Netty 可谓是当下最流行的网络编程框架,它被广泛应用在中间件、直播、社交、游戏等领域。目前,许多知名的开源软件也都将 Netty 用作网络通信的底层框架,如 Dubbo、RocketMQ、Elasticsearch、HBase 等。 Netty 作为一款高性能的网络框架,除了优秀的线程模型,高性能的内存管理也是必不可少的。
前言Netty 中的内存管理,如果从广义来说,ByteBuf 内存容器、ReferenceCounted 和 ResourceLeakDetector 等相关的内存泄露检测、负责分配内存的 ByteBufAllocator、内存分配和管理算法、零拷贝等内容均属于其范畴。下文所述的内存管理是从狭义上的 ByteBufAllocator 及 内存分配和管理算法出发,希望能给大家带来帮助。

Netty 内存管理比较复杂,理解上可能有些晦涩,屏蔽掉相对不太重要的一些细节,从大框架上力争讲述清晰。下面讲述自己的一些理解,同时也欢迎沟通,共同进步。
一、背景1.1 Netty 为什么要实现内存管理?Netty 作为底层网络框架,为了更高效的网络传输性能,堆外内存(Direct ByteBuffer)的使用是非常高频的。堆外内存在 JVM 之外,在有效降低 JVM GC 压力的同时,还能提高传输性能。但它也是一把双刃剑,堆外内存是非常宝贵的资源,申请和释放都是高成本的操作,使用不当还可能造成严重的内存泄露等问题 。那么进行池化管理,多次重用是比较有效的方式。从申请内存大小的角度讲,申请多大的 Direct ByteBuffer 进行池化又会是一大问题,太大会浪费内存,太小又会出现频繁的扩容和内存复制!!!所以呢,就需要有一个合适的内存管理算法,解决高效分配内存的同时又解决内存碎片化的问题。所以一个优秀的内存管理算法必不可少。
一个内存分配器至少需要看关注两个核心目标:
- 高效的内存分配和回收,提升单线程或者多线程场景下的性能
- 提高内存的有效利用率,减少内存碎片,包括内部碎片和外部碎片
Jemalloc memory allocator:http://jemalloc.net/
Netty 官方引用的两篇文档:A Scalable Concurrent malloc(3) Implementation for FreeBSD(https://www.bsdcan.org/2006/papers/jemalloc.pdf) 和
Scalable memory allocation using jemalloc(https://www.facebook.com/notes/10158791475077200)
常见的内存分配器比较: ptmalloc、tcmalloc和jemalloc(http://www.cnhalo.net/2016/06/13/memory-optimize)
1.3 Netty 内存管理的改动优化?近期公司内大佬近期的一篇文章让我了解到 Netty 在2020年9月份的 4.1.52 版本中就做了一次较大的优化升级:https://github.com/netty/netty/pull/10267。这次的改动也让 netty 的内存分配算法更接近原生的 jemalloc。核心改动如下:
- 去掉了 tiny 内存规格,仅保留:small、normal 和 huge,并重新划分了内存规格。与之带来伙伴分配算法的一些改动
- 由于内存规格的改动,带来 PoolChunk 内部结构的改动和 allocate 分配算法的改动
- PoolSubPage 原来要负责 tiny 和 small 内存规格的分配,自此只需服务于 small 内存规格。分配 Subpage 时,使用 pageSize 和 elemSize 的最小公共倍数而不再用 pageSize。
下文中我对于 Netty 内存管理的源码分析是2019年3月份的 4.1.34 版本。从 4.1.34 版本至当前(2021年10月)的 4.1.68 版本之间,除去 4.1.52 版本的较大改动,其余版本基本无算法层面的改动。以后向大佬们学习,能持续跟进最新发展趋势。
4.1.52 版本虽然有不小的改动,不过对于内存管理的核心思路和逻辑变化并不大,替换了引擎中的部分零件。对于有兴趣继续阅读下去这篇又臭又长又干的文章小伙伴,也带着辩证的角度去阅读,读完之后再回头品一品这次的改动。
接下来就看看 Netty 在 4.1.52 版本前是怎么实现 java 版的 jemalloc 的,以及向优秀的内存分配器核心目标做出细到极致的优化。
二、内存规格划分和伙伴算法2.1 内存规格划分为了分配的内存块尽可能保持连续、为了内存块能尽大程度的被利用、为了减少内部碎片,Netty 对内存规格进行了细致的划分。

上图第一列"分类"表示 Netty 对内存大小划分为:Tiny、Small、Normal 和 Huge 四类。
Netty 默认向操作系统申请的内存大小为 16MB,对于大于 16MB 的内存定义为 Huge 类型,认为是:大型内存不做缓存、不做池化,直接以 Unpool 的形式分配内存,用完后回收。
对于 16MB 及更小的内存,分类为:Tiny、Small、Normal,也有对应的枚举 SizeClass 进行描述。不过 Netty 定义了一套更细粒度的内存分配单位:Chunk、Page、Subpage,方便内存的管理。
Chunk 即上述提及的 Netty 向操作系统申请内存的单位,默认是 16MB。后续所有的内存分配也都是基于 Chunk 完成。Chunk 是 Page 的集合。
Page 是 Chunk 用于管理内存的基本单位。Page 的默认大小为 8KB,若欲申请 16KB,则需申请连续的两块空闲 Page。一个 Chunk(16MB),由 2048 个 Page (8KB)组成。
SubPage 是 Page 下的管理单位。对于底层应用,KB 级的内存已属于大内存的范畴,更多的是 B 级的小内存,直接使用Page 进行内存的分配,无疑是非常浪费的。所以对 Page 进行了切割划分,划分后的便是 SubPage,Tiny 和 Small 类型的内存使用的分配单位都是 SubPage。切割划分的算法原则是:如首次申请 512 B 的内存,则先申请一块 Page 内存,然后将 8 KB 的 Page 按照 512B 均分为 16 块,每一块可以认为是一个 SubPage,然后将第一块 SubPage 内存地址返回给申请方。同时下一次申请 512B 内存,则在 16 块中分配第二块。其他非 512B 的内存申请,则另外申请一个 Page 进行均等切分和分配。所以,对于 SubPage 没有固定的大小,和 Tiny、Small 中某个具体大小的内存申请有关。
PS:为什么只有上面穷举出来的内存大小,没有19B、21B、3KB这样规格?是因为 netty 中会把申请内存大小通过io.netty.buffer.PoolArena#normalizeCapacity方法进行了标准化,向上取整到最接近的上图中所列举出的大小,以便于管理。
2.2 伙伴分配算法Chunk作为向操作系统申请内存的单位,Page 作为 Chunk 管理内存的基本单位。Chunk 是通过伙伴算法 (Buddy system) 管理 Page,每个 Chunk 划分成 2048 个 Page,最终通过一颗 depth = 12 的满二叉树(共4095个节点,仅2048个叶子作为 Page)实现。如下图所示:

高度为 11 的节点(2048 - 4095)即为 Page 节点,代表 8 KB ;
高度为 10 的节点(1024 - 2047)均拥有 2 个 Page 节点,代表16 KB;
高度为 1 的节点(2、3)均拥有 1024 个 Page 节点,代表 8 MB;
高度为 0 的节点(1)拥有 2048 个 Page 节点,代表 16 MB,即一个满 Chunk 的大小。
在 PoolChunk 中有两个 byte 数组负责对 Page 分配。

- memoryMap[] 和 depthMap[] 初识化完成时,如上图所示,数组 index 代表树的节点编号(从1开始,1-4095),数组 value 存出当前节点编号在树中的高度(从0开始,0-11)。两个数组的内容完全相同。
- depthMap[] 初始化完成后,便永远不会变化,仅用来通过节点编号快速获取树的高度。depthMap[1024]=10、depthMap[2048]=11,毕竟数组查询 O(1) 的时间复杂度,不需要每次在进行计算
- memoryMap[] 初识化完成后,根据节点的分配情况,value 值会进行相应的更改。以及根据 value 值判断该节点是否可以被分配。
memoryMap[] 中的 value 值从小到大,会有下述三种状态:
- memoryMap[id] = depthMap[id] ,该节点没有被分配。如初始化完成时此种状态。
- depthMap[id] < memoryMap[id] < 最大高度(12)。至少有一个子节点被分配,但尚未完全被分配,不能再分配该高度对应的内存,只能根据实际分配较小一些的内存。
- memoryMap[id] = 最大高度(12) ,该节点及其子节点已被完全分配,没有剩余空间。
下面演示分配 Page 内存时,memoryMap[] 中 value 值的变化。
1、 memoryMap[] 还是一颗纯洁的树,内存还保持完整。分配 8 KB 内存时,变化如下。memoryMap[2048] 变为 12,直接进入状态3(完全被分配); 递归遍历2048的父节点,将父节点的值置为左右孩子节点中较小的值,如:memoryMap[1024]=11、memoryMap[1] = 0,这些节点都为状态2(部分被分配)。 进入下图状态:

2、在上述基础上,又有人申请分配 16 KB内存。原本树高为 10 的这层节点代表 16KB 内存大小,由于memoryMap[1024]=11,1024号节点被分出去的 8KB,只剩 8KB 空间可用,无法满足 16KB 的申请,所以在第10层顺序向后寻找可用节点。
1025号节点,memoryMap[1025]=10(状态1),符合条件,故将 1025 号节点分配。分配后 memoryMap[1025] 置为 12,进入状态3,他所有的子节点也要置为12。同时递归遍历 1025 号的父节点,将父节点的值置为左右孩子节点中较小的值。进入下图状态:

3、在上述基础上,又有人来申请分配 8 KB内存。树高为 11 的这层节点 2048 号节点找起,发现 memoryMap[2048]=12 不可用,在该层继续向后遍历找到 2049 号节点,memoryMap[2049]=11(状态1),便将2049号节点分配出去,memoryMap[2049] 置为 12(状态三)。同时递归遍历 2049 号的父节点,将父节点的值置为左右孩子节点中较小的值。进入下图状态:

4、在上述基础上,假如又有人来申请分配 8 MB 的内存。8MB 的内存节点在树高为 1 的这层节点上。2 号节点 memoryMap[2]=2(状态2),已不满足 8 MB 的需求,在该层继续向后遍历找到 3 号节点,memoryMap[3]=1(状态1),便将3号节点分配出去。此时 memoryMap[] 数组的状态图大家可自行想象一下。
上述分配算法位于 Netty 中的 io.netty.buffer.PoolChunk#allocateRun方法,有兴趣可以看此方法的源码,下文中也会介绍到。
三、ByteBufAllocator介绍完了内存规格的划分和分配,下面从前言提到的 ByteBufAllocator 做为真正内存管理算法的入口讲起。
ByteBufAllocator 是用来分配和创建 ByteBuf 的,它是最顶层的接口,下图是对它及各子类的梳理和总结,本文的关注点主要集中在 PooledByteBufAllocator 这个对 jemalloc 算法进行了 Java 版实现的池化内存分配器
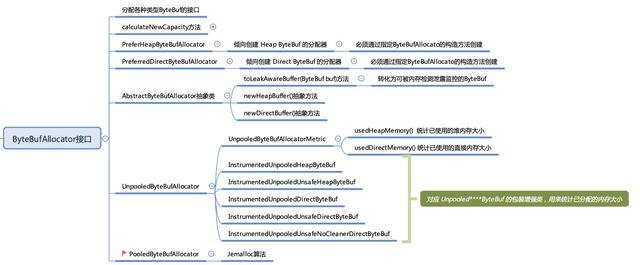
下面列举了下 PooledByteBufAllocator 中比较重要的一些变量,大概有个印象,这些变量贯穿整个内存分配过程。
// Heap 类型的 Arena 数量,默认(最小值):2*CPU核数
private static final int DEFAULT_NUM_HEAP_ARENA;
// direct 类型的 Arena 数量,默认(最小值):2*CPU核数
private static final int DEFAULT_NUM_DIRECT_ARENA;
// 默认 Page 的内存大小:8192B=8KB
private static final int DEFAULT_PAGE_SIZE;
// 满二叉树的高度,默认为 11 。8192 << 11 = 16 MiB per chunk。
private static final int DEFAULT_MAX_ORDER;
// PoolThreadCache 的 tiny 类型的内存块的缓存数量。默认为 512
private static final int DEFAULT_TINY_CACHE_SIZE;
// PoolThreadCache 的 small 类型的内存块的缓存数量。默认为 256
private static final int DEFAULT_SMALL_CACHE_SIZE;
// PoolThreadCache 的 normal 类型的内存块的缓存数量。默认为 64
private static final int DEFAULT_NORMAL_CACHE_SIZE;
// PoolThreadCache 缓存的最大内存块的字节数,默认:32*1024
private static final int DEFAULT_MAX_CACHED_BUFFER_CAPACITY;
// 是否使用PoolThreadCache。默认:true
private static final boolean DEFAULT_USE_CACHE_FOR_ALL_THREADS;
private final PoolArena<byte[]>[] heapArenas; // 默认值:DEFAULT_NUM_HEAP_ARENA
private final PoolArena<ByteBuffer>[] directArenas; // 默认值:DEFAULT_NUM_DIRECT_ARENA
private final int tinyCacheSize; // 默认值:DEFAULT_TINY_CACHE_SIZE
private final int smallCacheSize; // 默认值:DEFAULT_SMALL_CACHE_SIZE
private final int normalCacheSize; // 默认值:DEFAULT_NORMAL_CACHE_SIZE
// ThreadLocal线程变量,用于获得 PoolThreadCache 对象。(大名鼎鼎的 FastThreadLocal)
private final PoolThreadLocalCache threadCache;
private final int chunkSize; // Chunk 大小,16MB
这里简单提下 heapArenas 和 directArenas。PooledByteBufAllocator 是既可以分配 JVM 的 Heap 堆内存,也可以分配堆外 Direct 内存,所以分配器中既含有用于 Heap 内存分配的 heapArenas,又有 Direct 内存分配的 directArenas。两者分配过程的算法是基本一致的,不同的仅在于最底层向系统或 JVM 申请内存的方式。后面无特殊说明,默认按 Direct 内存的分配。
下面是我简单梳理出的一张“流程图”,它并非一张严谨的图,仅仅表达整体的“控制”关系,便于大家对 Netty 中内存分配都由哪些类来完成有一个初步的认知。Page加了虚线框,是因为它只是个逻辑概念,并没有实体类来承载,但又不避能开它,类似 Kafka 中的 topic 概念。

在 Netty 中如果需要进行池化的内存分配,代码可以这么写:
// 倾向于 directBuffer 分配的池化分配器。【倾向】= 大多数情况是 directBuffer。部分场景是 heapBuffer
PooledByteBufAllocator pooledAllocator = PooledByteBufAllocator.DEFAULT;
// 默认分配器:PooledByteBufAllocator.DEFAULT。
// 若识别到当前 System 是安卓系统(相对服务器,内存资源较为宝贵),则默认:UnpooledByteBufAllocator.DEFAULT
PooledByteBufAllocator pooledAllocator2 = (PooledByteBufAllocator) ByteBufAllocator.DEFAULT;
// 申请 32KB 的 directBuffer。 默认:directBuffer 分配器。
ByteBuf byteBuf = pooledAllocator.buffer(1024 * 32);
// 申请 16KB 的 directBuffer
ByteBuf byteBuf2 = pooledAllocator2.directBuffer(1024 * 16);
// 申请 16KB 的 heapBuffer
ByteBuf byteBuf3 = pooledAllocator2.heapBuffer(1024 * 32);
上面 directBuffer() 方法经过简单的校验,最终会走到下面 newDirectBuffer() 这个方法,整体逻辑也很简单。
protected ByteBuf newDirectBuffer(int initialCapacity, int maxCapacity) {
// 从 ThreadLocal 中获得 PoolThreadCache 对象,并获得对应的 directArena 对象
PoolThreadCache cache = threadCache.get();
PoolArena<ByteBuffer> directArena = cache.directArena;
// ...
// 从 directArena 中分配内存,请见下文分解
buf = directArena.allocate(cache, initialCapacity, maxCapacity);
// ...
// 将 ByteBuf 装饰成 LeakAware ( 可检测内存泄露 )的 ByteBuf 对象
return toLeakAwareBuffer(buf);
}
这里有个优秀的设计思想值得我们学习。PoolArena<ByteBuffer>[] directArenas 这个数组的大小是 2 * CPU 核数,在 ThreadLocal 初始化时会从 directArenas 数组中选取一个被线程引用最少的 PoolArena,这样做的目的是为了分散并发度,降低单个 PoolArena 的并发,缓解资源竞争的问题,以提高内存分配效率。
上面代码的内存分配逻辑最终落到了io.netty.buffer.PoolArena#allocate,接下来我们就看看 PoolArena 中做了什么事情。
四、PoolArena4.1 初识 PoolArena在 io.netty.buffer.PoolArena 中有一些 field 定义
enum SizeClass {
Tiny, // 16B - 496B 16B递增
Small, // 512B - 4KB 翻倍递增
Normal // 8KB - 16MB 翻倍递增
// 还有一个隐藏的,Huge // 16MB - 更大 和申请容量有关
}
// Tiny类型内存区间:[16,496],内存分配最小为16,每次增加16,直到496,共有31个不同的值
static final int numTinySubpagePools = 512 >>> 4;// tinySubpagePools数组的大小,默认:32
final int numSmallSubpagePools; // smallSubpagePools数组的大小,默认:pageShifts - 9 = 4
private final PoolSubpage<T>[] tinySubpagePools; // tiny 类型的 PoolSubpage 数组,每个元素都是双向链表。容量为32
private final PoolSubpage<T>[] smallSubpagePools;// small 类型的 PoolSubpage 数组,每个元素都是双向链表。容量为4
final PooledByteBufAllocator parent; // 所属 PooledByteBufAllocator 对象
private final int maxOrder; // 满二叉树的高度(从0开始),默认:11
final int pageSize; // Page大小,默认:8KB
final int pageShifts; // 从 1 开始左移到 {@link #pageSize} 的位数。默认 13 ,1 << 13 = 8192
final int chunkSize; // Chunk 内存块占用大小。8KB * 2048 = 16MB
private final PoolChunkList<T> q050; // 使用率 50% - 100% 的 Chunk 集合
private final PoolChunkList<T> q025; // 使用率 25% - 75% 的 Chunk 集合
private final PoolChunkList<T> q000; // 使用率 1% - 50% 的 Chunk 集合
private final PoolChunkList<T> qInit; // 使用率 MIN_VALUE - 25% 的 Chunk 集合
private final PoolChunkList<T> q075; // 使用率 75% - 100% 的 Chunk 集合
private final PoolChunkList<T> q100; // 使用率 100% 的 Chunk 集合
// 该 PoolArena 正在被多少线程同时引用
final AtomicInteger numThreadCaches = new AtomicInteger();
其中关键的数据结构是两个 PoolSubpage 数组和六个 PoolChunkList 双向链表。
4.2 PoolArena 中的两个 PoolSubpage 数组两个 PoolSubpage<T> 数组正如属性名 tinySubpagePools、smallSubpagePools,是分别负责小于 8KB 的 tiny 和 small 类型的内存分配。
Tiny 类型内存区间:[16B,496B],从 16B 开始,以 16B 递增,直到 496B,共有 31 个不同的值,tinySubpagePools 数组的大小为 numTinySubpagePools = 32。申请 tiny 内存时,根据 PoolArena.tinyIdx方法计算出在数组中的 index.
// index:1 -> 31
static int tinyIdx(int normCapacity) {
return normCapacity >>> 4;
}
Small 类型内存区间:512B、1KB、2KB、4KB,有 4 个不同的值,smallSubpagePools 数组的大小为 numSmallSubpagePools = 4。申请 small 内存时,根据 PoolArena.smallIdx方法计算出在数组中的 index.
// index: 0 -> 3
static int smallIdx(int normCapacity) {
int tableIdx = 0;
int i = normCapacity >>> 10;
while (i != 0) {
i >>>= 1;
tableIdx ;
}
return tableIdx;
}
PoolSubpage 对象本身也是个双向链表, tinySubpagePools、smallSubpagePools 两个数组在初识化时,每个 index 上初始化一个 prev 和 next 都指向自身 head 头结点。
4.3 PoolArena 中的六个 PoolChunkListPoolChunkList 用于分配大于等于 8KB 的 normal 类型内存,六个 PoolChunkList 分别存储不同使用率的 Chunk,并按使用率高低构成一个双向循环链表。
PoolArena 中对于 qInit -> q100 六个 PoolChunkList 的初始化代码如下:

根据这段代码,相信大家能在脑海中构建出双向循环链表的简易画面:

这里有几个问题和大家解释说明。
1、「六个 PoolChunkList 分别存储不同使用率的 Chunk」这句话什么意思?
内存规格划分中有提及:Chunk 是 Netty 向操作系统申请内存的单位,默认是 chunkSize = 16MB。后续所有的内存分配也都是基于 Chunk 完成。
第一次进行内存分配时,所有的 chunkList 没有 chunk 可以分配,则新建一个 chunk 进行内存分配,并添加到 qInit 这个 chunkList 中。假如此时又连续申请内存,在某次申请后该 chunk 被分配出去的内存达到或超过了 16MB * 25% = 4MB,则从 qinit 中进去 nextList (即 q000)中。此时继续申请内存,在某次申请后被分配达到或超过了 q000 的 maxUsage = 50%,则该 chunk 被移动到 q025 中。同理,该 chunk 若被完全分配,最终则会进入 q100 中。
chunk 中被分配的内存使用完进行释放时,则根据 chunk 当前的使用率和当前所处的 chunkList 的 minUsage 比较。若低于 minUsage ,该 chunk 会从当前的 chunkList 移动至 prevList 的 chunkList 中。直到该 chunk 被分配的内存完全释放,则会由 q000 移动至其 prevList(即:null),进而该 chunk 被释放。
六个 PoolChunkList 分别存储不同使用率的 chunk,根据 chunk 使用率的升高和降低,在六个 PoolChunkList 形成的循环列表中进行晋升和回退。这样使得使用率接近的 chunk 在同一 PoolChunkList 或接近的 PoolChunkList 中,方便统一管理。
2、qInit 和 q000 为什么需要设计成两个类似的 PoolChunkList
qInit 和 q000 这两个看似似乎有一个有些多余,其实不然。从设计中可以看出 qInit 的前驱节点是自己,q000 的前驱节点是 null。下面代码是 PoolChunkList 进行内存释放的主要流程。
// PoolChunkList.free 释放内存的方法
boolean free(PoolChunk<T> chunk, long handle, ByteBuffer nioBuffer) {
chunk.free(handle, nioBuffer); // 释放内存空间
if (chunk.usage() < minUsage) {
// chunk 的使用率低于当前 ChunkList 的 minUsage,则从 ChunkList 移除该 Chunk
remove(chunk);
// 将 chunk 移动到上一个 ChunkList 节点
// Move the PoolChunk down the PoolChunkList linked-list.
return move0(chunk);
}
return true;
}
// 递归
private boolean move0(PoolChunk<T> chunk) {
if (prevList == null) {
return false;
}
return prevList.move(chunk);
}
// 从 move0 方法调用,此处便是 preList 的 move 方法
private boolean move(PoolChunk<T> chunk) {
// 仍小于当前 ChunkList minUsage,继续该节点的 move0 移除方法
if (chunk.usage() < minUsage) {
// Move the PoolChunk down the PoolChunkList linked-list.
return move0(chunk);
}
// 执行真正的添加 chunk 到本 ChunkList 的操作
// PoolChunk fits into this PoolChunkList, adding it here.
add0(chunk);
return true;
}
从上述流程中不难分析出:qInit 中的 Chunk 使用率再小也不会小于它的 minUsage = Integer.MIN_VALUE,所以该 ChunkList 中的 Chunk 永远不会被回收;而 q000 中的 Chunk 使用率一旦小于 minUsage = 1%,内存被完全释放后则会被回收。
初识化 Chunk 和 25% 内存以内的分配、释放会让 Chunk 一直保留在 qInit 以内,避免重复的初始化操作。q000 的作用主要在于某 Chunk 在经历大起大落的内存分配和回收后,最终回落到 q000 的 ChunkList 内,完全释放后进行回收,防止永远驻留在内存中。qInit 和 q000 的搭配使用,使得内存分配和回收更高效。
3、为什么多个 ChunkList 的使用率会用一段重叠

从图中就可以得出答案:临界区的重叠是为了防止在内存分配和回收时两个紧邻 ChunkList 频繁移动,增加资源的消耗。
在日常的研发过程中恰当使用此思想,可以给程序带来性能的提升。比如说在使用一个 redis 集合准备存储 100 个元素,超过 100 个元素则需要裁剪到只留 100 个。
- 假如你的策略是每次向集合中插入元素后,判断 currentCapacity 是否大于 100,若大于 100 则删除多余的元素。那么第 101 个元素进出集合 10 次,则会多产生 10 次 IO 进行集合的裁剪
- 假如你的策略是:插入元素后,判断 currentCapacity 是否大于 100 10(buffer) = 110,若大于 110 才将元素个数裁剪为 100。那么第 101 个元素进出集合 10 次,相当于上个方案会减少 10 次 IO
PoolArena 中 allocate 方法的伪代码和流程图精简后,如下:
private void allocate(PoolThreadCache cache, PooledByteBuf<T> buf, final int reqCapacity) {
if(isTinyOrSmall(normCapacity)){
if (isTiny(normCapacity)) { // < 512B
// 1.1 优先从 PoolThreadCache 缓存中,分配 tiny 内存块,若存在则返回
} else { // 512B、1KB、2KB、4KB
// 1.1 优先从 PoolThreadCache 缓存中,分配 small 内存块,若存在则返回
}
// 1.2 其次,从 PoolSubpage 链表中,分配 Subpage 内存块,若存在则返回
// 1.3 最后,PoolSubpage 链表中分配不到 Subpage 内存块,所以申请 8KB 的 Normal 内存块。
// 即:申请一个 Page 节点,占用其中一块 Subpage 内存,并进行 PoolSubpage 链表初始化
allocateNormal(buf, reqCapacity, normCapacity);
…
return;
}
if (normCapacity <= chunkSize) { // >= 8KB && <= 16MB 时,分配Normal型内存
// 2.1 优先从 PoolThreadCache 缓存中,分配 Normal 内存块,并初始化到 PooledByteBuf 中。
// 2.2 申请并分配 Normal 内存块
allocateNormal(buf, reqCapacity, normCapacity);
}else{// 大于16MB时,分配 Huge 型内存
// 3.2 申请并分配 Huge 内存块,newUnpooledChunk(reqCapacity),非池化,用完便回收
allocateHuge(buf, reqCapacity);
}
}

PoolArena 的 allocate 内存分配流程中出现了 PoolThreadCache、PoolChunkList、PoolChunk 的 allocate 流程,在下文的介绍中会陆续分析到每一"组件"具体的 allocate 流程。

细心的话,在上述伪代码和流程图中可以反复看到一个 allocateNormal 的方法:
private void allocateNormal(PooledByteBuf<T> buf, int reqCapacity, int normCapacity) {
// 按照优先级,从5个 ChunkList 中,分配 Normal 内存块。如果有一分配成功,返回
if (q050.allocate(buf, reqCapacity, normCapacity)
|| q025.allocate(buf, reqCapacity, normCapacity)
|| q000.allocate(buf, reqCapacity, normCapacity)
|| qInit.allocate(buf, reqCapacity, normCapacity)
|| q075.allocate(buf, reqCapacity, normCapacity)) {
return;
}
// 第一次进行内存分配时,chunkList 没有 chunk 可以分配内存。新建一个 chunk 进行内存分配,并添加到qInit列表中
// Add a new chunk.
PoolChunk<T> c = newChunk(pageSize, maxOrder, pageShifts, chunkSize);
// 申请对应的 Normal 内存块。实际上,如果实际申请的内存大小为 tiny 或 small 类型,PoolChunk.allocate 内部会做特殊处理
boolean success = c.allocate(buf, reqCapacity, normCapacity);
assert success;
qInit.add(c);
}
code 一旦 show 出来,方法内部做了什么,一目了然。不过衍生出和上一章「六个 PoolChunkList」中 3 个问题类似的一个兄弟问题:
为什么 ChunkList 分配内存的顺序是 q050、q025、q000、qInit、q075 ?
推测原因大致有以下几点:
- q050 中 chunk 的内存使用率为:50%~100%,这大概是个折中的选择!这样大部分情况下,chunk 的使用率都会保持在一个较高水平,提高整个应用的内存使用率。并能频繁的创建和销毁,造成性能降低
- 为了保持较高的利用率,其次使用 q025 是个不错的选择
- qinit 和 q000 的 chunk 使用率低,但 qInit 中的 chunk 不会被回收,所以 q000 中若存在可分配的 chunk,则优先使用 q000
- q075 由于内存使用率偏高,在频繁分配内存的场景下可能导致分配成功率降低,因此放到最低优先级
最后,记住 PoolArena 内部就是这样一个结构:

文章太长,大家可能忍不了,上篇就到此结束吧。大家再回顾下内容,下篇很快就来
,




