锚相比,它的计算要求更少,也不那么麻烦。
IoU必须在每幅图像上计算,因为它是通过DNN前向传播的。在训练过程中,IoU用于度量损失,在推理过程中,IoU需要进行非最大抑制(NMS)。因此,函数必须尽可能快。
这是通过使用grid-striding在CUDA core的多个GPU线程上并行地进行每次比较来实现的。
Grid-striding可以让你在GPU设备上以灵活的方式并行执行这些计算,而不是按顺序计算所有的ground truth box到anchor box的比较(每个图像batch的计算量从100ks到数百万)。
图6展示了在CUDA core(绿色条)上的实现和在cpu上执行顺序计算(蓝色条)时的加速图。CUDA core比Python提供了10k的加速,比PyTorch提供了100k的加速,比c 提供了500的加速。这个图没有考虑GPU到CPU之间的数据传输时间,如果旋转IoU计算在GPU设备上在模型训练期间执行。在训练和推断过程中,将所有的数据和计算都保存在GPU上,这进一步增加了GPU和CPU性能的差异,如图6所示。
图6,旋转IoU计算比较20个目标框和900个锚框。CPU = 1x Xeon(R) CPU E5-2698 v4 @ 2.20GHz, GPU = 1x NVIDIA V100 16gb
IoU计算好了之后,如果绝对角度不是必需的,你可以最小化(Δxmin, Δymin, Δwidth, Δheight, Δθ)。如果绝对角度和方向需要已知(文本框取向、车辆方向/轴承等等),这些信息在gt中是一致的,可以最小化(Δxmin, Δymin, Δwidth, Δheight, Δsin(θ), Δcos(θ)),捕获绝对角度差异的θ投影到单位圆上。
所有特性(轴对齐和旋转框检测)在NVIDIA物体检测工具包:https://github.com/NVIDIA/retinanet-examples (ODTK)中都可以使用。
使用ODTKNVIDIA拥有一套丰富的工具来加速目标检测模型的训练和推断。开源ODTK是一个如何同时使用所有这些工具的例子。使用RetinaNet演示检测pipeline是作为现代物体检测器的一个很好的例子。
ODTK演示了如何集成5个NVIDIA工具:
准备数据
- Mixed precision training,我们在FP32保留一个网络权重的主副本,但我们在FP16计算更新每批。这使得训练时的速度提高了3倍。我们使用NVIDIA APEX库实现自动混合精度(AMP)。
- NVIDIA数据加载库 (DALI)将预处理(图像resize和归一化)移动到GPU。这可以将训练和推理速度提高到1.2到1.5倍,这取决于你选择哪种骨干。
- NVIDIA TensorRT 创建高度优化的推理引擎,在FP32, FP16,和INT8精度上都可以使用。这些引擎可以在推理期间提供显著的加速(比如5x)。ODTK还可以生成ONNX文件,提供更大的框架灵活性。
- NVIDIA DeepStream SDK 是英伟达智能视频分析解决方案(IVA)。它是非常高效的,因为DeepStream将视频数据的整个pipeline保持在GPU中。NVIDIA提供了一个解析器,以便可以在DeepStream pipeline中使用ODTK推理引擎(使用TensorRT生成)。
- NVIDIA Triton Inference Server是TensorRT模型的另一种服务方式。Triton推断服务器可以注册ODTK PyTorch、ONNX和TensorRT模型,Triton客户端可以请求该服务器。如果你使用静态图像而不是视频流,此方法可能更适合。
ODTK使用COCO目标检测格式,但我们修改了边框,使其包含theta参数。首先使用[xmin, ymin, width, height]参数构建边框(图7,左)。然后,将框逆时针旋转theta 弧度,在本例中为-0.209。如果旋转的方框包含了图片框之外的区域,没有关系。
图7,首先创建一个轴对齐的框(左),然后旋转(右)来构造边界框
许多数据集(例如COCO和ISPRS)都带有分割掩码。这些掩码可以转换为旋转框。
使用shapely minimum_rotated_rectangle函数创建旋转矩形,并将四个角输入函数以生成边框值。calc_bearing是一个用arctan求θ的简单函数。你必须把函数封装起来以确保w和h是正的,并且theta在-pi/2到pi/2或者-pi到pi的范围内。
训练,推理,导出ODTK模型
def_corners2rotatedbbox(corners): centre=np.mean(np.array(corners),0) theta=calc_bearing(corners[0],corners[1]) rotation=np.array([[np.cos(theta),-np.sin(theta)], [np.sin(theta),np.cos(theta)]]) out_points=np.matmul(corners-centre,rotation) centre x,y=list(out_points[0,:]) w,h=list(out_points[2,:]-out_points[0,:]) return[x,y,w,h,theta]ODTK位于最新的NVIDIA NGC PyTorch容器中。这确保安装了正确版本的PyTorch和其他先决条件。
gitclonehttps://github.com/nvidia/retinanet-examples dockerbuild-todtk:latestretinanet-examples/ dockerrun--gpusall--rm--ipc=host-it-v/your/data/dir:/dataodtk:latest现在,训练ODTK用于旋转检测。在这篇文章中,我们使用了ResNet50PFN主干。下面的命令每7000次迭代生成一个验证分数。
odtktrainmodel.pth--backboneResNet50FPN\ --images/data/train/--annotations/data/train.json\ --val-images/data/val--val-annotations/data/val.json--rotated-bbox你可以使用PyTorch来推理模型:
odtkinfermodel.pth--images/data/test--outputdetections.json但是,如果首先导出到TensorRT(这里是FP16),可以获得更快的推断性能,但是INT8精度也可用。
odtkexportmodel.pthengine.plan你可以使用odtk推断命令、Triton服务器或编写一个c 推断应用程序进行推断。
表1,对80个类COCO的各种主干的推断延迟和吞吐量,图像大小调整(resize)设置为800,批处理大小(batch)设置为1。轴对齐和旋转框模型延迟和吞吐量之间的差异可以忽略不计
对比例子
图8,轴对齐模型(左)和旋转框模型(右)的推断框(红色)和gt框(绿色)
图8显示了在ISPRS波茨坦数据集上训练的轴对齐和旋转框模型的例子,这些例子是从在使用ResNet18主干的COCO数据集上预训练的轴对齐模型上进行微调的。这两个模型在相同的训练和验证数据集上进行训练直到收敛(90k迭代)。
从推理图像可以看出,旋转模型比轴对齐模型更符合ground truth。当使用轴对齐模型时,会出现每辆车有多个检测结果的情况,但对于旋转框模型则不是这样。
与轴对齐模型相比,旋转框模型获得了更高的平均IoU:0.60对0.29。由于轴对齐模型得到的IoU较低,IoU≥0.5时的标准COCO平均精度计算值在模型之间存在差异:0.86和0.01。你必须为这个比较使用一个更公平的度量,一个可以用来比较推断的结果与ground truth框的匹配程度的度量。
在这篇文章中,我们使用了在Cityscapes dataset challenge中定义的实例级语义标记度量。精度和召回率是按类和像素级别计算的。当使用这些指标时,旋转模型的精度和召回率分别为0.77和0.76,轴对齐模型的精度和召回率分别为0.37和0.55。旋转检测比轴对齐模型可以更清楚地匹配ground truth。
表2,使用ISPRS波茨坦数据集建模时,将轴对齐模型与旋转框模型的实例级精度、召回率和F1得分进行比较
总结可以尝试使用ODTK检测自己数据集中的旋转目标。你会发现它直接训练,验证,实施,并提供模型服务,最大话GPU资源的效率。并持续为高性能,端到端掩模训练和推理,多边形检测,和高效的多目标跟踪集成进行调优。
英文原文:https://developer.nvidia.com/blog/detecting-rotated-objects-using-the-odtk/
更多内容,请关注微信公众号“AI公园”。
,