事情的背景是这样的:

需求描述
两天后:

excel 内容预览如下:

全部代码参考Github:coursera/Projects/clinical_exp/clinical_exp at master · oscarzhao/coursera
需求调研第一步当然是调研下需求,打开"试验公示和查询 (chinadrugtrials.org.cn)",映入眼帘的是一个大列表,列表里有一些关键字段,比如登记号、适应症,但是另外两个指标目标入组人数、实际入组人数都需要进入详情页才能看到。另外,这些信息不需要登录就能获取,还是挺方便的。

打开一些详情页,信息量很大,是很多表格的组合,实验人数在页面的最下方。我选取了“双氯芬酸钠肠溶片” 这个药物,因为它的实验状态包含“招募完成”,意味着有数据。

详情页-页头

详情页-页尾
目标入组人数的值是“国内:36;”,当然我们就可以猜想有“国外:xxx;”,实际查找中发现,国内国外并存的情况也有,给后面的解析工作增加了一些难度。
数据总量是 17853条,列表页共 893页,数据量不大。
确定技术方案搜索“爬虫框架”,排名第一的是 Scrapy,就选它了。搜索Scrapy,排名靠前的有RUNOOB的 Scrapy 入门教程 | 菜鸟教程,先讲了下架构,每个模块的功能,后面讲的例子只有架构中很小的一部分,看的有点懵。我又找到官方文档 Scrapy Tutorial — Scrapy 2.6.2 documentation,上来就是怎么创建一个项目并运行起来。程序员讲究 get your hands dirty,先跟着一个例子摸索一番,反而更容易入门。

来自于RUNOOB
学习 Scrapyhttps://docs.scrapy.org/en/latest/intro/tutorial.html
第一步:创建项目
pip install scrapy
scrapy startproject tutorial
第二步:自定义 Spider 类
功能非常简单,只需要下载网页,存到本地对应的文件。start_Requests 通过 yield scrapy.Request 把请求封装在 generator 里。parse 方法作为 callback 去处理请求结果
import scrapy
class QuotesSpider(scrapy.Spider):
name = "quotes"
def start_requests(self):
urls = [
'https://quotes.toscrape.com/page/1/',
'https://quotes.toscrape.com/page/2/',
]
for url in urls:
yield scrapy.Request(url=url, callback=self.parse)
def parse(self, response):
page = response.url.split("/")[-2]
filename = f'quotes-{page}.html'
with open(filename, 'wb') as f:
f.write(response.body)
self.log(f'Saved file {filename}')
第三步:运行代码
scrapy crawl quotes
这个例子很简单,只是存储网页内容,但没有解析网页里的元素。解析元素最常见的是 xpath工具,结合浏览器的审查元素 Inspect 和 scrapy shell ,能够快速拿到想要的东西

Chrome 获取 XPath
Scrapy shell 提供了强大的调试能力,在开始写代码之前,通过浏览器审查元素功能获取元素类型(div、table、title、a等)或者 XPath ,在Scrapy shell 里进行验证,提前发现浏览器渲染出来的html 与 服务器端返回的 html 的微妙差异,少走一些弯路。
官方教程里爬取的是一个 GET 返回的页面,执行下面的命令以后,在 console 里就可以使用 response Selector 进行各种实验了。下面这个例子是通过 css 方法 获取 <title> 元素:

审查元素里查看 head 里的title
scrapy shell "https://quotes.toscrape.com/page/1/"
>>> # 找到所有的 <title> 元素,返回 selector
>>> response.css('title')
[<Selector xpath='descendant-or-self::title' data='<title>Quotes to Scrape</title>'>]
>>> # 所有 <title> 元素序列化后的结果
>>> response.css('title').getall()
['<title>Quotes to Scrape</title>']
>>> # 所有 <title> 元素里的内容
>>> response.css('title::text').getall()
['Quotes to Scrape']
>>> # 第一个 <title> 元素里的内容
>>> response.css('title::text').get()
'Quotes to Scrape'
>>> # 第一个 <title> 元素里的内容,另一种写法
>>> response.css('title::text')[0].get()
'Quotes to Scrape'
通过这个console,我们测试获取想要的任何元素,学习 css 选择器和 xpath选择器的用法。这里抛出一个练习题:如何通过 css 和 xpath 两种方式获取 Top Ten Tags?答案放到文章的最后。
了解了如何解析html元素和里面的内容,下面这个 Spider子类实现了获取名言警句的功能。一句名言结构包含三部分:句子本身,作者,一组标签,parse 返回了一个generator,generator每一个元素是都是组装后的dict,我们称之为 item:
import scrapy
class QuotesSpider(scrapy.Spider):
name = "quotes"
start_urls = [
'https://quotes.toscrape.com/page/1/',
'https://quotes.toscrape.com/page/2/',
]
def parse(self, response):
for quote in response.css('div.quote'):
yield {
'text': quote.css('span.text::text').get(),
'author': quote.css('small.author::text').get(),
'tags': quote.css('div.tags a.tag::text').getall(),
}
重新运行命令,可以将这些数据写入文件:
# 每个 item 被序列化成一个 json,合并以后,就不是合法json了
scrapy crawl quotes -O quotes.json
# 每个item被序列化为只有一行的 json
# 合并完以后,是 jsonlines 结构
scrapy crawl quotes -o quotes.jl
这个方法比较糙,通过定制 Pipeline 可以实现更精细化地控制,后面我们在实现需求时再说。
临床药物试验需求初步了解了爬虫技术,开始做临床药物试验这个需求。首先通过审查元素功能看列表页和详情页的基本情况。
列表页的获取、元素抽取和存储令人震惊的是获取下一页是通过 post 请求实现的,Content-Type 是 form,post的返回结果是一个完整的页面。

竟然是 post 获取下一页

post 返回了一个页面

payload里有一些参数
在 request payload 里有一些参数,通过 Postman测试 发现只有 currentpage 参数有用。

Postman 参数测试
列表页里的数据很容易解析,找到 <table class="searchTable"> 下的所有 <tr> 元素,遍历一遍,就拿到了期望的结果:

列表页元素定位
代码层面上,增加 china_drug_trial_list.py 文件,创建 ChinaDrugTrialList 类,结构就是照搬tutorial里的例子:
class ChinaDrugTrialListSpider(scrapy.Spider):
name = 'china_drug_trial_list'
def start_requests(self):
url = 'http://www.chinadrugtrials.org.cn/clinicaltrials.searchlist.dhtml'
pass
def parse(self, response, **kwargs):
pass
start_requests 负责创建 Request generator,由于这是 PostForm 请求,Content-Type 和 Request 就必须按照特定的格式去写,成型的版本如下:
def start_requests(self):
url = 'http://www.chinadrugtrials.org.cn/clinicaltrials.searchlist.dhtml'
max_page = 893 # production
# max_page = 1 # testing
header = {
'Content-Type': 'application/x-www-form-urlencoded',
'User-Agent': 'PostmanRuntime/7.29.2',
}
for current_page in range(1, max_page 1, 1):
yield scrapy.FormRequest(
url=url,
method="POST",
callback=self.parse,
headers=header,
formdata={
'currentpage': str(current_page),
}
# errback=self.err_callback,
)
为了快速实现需求,我并没有读完 Tutorial,简单看了下 Following Links 功能,没看太懂,就忽略过去了,最终把页数 hard code到了代码里。
这里踩了不少坑,比如用 scrapy.Request 发现不顶用换成了 FormRequest,比如 formdata 的 value 必须是字符串类型。报错时,用 PyCharm 点进去源代码看,效果还是蛮好的。
请求的 callback 函数是 self.parse 函数,它负责页面的元素的抽取。逻辑是找到 <table> 下面的 <tr>,跳过表头,进行遍历。由于 Chrome 对 xpath 支持比较好,所以实现过程中,均采用了这种方式进行筛选。核心代码如下:
def parse(self, response, **kwargs):
table_list = response.xpath('//table[@class="searchTable"]')
# logging.error("---------------table=%s", table_list[0].xpath('text()'))
tr_list = table_list.xpath('tr')
logging.error("---------------table number=%d, tr number=%d", len(table_list), len(tr_list))
data = list()
for tr_item in tr_list[1:]:
a = tr_item.xpath('td[2]/a')
id = a.xpath('@id').get()
# link = a.xpath('@href').get()
ckm_index = int(a.xpath('@name').get())
register_no_list = a.xpath('text()').extract()
register_no = register_no_list[0].strip() if register_no_list else ''
item = ClinicalExpItem(
id=id,
ckm_index=ckm_index,
register_no=register_no,
)
yield item
由于我个人比较喜欢强类型,所以定义了 ClinicalExpItem:
class ClinicalExpItem(scrapy.Item):
ckm_index = scrapy.Field()
id = scrapy.Field()
register_no = scrapy.Field()
data_json = scrapy.Field()
kv = scrapy.Field()
pipelines.py 里定义了如何对 Items 进行处理。我做的事情很简单,就是导出 json line 结构,核心代码如下(暂时忽略其他细节):
class ClinicalExpPipeline:
def process_item(self, item, spider):
adapter = ItemAdapter(item)
line = json.dumps(adapter.asdict()) '\n'
self.__fd.write(line) # __fd -> file descriptor
代码写完之后,执行 scrapy crawl china_drug_trial_list 生成一个 txt 文件,大概长这样:
{"id": "5f5adf2c747f43c388b0c943609a3195", "ckm_index": 1, "register_no": "CTR20222379"}
{"id": "191dc5cb2b31466398771ba8e3b7ee99", "ckm_index": 2, "register_no": "CTR20222375"}
{"id": "a5c8291f29dc47449941463c474c502e", "ckm_index": 3, "register_no": "CTR20222368"}
{"id": "8e4a3033c7994f7f863c398fe0ab4f1d", "ckm_index": 4, "register_no": "CTR20222367"}
{"id": "f6ddaeb5e583430686c52813a0146900", "ckm_index": 5, "register_no": "CTR20222363"}
我希望以 china_drug_trial_list 的输出作为参数,获取每个试验更详细的信息,并存储到 csv 文件里。
详情页比较麻烦,因为每次点击都会打开一个新的Tab,通过Inspect->Network无法追踪网络请求,不知道向服务器到底发了啥。

detail page 行为
查看 getDetail 函数的实现:

getDetail 函数
找到 id="searchfrm" 的表单,然后就有了所有的输入字段。

form id="searchfrm"
到这里其实,请求类型、参数等基本都确定下来。从列表页进入详情页的请求类型是POST form。通过 Postman 测试可以确定formdata的最小集合:
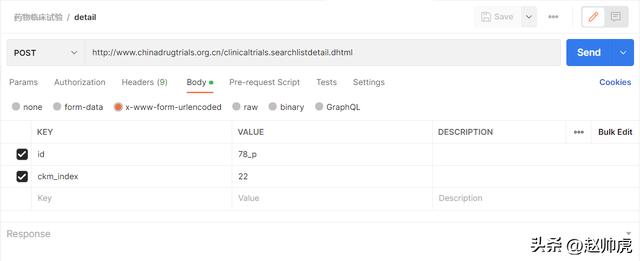
由于我对前端不熟,对form不是很了解,感觉从 getDetail 函数代码和 <input> 元素推断参数太麻烦,索性直接用 WireShark 抓包(注意:不要开VPN抓包)。找到一个请求的例子,在 Postman 里不断试错,确定最小参数集。

Wireshark 抓取http请求
至此,详情页已经能够拉到本地了,我们看如何通过 id 获取 登记号、适应症、目标入组人数、实际入组人数。快糙猛的方法是启动一个 scrapy shell,获取 response。通过浏览器审查元素获取 xpath,稍微修改获取想要的指标。下面是相关的命令:
url = 'http://www.chinadrugtrials.org.cn/clinicaltrials.searchlistdetail.dhtml'
header = {
'Content-Type': 'application/x-www-form-urlencoded',
'User-Agent': 'PostmanRuntime/7.29.2',
}
req = scrapy.FormRequest(
url=url,
method="POST",
# callback=self.parse,
headers=header,
formdata={'id': '78_p', 'ckm_index': '11'},
# errback=self.err_callback,
)
fetch(req)
response.xpath('.//span')
# 查找所有 class = searchTable 的 table 元素
response.xpath('//table[@class="searchTable"]')
# 查找所有 id=collapseTwo 下的 div 的所有子元素
# * 可以用来取 children 节点
response.xpath('//*[@id="collapseTwo"]/div/*')
# 查找当前路径下的所有 span
# response 换成其他的子Selector也能work
response.xpath('.//span')
由于这个请求是 POST form,必须在 scrapy shell 启动后,构造一个 FormRequest req 变量,通过 fetch(req) 更新 response。
知道了元素如何获取,但在提取表格里的数据时,需要处理的情况比较多:

情况1:th td 成对排列

情况2:td里嵌 table,table里都是td,没有th

情况3:td里嵌table,table的第一个tr是th,后面都是td
如果只是完成当前需求,只需要处理情况1 <th><td>成对的情况。但为了把程序写得更通用化,以支持未来可能的需求,我决定把这三种情况都支持掉。写了一个名为 parse_table 的递归函数,实际上支持两种情况:
- 第一行(第一个 <tr>)全是 <th>
- [不支持] 第一行(第一个 <tr>)全是 <td> 成对的情况
- 第一行(第一个 <tr>)是 <th><td> 成对的情况
class ChinaDrugTrialDetailSpider(scrapy.Spider):
name = 'china_drug_trial_detail'
def start_requests(self):
url = 'http://www.chinadrugtrials.org.cn/clinicaltrials.searchlistdetail.dhtml'
header = {
'Content-Type': 'application/x-www-form-urlencoded',
'User-Agent': 'PostmanRuntime/7.29.2',
}
# 读取 list 输出的 txt 文件,生成 FormRequest
def parse(self, response, **kwargs):
# 将表格信息存储到 data_json(其实没用到)
# 将关键的 th -> td 信息抽取出来,写入 kv=d
# 生成 item
item = ClinicalExpItem(
ckm_index=ckm_index,
register_no=d.get('登记号'),
data_json=data_json,
kv=d,
)
yield item
pipelines.py 里,支持新的 spider china_drug_trial_detail,Spider 初始化时,写入 csv 表头:
def open_spider(self, spider):
# do nothing
self.__fd = open(self.__dst_file, 'w', encoding='utf-8')
if spider.name == 'china_drug_trial_detail':
self.__cols = [
'登记号',
'适应症',
'目标入组人数',
'实际入组总人数',
'首次公示信息日期',
'试验状态',
'实验分期',
'药物类型',
'实验范围',
'设计类型',
'试验方案编号',
]
# write header
headers = self.__cols[:2]
headers = ['目标入组人数(国内)', '目标入组人数(国际)',
'实际入组总人数(国内)', '实际入组总人数(国际)']
headers = self.__cols[4:]
self.__fd.write('\t'.join(headers) '\t所有信息\n')
在 process_item 方法里也对新的 spider 提供支持,它做的是从 item['kv'] 字段里获取特定 column 的值,self.__cols 变量包含了所有column。在处理时有两个例外,目标入组人数和实际入组人数,国内和国际的数据均放在了一个 <td> 里,比如:"国内:36;国际:登记人暂未填写该信息;"特殊处理逻辑如下:
# col 是 self.__cols 的元素,比如"登记号"
v = kv.get(col, '')
if col == '目标入组人数' or col == '实际入组总人数':
data_map = dict()
for name_value_pair in map(lambda x: x.split(':'), v.split(';')):
if len(name_value_pair) == 2 and name_value_pair[1] != '登记人暂未填写该信息':
data_map[name_value_pair[0]] = name_value_pair[1]
datalist.append(data_map.get('国内', '0'))
datalist.append(data_map.get('国际', '0'))
else:
datalist.append(v)
代码写好以后,我们有一万多个case,大概运行一个小时才能出结果。所以先拿前200个进行测试,取消注释下图中选中的代码,执行 scrapy crawl china_drug_trial_detail, 数据被写入 detail-%Y-%m-%d.csv 文件,然后检查是否有问题。

取消注释这段代码
这里踩过的坑有:
- tbody 是浏览器自己加进去的,post 返回的结果中并没有这个层级
- 生成csv 时,分隔符使用 \t,不要使用英文逗号,因为数据里可能有逗号
- 数据中有很多 \n、\t、\r、空格、 (\xa0) 和中文标点
测试过程中,把发现的问题解决完以后,再完整跑一次,生成全量数据的 csv文件。
CSV -> Excelcsv 文件本身是可以被 Excel 直接打开的,但中文会有乱码问题。使用Excel自带的导入功能可以避免这个问题:
csv 导入 excel
pipelines 支持多个 spider在药物临床试验这个case中,我注册了list 和 detail 两个spider,目的是实现起来更简单,也可以边学习边推进这个项目。每次创建一个新的Spider,我们只需要创建一个新的类继承 scrapy.Spider,多个spider之间没有交互。但是对于pipelines而言,我们只有一个,我这边叫 ClinicalExpPipeline。Scrapy 选择的方式是,将 Spider 对象放到工厂函数中,并且注入Pipeline对象的每个方法中。
from_crawler 是classmethod,它也是工厂方法,我们可以用于创建不同的 Spider 对象:
class ClinicalExpPipeline:
def __init__(self, filepath):
self.__dst_file = filepath
self.__fd = None
self.__cols = None
@classmethod
def from_crawler(cls, crawler):
filepath = None
if crawler.spider.name == 'china_drug_trial_list':
filepath = 'list-{}.txt'.format(datetime.datetime.now().strftime('%Y-%m-%d'))
elif crawler.spider.name == 'china_drug_trial_detail':
filepath = 'detail-{}.csv'.format(datetime.datetime.now().strftime('%Y-%m-%d'))
else:
assert False, 'spider not found'
return cls(filepath=filepath)
这段代码中,list 和 detail Spider 的区别在于写入不同的文件。
除此之外,Pipeline 类还需要提供三个方法:
- 初始化状态:open_spider
- 处理item:process_item
- 销毁状态:close_spider
这个case里,open_spider 是打开文件,必要的话写header;close_spider 是关闭文件。
不得不说,这部分设计非常经典,扩展性非常好,理念上和大数据的UDF完全一致。
小结做完这个项目,再回头看RUNOOB 提供的爬虫框架,就很容易理解了。对于浏览器的审查元素功能、Wireshark的过滤器也有了入门级的了解,收获颇丰。
如何获取 Top Ten Tags
response.css("span[class=tag-item]")
response.xpath('//span[@class="tag-item"]')





