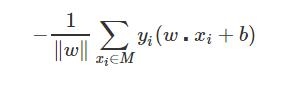前面章节尝试了K均值聚类模型,准确率并不高。接下来我们尝试一种新方法:支持向量机(SVM)。
支持向量机
支持向量机(support vector machine/SVM),通俗来讲,它是一种二类分类模型,其基本模型定义为特征空间上的间隔最大的线性分类器,其学习策略便是间隔最大化,最终可转化为一个凸二次规划问题的求解。本系列教程聚焦于SciKit-Learn 库的使用介绍,关于支持向量机详细原理,限于篇幅不再赘述,读者可参考相关资料。
如前所诉,K均值聚类模型是一种无监督学习模型,与此不同,支持向量机是一种有监督学习模型,是很常用的一种机器学习模型。
创建模型下面的代码,创建了一个支持向量机模型。
import numpy as np from sklearn import datasets # 加载 `digits` 数据集 digits = datasets.load_digits() # 导入 `train_test_split` from sklearn.model_selection import train_test_split # 数据分成训练集和测试集 # `test_size`:如果是浮点数,在0-1之间,表示测试子集占比;如果是整数的话就是测试子集的样本数量,`random_state`:是随机数的种子 X_train, X_test, y_train, y_test, images_train, images_test = train_test_split(digits.data, digits.target, digits.images, test_size=0.33, random_state=42) # 导入“svm”模型 from sklearn import svm # 创建SVC/Support Vector Classification/支持向量机分类器模型 svc_model = svm.SVC(gamma=0.001, C=100., kernel='linear') # 将数据拟合到SVC模型中,此处用到了标签值y_train,是有监督学习 svc_model.fit(X_train, y_train)可以看到,我们使用X_train和y_train数据来训练SVC模型(Support Vector Classification/支持向量机分类器模型),此处用到了标签值y_train,是有监督学习。
另外,我们手动设置了gamma的值,通过使用网格搜索和交叉验证等工具,可以自动找到合适的参数值。
测试模型接下来,我们使用测试数据测试模型。
# 预测“X_test”标签 print(svc_model.predict(X_test)) # 打印' y_test '检查结果 print(y_test)输出:
[6 9 3 7 2 1 5 2 5 2 1 4 4 0 4 2 3 7 8 8 4 3 9 7 5 6 3 5 6 3 4 9 1 4 4 6 9 4 7 6 6 9 1 3 6 1 3 0 6 5 5 1 9 5 6 0 9 0 0 1 0 4 5 2 4 5 7 0 7 5 9 5 5 4 7 0 4 5 5 9 9 0 2 3 8 0 6 4 4 9 1 2 8 3 5 2 9 0 4 4 4 3 5 3 1 3 5 9 4 2 7 7 4 4 1 9 2 7 8 7 2 6 9 4 0 7 2 7 5 8 7 5 7 9 0 6 6 4 2 8 0 9 4 6 9 9 6 9 0 5 5 6 6 0 6 4 3 9 3 9 7 2 9 0 4 5 3 6 5 9 9 8 4 2 1 3 7 7 2 2 3 9 8 0 3 2 2 5 6 9 9 4 1 5 4 2 3 6 4 8 5 9 5 7 8 9 4 8 1 5 4 4 9 6 1 8 6 0 4 5 2 7 4 6 4 5 6 0 3 2 3 6 7 1 5 1 4 7 6 5 8 5 5 1 6 2 8 8 9 9 7 6 2 2 2 3 4 8 8 3 6 0 9 7 7 0 1 0 4 5 1 5 3 6 0 4 1 0 0 3 6 5 9 7 3 5 5 9 9 8 5 3 3 2 0 5 8 3 4 0 2 4 6 4 3 4 5 0 5 2 1 3 1 4 1 1 7 0 1 5 2 1 2 8 7 0 6 4 8 8 5 1 8 4 5 8 7 9 8 5 0 6 2 0 7 9 8 9 5 2 7 7 1 8 7 4 3 8 3 5 6 0 0 3 0 5 0 0 4 1 2 3 4 5 9 6 3 1 8 8 4 2 3 8 9 8 8 5 0 6 3 3 7 1 6 4 1 2 1 1 6 4 7 4 8 3 4 0 5 1 9 4 5 7 6 3 7 0 5 9 7 5 9 7 4 2 1 9 0 7 5 8 3 6 3 9 6 9 5 0 1 5 5 8 3 3 6 2 6 5 7 2 0 8 7 3 7 0 2 2 3 5 8 7 3 6 5 9 9 2 9 6 3 0 7 1 1 9 6 1 8 0 0 2 9 3 9 9 3 7 7 1 3 5 4 6 1 2 1 1 8 7 6 9 2 0 4 4 8 8 7 1 3 1 7 1 8 5 1 7 0 0 2 2 6 9 4 1 9 0 6 7 7 9 5 4 7 0 7 6 8 7 1 4 6 2 8 7 5 9 0 3 9 6 6 1 9 1 2 9 8 9 7 4 8 5 5 9 7 7 6 8 1 3 5 7 9 5 5 2 4 1 2 2 4 8 7 5 8 8 9 4 9 0] [6 9 3 7 2 1 5 2 5 2 1 9 4 0 4 2 3 7 8 8 4 3 9 7 5 6 3 5 6 3 4 9 1 4 4 6 9 4 7 6 6 9 1 3 6 1 3 0 6 5 5 1 9 5 6 0 9 0 0 1 0 4 5 2 4 5 7 0 7 5 9 5 5 4 7 0 4 5 5 9 9 0 2 3 8 0 6 4 4 9 1 2 8 3 5 2 9 0 4 4 4 3 5 3 1 3 5 9 4 2 7 7 4 4 1 9 2 7 8 7 2 6 9 4 0 7 2 7 5 8 7 5 7 7 0 6 6 4 2 8 0 9 4 6 9 9 6 9 0 3 5 6 6 0 6 4 3 9 3 9 7 2 9 0 4 5 3 6 5 9 9 8 4 2 1 3 7 7 2 2 3 9 8 0 3 2 2 5 6 9 9 4 1 5 4 2 3 6 4 8 5 9 5 7 8 9 4 8 1 5 4 4 9 6 1 8 6 0 4 5 2 7 4 6 4 5 6 0 3 2 3 6 7 1 5 1 4 7 6 8 8 5 5 1 6 2 8 8 9 9 7 6 2 2 2 3 4 8 8 3 6 0 9 7 7 0 1 0 4 5 1 5 3 6 0 4 1 0 0 3 6 5 9 7 3 5 5 9 9 8 5 3 3 2 0 5 8 3 4 0 2 4 6 4 3 4 5 0 5 2 1 3 1 4 1 1 7 0 1 5 2 1 2 8 7 0 6 4 8 8 5 1 8 4 5 8 7 9 8 5 0 6 2 0 7 9 8 9 5 2 7 7 1 8 7 4 3 8 3 5 6 0 0 3 0 5 0 0 4 1 2 8 4 5 9 6 3 1 8 8 4 2 3 8 9 8 8 5 0 6 3 3 7 1 6 4 1 2 1 1 6 4 7 4 8 3 4 0 5 1 9 4 5 7 6 3 7 0 5 9 7 5 9 7 4 2 1 9 0 7 5 3 3 6 3 9 6 9 5 0 1 5 5 8 3 3 6 2 6 5 5 2 0 8 7 3 7 0 2 2 3 5 8 7 3 6 5 9 9 2 5 6 3 0 7 1 1 9 6 1 1 0 0 2 9 3 9 9 3 7 7 1 3 5 4 6 1 2 1 1 8 7 6 9 2 0 4 4 8 8 7 1 3 1 7 1 9 5 1 7 0 0 2 2 6 9 4 1 9 0 6 7 7 9 5 4 7 0 7 6 8 7 1 4 6 2 8 7 5 9 0 3 9 6 6 1 9 8 2 9 8 9 7 4 8 5 5 9 7 7 6 8 1 3 5 7 9 5 5 2 1 1 2 2 4 8 7 5 8 8 9 4 9 0]我们也可以使用matplotlib可视化测试数据及其预测标签:
# 导入 matplotlib import matplotlib.pyplot as plt # 将预测值赋给 `predicted` predicted = svc_model.predict(X_test) # 将images_test和images_prediction中的预测值压缩在一起 images_and_predictions = list(zip(images_test, predicted)) # 对于images_and_prediction中的前四个元素 for index, (image, prediction) in enumerate(images_and_predictions[:4]): # 在坐标i 1处初始化一个1×4的网格中的子图 plt.subplot(1, 4, index 1) # 不显示坐标轴 plt.axis('off') # 在网格中的所有子图中显示图像 plt.imshow(image, cmap=plt.cm.gray_r, interpolation='nearest') # 添加标题 plt.title('Predicted: ' str(prediction)) # 显示图形 plt.show()显示:
可以看到显示的这几张图形,预测的标签都是正确的。
评估模型最后,我们来评估一下模型的性能,看看它准确率怎么样。
# 导入 `metrics` from sklearn import metrics # 打印的分类报告 `y_test` 与 `predicted` print(metrics.classification_report(y_test, predicted)) # 打印“y_test”和“predicted”的混淆矩阵 print(metrics.confusion_matrix(y_test, predicted))输出:
precision recall f1-score support 0 1.00 1.00 1.00 55 1 0.98 0.96 0.97 55 2 1.00 1.00 1.00 52 3 0.98 0.96 0.97 56 4 0.97 1.00 0.98 64 5 0.97 0.97 0.97 73 6 1.00 1.00 1.00 57 7 0.98 0.98 0.98 62 8 0.94 0.94 0.94 52 9 0.97 0.97 0.97 68 accuracy 0.98 594 macro avg 0.98 0.98 0.98 594 weighted avg 0.98 0.98 0.98 594 [[55 0 0 0 0 0 0 0 0 0] [ 0 53 0 0 1 0 0 0 1 0] [ 0 0 52 0 0 0 0 0 0 0] [ 0 0 0 54 0 1 0 0 1 0] [ 0 0 0 0 64 0 0 0 0 0] [ 0 0 0 0 0 71 0 1 0 1] [ 0 0 0 0 0 0 57 0 0 0] [ 0 0 0 0 0 0 0 61 0 1] [ 0 1 0 1 0 1 0 0 49 0] [ 0 0 0 0 1 0 0 0 1 66]]可以看到,这个模型比前面章节的K均值聚类模型,效果要好得多。
我们再看一下预测标签与实际标签的散点图。
# 导入 `Isomap()` from sklearn.manifold import Isomap # 创建一个isomap,并将“digits”数据放入其中 X_iso = Isomap(n_neighbors=10).fit_transform(X_train) # 计算聚类中心并预测每个样本的聚类指数 predicted = svc_model.predict(X_train) # 在1X2的网格中创建带有子图的图 fig, ax = plt.subplots(1, 2, figsize=(8, 4)) # 调整布局 fig.subplots_adjust(top=0.85) # 将散点图添加到子图中 ax[0].scatter(X_iso[:, 0], X_iso[:, 1], c=predicted) ax[0].set_title('Predicted labels') ax[1].scatter(X_iso[:, 0], X_iso[:, 1], c=y_train) ax[1].set_title('Actual Labels') # 加标题 fig.suptitle('Predicted versus actual labels', fontsize=14, fontweight='bold') # 显示图形 plt.show()显示
从图中可以看出,模型的预测结果与实际结果匹配度非常好,模型的准确率很高。
参数值前面在创建模型时,手动设置了gamma等参数的值,通过使用网格搜索和交叉验证等工具,可以自动找到合适的参数值。
尽管这不是本篇教程的重点,本节内容演示如何使用网格搜索和交叉验证等工具,自动找到合适的参数值。
import numpy as np from sklearn import datasets # 加载 `digits` 数据集 digits = datasets.load_digits() # 导入 `train_test_split` from sklearn.model_selection import train_test_split # 将 `digits` 数据分成两个相等数量的集合 X_train, X_test, y_train, y_test = train_test_split(digits.data, digits.target, test_size=0.5, random_state=0) # 导入“svm”模型 from sklearn import svm # 导入 GridSearchCV from sklearn.model_selection import GridSearchCV # 设置参数候选项 parameter_candidates = [ {'C': [1, 10, 100, 1000], 'kernel': ['linear']}, {'C': [1, 10, 100, 1000], 'gamma': [0.001, 0.0001], 'kernel': ['rbf']}, ] # 使用参数候选项创建分类器 clf = GridSearchCV(estimator=svm.SVC(), param_grid=parameter_candidates, n_jobs=-1) # 根据训练数据训练分类器 clf.fit(X_train, y_train) # 打印结果 print('训练数据的最佳得分:', clf.best_score_) print('最佳惩罚参数C:',clf.best_estimator_.C) print('最佳内核类型:',clf.best_estimator_.kernel) print('最佳gamma值:',clf.best_estimator_.gamma) # 将分类器应用到测试数据上,查看准确率得分 clf.score(X_test, y_test) # 用网格搜索参数训练一个新的分类器,评估得分 score = svm.SVC(C=10, kernel='rbf', gamma=0.001).fit(X_train, y_train).score(X_test, y_test) print(score)输出
C:\Anaconda3\python.exe "C:\Program Files\JetBrains\PyCharm 2019.1.1\helpers\pydev\pydevconsole.py" --mode=client --port=64053import sys; print('Python %s on %s' % (sys.version, sys.platform))sys.path.extend(['C:\\app\\PycharmProjects', 'C:/app/PycharmProjects'])Python 3.7.6 (default, Jan 8 2020, 20:23:39) [MSC v.1916 64 bit (AMD64)]Type 'copyright', 'credits' or 'license' for more informationIPython 7.12.0 -- An enhanced Interactive Python. Type '?' for help.PyDev console: using IPython 7.12.0Python 3.7.6 (default, Jan 8 2020, 20:23:39) [MSC v.1916 64 bit (AMD64)] on win32runfile('C:/app/PycharmProjects/ArtificialIntelligence/test.py', wdir='C:/app/PycharmProjects/ArtificialIntelligence')训练数据的最佳得分: 0.9866480446927375最佳惩罚参数C: 10最佳内核类型: rbf最佳gamma值: 0.0010.9911012235817576
可以看到,我们获取到了合适的参数。
,