CNN在图像处理和视频处理领域有着广泛的应用。让我们了解CNN是如何运作的。
在本文中,我将介绍有关卷积神经网络如何演变的详细信息以及它们为何如此优秀的图像。我们还将进行实际操作,我们将使用keras构建卷积神经网络。
什么是卷积神经网络(CNN)?卷积神经网络与普通神经网络类似。它们也由神经元组成,并学习权重和偏差。它们将图像作为输入,然后对体系结构中的某些属性进行编码。
卷积神经网络(convolutional neural network)表示网络使用一种称为卷积的数学运算。
卷积是实值参数的两个函数的运算。

此操作在数学中称为卷积
在卷积神经网络术语中,卷积的第一个参数通常称为输入,第二个参数称为核,它们的输出称为特征映射。
现在我将展示如何在我们的CNN中应用这个数学术语“卷积”。
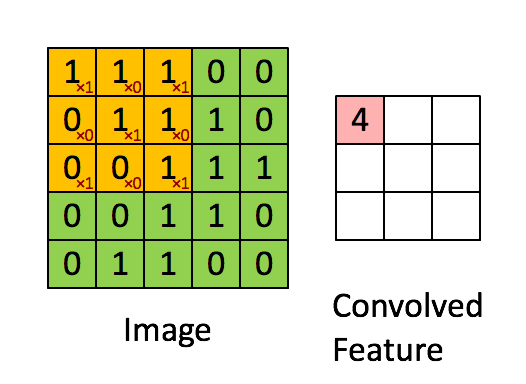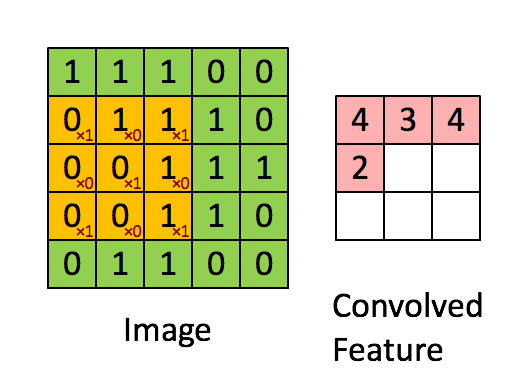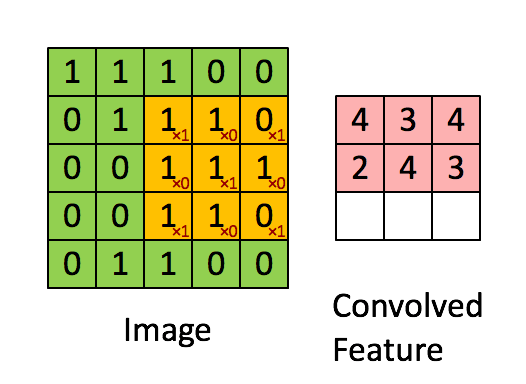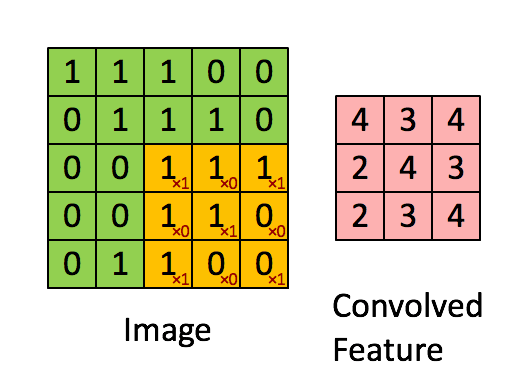
卷积如何在CNN中起作用
因此,您可以看到绿色矩阵是输入(由输入图像的像素组成的矩阵),黄色矩阵是核。所以在这里你可以看到核矩阵如何与输入矩阵卷积以给我们一个特征映射。您可以看到特征图的尺寸发生了一些变化。不用担心我们会在一段时间后详细介绍它。让我们继续下一个主题是Pooling。
池化层池化层主要用于连续卷积层之间。它用于减少表示的空间大小,以减少参数的数量和网络的计算。池化层独立应用于输入的每个深度切片,并减少输入的空间维度。它主要用于减少过度拟合。如果我们在输入上应用MAX POOLING,filter大小为2X2,步幅为2,那么它将在宽度和高度上对输入大小进行下采样,保持深度不受影响,这意味着它丢弃了75%的激活。现在下面是一个图像,其中包含如何实现池化层。

Max Pooling正在此图像中实施

这是使用最大池化进行下采样的方式
现在我们将讨论用于计算输出层尺寸的公式。

计算输出特征图的尺寸的公式
在该公式中,p和s分别是padding 和striding。我们将逐一了解它的细节。
paddingpadding 用于在边缘周围添加额外的像素。实际上,Padding所做的是确保角落处的像素得到所需的关注。注意,我的意思是在内核围绕输入矩阵旋转时的卷积中,中间的像素在卷积操作中出现不止一次时获得更多权重,而角落像素仅涉及一个卷积操作。因此,padding 在原始矩阵周围提供额外的一层或更多层,以便考虑角点像素。

在此图中Zero padding
Striding在卷积神经网络中Striding非常重要。我将在这里讨论如何在两个图像的帮助下实现Striding以使其清晰。

Max Pooling,Striding为2
所以在这张图片中,我们可以看到,一步,我们正在跳两格,而不是发送红色框。使用更大Striding的一个主要原因是减少输出特征图中的参数数量。
现在我们准备设计自己的CNN模型了。
设计卷积神经网络在这一部分中,我们将设计自己的卷积神经网络。CNN由卷积层,池化层和全连接层组成(我们可以在最后添加softmax以解决多类问题)。
我们将使用的架构如下图所示。我将使用Keras实现。现在,让我们进入架构。所以我们将实现一个两层卷积神经网络,并且我使用了ReLU激活函数和最大池化技术。有两个全连接层,最后有softmax激活。

CNN架构
Python实现如下:
model = Sequential() model.add(Conv2D(32, kernel_size=(5, 5), strides=(1, 1), activation='relu', input_shape=input_shape)) model.add(MaxPooling2D(pool_size=(2, 2), strides=(2, 2))) model.add(Conv2D(64, (5, 5), activation='relu')) model.add(MaxPooling2D(pool_size=(2, 2))) model.add(Flatten()) model.add(Dense(1000, activation='relu')) model.add(Dense(num_classes, activation='softmax')) model.compile(loss=keras.losses.categorical_crossentropy, optimizer=keras.optimizers.SGD(lr=0.01), metrics=['accuracy']) model.fit(x_train, y_train, batch_size=batch_size, epochs=epochs, verbose=1, validation_data=(x_test, y_test), callbacks=[history])
在第一层,我们使用了32个大小为5X5的filter,具有步幅1和ReLU激活函数。接下来,我们添加了最大池进行池化。在该层中,我们使用了64个大小为5X5的过滤器,然后是最大池化层。然后我们使用了一个flattened 层。之后,我们分别使用了具有ReLU和softmax激活的两个dense 层。然后我们使用交叉熵作为我们的损失函数和随机梯度下降(SGD)来最小化损失。然后我们根据我们的用例训练模型。
所以你看到使用Keras编写CNN是很容易的。请尝试使用您自己的数据集实现。
,




