通过爬虫从页面上获取的数据需要我们存储下来
数据的存储有很多种很多样,比如TXT JSON CSV 也可以把数据保存在数据库中,想MYSQL MongoDB中.
今天来学习如何将数据保存在文本文件中文本文件适用于各个平台,但是不好检索. 不追求这些的话,就可采用TXT文本存储
import requests from pyquery import PyQuery as pq url = "https://ssr1.scrape.center/" html = requests.get(url).text doc = pq(html) items = doc(".el-card").items() file = open("movie.txt","w",encoding="utf-8") for item in items: name = item.find('a > h2').text() file.write(f'名称:{name}\n') #//类别 categories = [item.text() for item in item.find('.categories button span').items()] file.write(f'类别:{categories}\n') file.close() 复制代码其中核心的 今天要学习的就是
file = open("movie.TXT","w",encoding="utf-8") file.write(f'类别:{categories}\n') file.close() 复制代码其他的我们之前已经学过了,
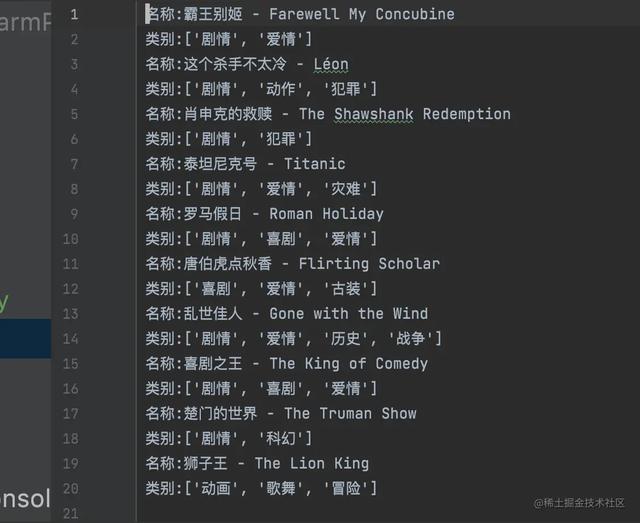
利用Python提供的open方法打开一个文本文件,获取一个文件操作对象,这里赋值为file,然后提取信息,然后利用file对象的write方法将信息写入文件,最后完成关闭操作,运行程序我们可以找到一个movie.TXT文件,打开如上图,我们可以看到信息已经被保存在了文本文件中.
openopen方法传递的第一个参数就是要保存的文件名,第二个参数是数据以何种方式写入,"w"代表写入,以覆盖的方式写入,第三个参数代表指定文件的编码
介绍文件操作方式简化写法
- r: 以只读方式打开文件,只能读取不能写入,这是默认模式
- rb: 以二进制只读方式打开一个文件,通常用于打开音频视频图片
- r : 以读写方式打开一个文件,既能读又能写
- rb : 二进制读写,但是读取和写入的都是二进制文件.
- w: 写入方式打开,已存在则覆盖,不存在就创建
- wb: 写二进制,同上
- w : 读写新文件,存在则覆盖,不存在则新建
- wb : 二进制读写,同上
- a: 追加方式打开文件,已存在写在已有文件之后,不存在则创建新文件写入
- a : 读写方式打开一个文件同上
- ab : 二进制 同上
文件写入还有一种简化写法
with open("movie.txt","a",encoding="utf-8"): file.write(f'名称:{name}\n') file.write(f'类别:{categories}\n') 复制代码当with控制块结束的时候文件会自动关闭,存成TXT是最基本的数据存储方法.
,