容器技术很火,经常为人所提及,尤其是开源容器工具Docker,已在不少数据中心里有广泛应用。容器主要是对软件和其依赖环境的标准化打包,将应用之间相互隔离,并能运行在很多主流操作系统上。这样看来容器和虚拟机技术很类似,容器是APP层面的隔离,而虚拟化是物理资源层面的隔离,容器解决了虚拟技术的不少痛点问题,很多时候容器可以和虚拟机结合在一起使用,这也是目前数据中心主流的做法。
当企业IT建设容器云平台时,会碰到一系列的挑战,根据CNCF的调查报告指出,容器的网络和安全实现成为容器云平台建设最主要的挑战,当企业开始将重要的企业核心应用迁移至容器平台,缺乏足够的网络和安全管控将会给业务上线带来潜在的巨大威胁。
除了容器网络安全,如何更好的链接不同Kubernetes集群孤岛,如何链接异构容器云平台,这些都是一系列的网络问题需要考虑。容器网络技术也在持续演进,从Docker本身的动态端口映射网络模型,到CNCF的CNI容器网络接口到Service Mesh CNI层次化SDN。

- Bridge模式,即Linux的网桥模式, Docker在安装完成后,便会在系统上默认创建一个Linux网桥,名称为docker0并为其分配一个子网,针对有Docker创建的每一个容器,均为其创建一个虚拟的以太网设备(veth peer)。其中一端关联到网桥上,另一端映射到容器类的网络空间中。然后从这个虚拟网段中分配一个IP地址给这个接口。其网络模型如下:
- Host模式,即共用主机的网络,它的网络命名空间和主机是同一个,使用宿主机Namespace、IP和端口。
- Container模式,使用已经存在容器的网络的Namespace,相当于多个容器使用同一个网络协议栈,Kubernetes中的Pod中多个容器之间的网络和存储的贡献就是使用这种模式。
- None模式,在容器创建时,不指定任何网络模式。由用户自己在适当的时候去指定。
CNI(Container Network Interface)是Google和CoreOS主导制定的容器网络标准,它是在RKT网络提议 的基础上发展起来的,综合考虑了灵活性、扩展性、IP分配、多网卡等因素。CNI旨在为容器平台提供网络的标准化。不同的容器平台(比如目前的Kubernetes、Mesos和RKT)能够通过相同的接口调用不同的网络组件。这个协议连接了两个组件:容器管理系统和网络插件,具体的事情都是插件来实现的,包括:创建容器网络空间(network namespace)、把网络接口(interface)放到对应的网络空间、给网络接口分配IP等。
目前采用CNI提供的方案一般分为两种,隧道方案和路由方案。
Callico
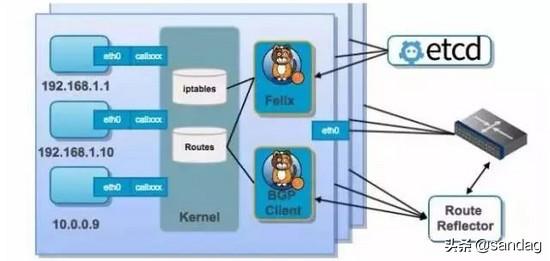
Callico容器网络和其他虚拟网络最大的不同是,它没有采用overlay网络做报文转发,提供了纯三层网络模型。三层通信模型表示每个容器都通过IP直接通信,要想路由工作能够正常,每个容器所在的主机节点必须有某种方法知道整个集群的路由信息,Callico采用 BGP路由协议,使得全网所有的Node和网络设备都记录到全网路由,然而这种方式会产生很多的无效路由,对网络设备路由规格要求较大,整网不能有路由规格低的设备。另外,Callico实现了从源容器经过源宿主机,经过数据中心路由,然后到达目的宿主机,最后分配到目的容器,整个过程中始终都是根据BGP协议进行路由转发,并没有进行封包,解包过程,这样转发效率就会快得多,这是Callico容器网络的技术优势。
Flannel

Flannel是CoreOS提出用于解决容器集群跨主机通讯的网络解决方案。Flannel实质上是一种覆盖网络Overlay network,也就是将TCP数据包装在另一种网络包里面进行路由转发和通信,目前已支持UDP、VXLAN、AWS VPC、GCE路由等数据转发方式,其中以VXLAN技术最为流行,很多数据中心在考虑引入容器时,也考虑将网络切换到Flannel的VXLAN网络中来。Flannel为每个主机分配一个subnet,容器从此subnet中分配IP,这些IP可在主机间路由,容器间无需NAT和端口映射就可以跨主机通讯。Flannel让集群中不同节点主机创建容器时都具有全集群唯一虚拟IP地址,并连通主机节点网络。Flannel可为集群中所有节点重新规划IP地址使用规则,从而使得不同节点上的容器能够获得“同属一个内网”且“不重复的”的IP地址,让不同节点上的容器能够直接通过内网IP通信,网络封装部分对容器是不可见的。源主机服务将原本数据内容UDP封装后根据自己的路由表投递给目的节点,数据到达以后被解包,然后直接进入目的节点虚拟网卡,然后直接达到目的主机容器虚拟网卡,实现网络通信目的。Flannel虽然对网络要求较高,要引入封装技术,转发效率也受到影响,但是却可以平滑过渡到SDN网络,VXLAN技术可以和SDN很好地结合起来,值得整个网络实现自动化部署,智能化运维和管理,较适合于新建数据中心网络部署。
Weave

Weave实质上也是覆盖网络,Weave可以把不同主机上容器互相连接的网络虚拟成一个类似于本地网络的网络,不同主机之间都使用自己的私有IP地址,当容器分布在多个不同的主机上时,通过Weave可以简化这些容器之间的通信。Weave网络中的容器使用标准的端口提供服务(如MySQL默认使用3306),管理微服务是十分直接简单的。每个容器都可以通过域名来与另外的容器通信,也可以直接通信而无需使用NAT,也不需要使用端口映射或者复杂的联接。部署Weave容器网络最大的好处是无需修改你的应用代码。Weave通过在容器集群的每个主机上启动虚拟路由器,将主机作为路由器,形成互联互通的网络拓扑,在此基础上,实现容器的跨主机通信。要部署Weave需要确保主机Linux内核版本在3.8以上,Docker 1.10以上,主机间访问如果有防火墙,则防火墙必须彼此放行TCP 6783和UDP 6783/6784这些端口号,这些是Weave控制和数据端口,主机名不能相同,Weave要通过主机名识别子网。Weave网络类似于主机Overlay技术,直接在主机上进行报文流量的封装,从而实现主机到主机的跨Underlay三层网络的互访,这是和Flannel网络的最大区别,Flannel是一种网络Overlay方案。
Macvlan网络方案Macvlan是Linux kernel比较新的特性,允许在主机的一个网络接口上配置多个虚拟的网络接口,这些网络interface有自己独立的MAC地址,也可以配置上IP地址进行通信。Macvlan下的虚拟机或者容器网络和主机在同一个网段中,共享同一个广播域。Macvlan和Bridge比较相似,但因为它省去了Bridge的存在,所以配置和调试起来比较简单,而且效率也相对高。除此之外,Macvlan自身也完美支持VLAN。
不同的容器网络方案,适用于不同的应用场景,就看企业如何选择了,从难易度上来讲,Callico最简单,其次Flannel,Weave最复杂,从网络技术来看,Weave和Flannel都是网络封装技术,区别在于封装的位置在网络设备上还是主机上。下图是4中方案的比较。

- 缺失企业级容器云安全隔离管控完整方案
- CNI本身不具备微服务发布所需要的原生负载均衡
- 仅支持单一Kubernetes集群
- 无法实现现有虚拟化,裸机策略延伸
- 缺乏足够的容器云网络的健康状态可视化,运维,排错工具。
服务网格是当下的一个热点,业界有些声音说服务网格是下一代SDN,但是Service Mesh并不能替代CNI,与CNI一起提供层次化微服务应用所需要的网络服务。

CNI需要交付给容器云L2-4层细化至微服务内部的每个Pod容器应用终端交付所需要的L2网络连接,L3路由,L2-4层安全隔离,容器云整体安全,负载均衡,etc……虽然现有的CNI仅提供非常有限的功能,此部分可通过后边介绍的NSX Datacenter完整交付。
Service Mesh更多的致力于微服务应用层面的服务治理,致力于L5-7层网络服务,服务网格在每一个应用容器前部署一个Sidecar Envoy应用代理,提供微服务间的智能路由,分布式负载均衡,流量管理,蓝绿,金丝雀发布,微服务弹性,限流熔断,超时重试,微服务间的可视化,安全等等。但是Service Mesh并不会替代CNI,他们工作在不同的SDN层次,CNI更多工作在L2-4层,Mesh在5-7层application SDN。Mesh不能独立于CNI部署。根据Gartner报告指出,在2020年,几乎100%容器云都将内置Service mesh技术。而目前开源的Istio Service Mesh仅提供单一Kubernetes集群内部微服务治理,缺失异构容器云,跨云能力。
从物理机到虚拟机,再到容器,这是服务器虚拟化技术发展的必然趋势,容器解决虚拟机的使用限制,但也将网络引入更复杂的境地,数据中心网络要去适应这种变化,要去适配容器,所以才出现了百花齐放的容器网络方案,这些方案都是为容器而生,从网络层面去适配容器。希望本文能作为一个引子,让业界的同仁能更好在容器化的浪潮下更好的劈波斩浪。
,