大数据文摘专栏作品
作者:Christopher Dossman
编译:jiaxu、fuma、云舟
呜啦啦啦啦啦啦啦大家好,本周的AI Scholar Weekly栏目又和大家见面啦!
AI Scholar Weekly是AI领域的学术专栏,致力于为你带来最新潮、最全面、最深度的AI学术概览,一网打尽每周AI学术的前沿资讯,文末还会不定期更新AI黑镜系列小故事。
周一更新,做AI科研,每周从这一篇开始就够啦!
本周关键词:边缘检测、自动驾驶、姿态估计、图像复刻
在没有灾难性遗忘的情况下,实现深度强化学习的伪排练

该新模型集成了伪排练,深度生成模型和双重内存方案,从而实现了一种高效的方法,即使任务数量增加,也不需要额外的存储要求。通过迭代,该模型学习了三个Atari游戏,并在这三个游戏中保持了高于人类水平的表现,高效程度不亚于经过单独训练的一组网络。
所有这些都是在不访问以前的任务数据的情况下实现的。与现有的深度增强任务算法相比,新模型已经表明它们不会像传统的模型一样忘记之前的任务。
潜在应用与效果
研究人员和人工智能社区可以利用新模型进一步改进研究工作,并将模型应用于前沿的电子游戏、自动驾驶汽车和机器人中。如果有足够大的网络,也许会诞生能处理多种任务的机器人特工。
原文:
https://arxiv.org/abs/1812.02464v2
双注意网络(DAN)用于改进视觉参考分辨率
最近,研究人员通过提出DAN增强了视觉参考分辨率,为解决视觉参考分辨率问题奠定了基础。DAN实现了两种类型的关注网络,包括REFER和FIND。REFER专门用于通过自我关注方法来学习查询和对话历史之间的关系。
相反,FIND采用图像特征和参考感知表示输入(REFER模块的输出),并通过实施自下而上的注意技术实现视觉接地。在VisDial v1.0和v0.9数据集上对DAN的定量和定性评估表明,它在很大程度上优于现有的可视对话模型。

潜在应用与效果
AI社区可以使用DAN来实现各种视觉对话任务的视觉参考分辨率,比如协作对话系统。因为它不依赖于之前的视觉注意力图,所以DAN可以通过实施REFER组件来解决不清晰的视觉效果,并使用FIND模型组件对可视图像进行地面解析参考。
原文:
https://arxiv.org/abs/1902.09368v1
用于增强边缘检测的动态特征融合(DFF)方法
来自中国的研究人员通过提出一种新的动态特征融合(DFF)策略来管理动态特征融合,该策略为不同的图像和位置分配不同的融合权重。DFF包括两个模块,特征提取器和自适应权重融合组件。该模型通过实施权重模型来实现动态特征融合,从而能够针对输入特征图中的每一单个位置推断多级特征上的适当融合权重。

在对标准基准数据集(如Cityscapes和SBD)进行实验后,DFF证明了它可以通过更精确地定位对象边缘和抑制不重要的边缘响应来大大提高模型性能。
潜在应用与效果
语义边缘检测旨在联合提取边缘及其类别信息,以实现领域中的高端应用,包括语义分割,对象识别等。DFF是第一个旨在学习自适应融合权重的研究工作,它以输入数据为条件,在SED研究中融合多层次特征,以促进和实现SED任务的最新技术。通过考虑高级和低级主干特征映射,可以改善位置自适应权重学习器。
原文:
https://arxiv.org/abs/1902.09104v1
用于自动驾驶的离线和在线角落案例检测框架
这项新研究定义了角落案例检测,并提出了一个框架,可以处理来自移动车辆的前置摄像头的视频信号,并为在线和离线用例生成角落案例分数。根据该系统框架背后的研究人员所说,角落案例检测系统可用作备用警告系统,以提供有关自动驾驶系统的异常场景的信息。另外,关于离线模式,角落情况检测框架可用于分析大量视频数据以返回异常数据。
角落案例检测框架针对Cityscapes数据集的分段和图像预测进行了训练,该数据集包含来自50个城市的各种街道图像。

潜在应用与效果
自动驾驶汽车研究人员和工程师可以实施角落案例框架,为自动驾驶系统开发更集中的训练,因为它有助于解决代表性不足的关键训练数据问题。该系统还有助于选择用于存储和(重新)训练AI模型的相关场景。
此外,此次提出的角落案例检测框架对于实现运动检测,图像注册,视频跟踪,图像镶嵌,3D建模,全景拼接,对象识别等方面的进一步开发是有效的。
原文:
https://arxiv.org/abs/1902.09184v1
车辆相遇情况的数据集生成器
训练数据的缺乏大大减缓了自动驾驶技术的发展速度。而近日发布的一种模拟模型,通过提供大量数据和资源,从而帮助工程师实现有效的自动车辆开发测试,正逐步消除这一限制。
多车辆轨迹生成器(MTG)可以将多车辆场景(驾驶相遇数据)编码成可用于产生新的高质量驾驶相遇数据的刻度表达。这种发生器模型包括双向变分自动编码器和多分支解码器两大部分。

该研究还提出了一种新的解开度量指标,该指标具有综合分析模拟出的轨迹及驾驶场景模型稳健度的可能性。与现有的VAE和infoGAN模型相比,这种新型生成器模型在生成高质量的驾驶场景信息方面更占优势。
潜在应用与效果
多车辆轨迹生成器是自动驾驶开发中的一大进步。不仅是自动驾驶技术能因此获益而加速发展,这一方法同样可以扩展到有类似数据短缺问题的深度学习其他研究领域。
原文:
https://arxiv.org/abs/1809.05680v5
用于高分辨率人体姿态估计的高分辨率网络(HRNet)
与以串联方式连接子网络的传统方法不同,新的HRNet方法以并联方式连接高分辨率子网络,从而可以保持高分辨率,并实现准确的关键点预测。此外,许多现有的融合型方案结合了低级和高级表示,而HRNet执行重复的多尺度融合以增强高分辨率表示,这对于高质量的姿态估计是必不可少的。

在COCO关键点检测和MPII人类姿势数据集中进行的实验表明,HRNet较于传统方式更加有效。此外,HRNet在PoseTrack数据集上进行测试上也表现出了在姿势跟踪方面的优势。所有模型和代码均可在此链接上公开获取。
潜在应用与效果
研究人员和开发人员可以将HRNet应用于高级对象检测,动态识别,语义分割,人机交互(HCI),虚拟现实,增强现实,人脸识别及比对,图像识别及分类,翻译以及其他依赖跟踪和识别人类活动而实现服务的应用,例如Amazon Go。我很期待有一天我的智能手机可以告诉我我的举重姿势是否正确。
原文:
https://arxiv.org/abs/1902.09212v1
用于图像复刻的深度强化学习方法(DRLIH)
DRLIH是第一个从深度强化学习角度去解决图像复刻挑战的研究项目。
这种深度学习网络包括特征表示网络和策略网络。策略网络利用递归神经网络(RNN)作为代理,按时间顺序将图像投影为二进制代码。
这样的网络设计有助于生成图像并将其投影到复刻代码1中,并计算复刻代码0的概率。研究人员还提出了一种顺序学习策略,通过纠正先前函数的错误来提高检索准确性,从而学习复刻函数。DRLIH方法已经在三个标准数据集上进行了测试,结果证明它比传统图像复刻方法有效。
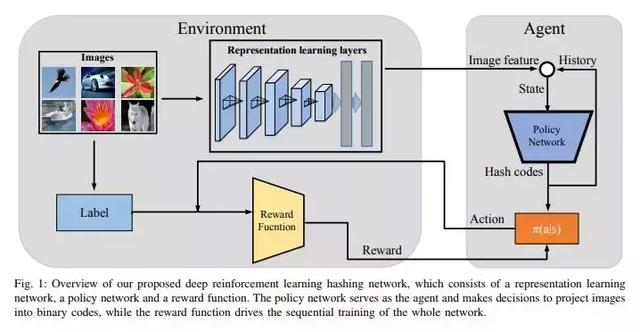
潜在应用与效果
DRLIH 技术可以准确地表示,索引,检索和自动识别图像。通过查询图像是否为原始图像的构造或副本,它可用于图像有效性的验证。DRLIH还可用于本地存储或缓存的有效性验证,防止照片重新传输或重复存储,以及目前通过水印实现的版权保护等。
原文:
https://arxiv.org/abs/1802.02904v2
语境嵌入改进临床概念提取
新的研究提出了一种处理这一长期挑战的新方法。研究人员评估了各种嵌入方法,包括word2vec,GloVe fastText,ELMo和BERT。他们还进行了涵盖四个临床概念语料库的分析,以证明上述每种技术的普遍性。
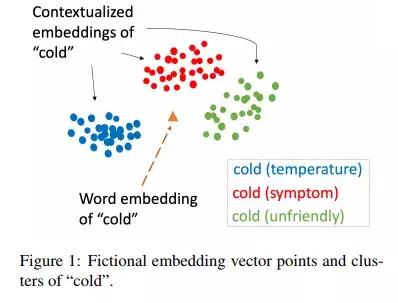
更重要的是,他们使用大型临床语料库开发预训练的情境化嵌入,并将性能与预训练模型进行了比较。
最后,他们的论文详述了与开放领域语料库相比,预训练对临床语料库影响的详细分析,并总结报告了临床概念提取的性能提升:该提取在所有测试语料库中实现了最先进的结果。研究结果显示出语境嵌入在临床文本语料库中的优势,其在各类任务的完成上都优于传统模型。
潜在应用与效果
对于临床概念提取,上下文嵌入有大幅度改善自动文本处理的潜力。
此外,它还使研究人员对临床文本的访问更加无障碍,从而进一步推动该领域的信息管理和非结构化临床文本的数据挖掘。
原文:
https://arxiv.org/abs/1902.08691v1
,