图像拼接算法及实现(一)
关键词:图像拼接 图像配准 图像融合 全景图
第一章 绪论
1.1 图像拼接技术的研究背景及研究意义
图像拼接(image mosaic)是一个日益流行的研究领域,他已经成为照相绘图学、计算机视觉、图像处理和计算机图形学研究中的热点。图像拼接解决的问题一般式,通过对齐一系列空间重叠的图像,构成一个无缝的、高清晰的图像,它具有比单个图像更高的分辨率和更大的视野。
早期的图像拼接研究一直用于照相绘图学,主要是对大量航拍或卫星的图像的整合。近年来随着图像拼接技术的研究和,它使基于图像的绘制(IBR)成为结合两个互补领域——计算机视觉和计算机图形学的坚决焦点,在计算机视觉领域中,图像拼接成为对可视化场景描述(Visual Scene Representaions)的主要研究方法:在计算机形学中,现实世界的图像过去一直用于环境贴图,即合成静态的背景和增加合成物体真实感的贴图,图像拼接可以使IBR从一系列真是图像中快速绘制具有真实感的新视图。
在军事领域网的夜视成像技术中,无论夜视微光还是红外成像设备都会由于摄像器材的限制而无法拍摄视野宽阔的图片,更不用说360 度的环形图片了。但是在实际应用中,很多时候需要将360 度所拍摄的很多张图片合成一张图片,从而可以使观察者可以观察到周围的全部情况。使用图像拼接技术,在根据拍摄设备和周围景物的情况进行分析后,就可以将通过转动的拍摄器材拍摄的涵盖周围360 度景物的多幅图像进行拼接,从而实时地得到超大视角甚至是360 度角的全景图像。这在红外预警中起到了很大的作用。
图像拼接技术主要分为三个主要步骤:图像预处理、图像配准、图像融合与边界平滑,图像预处理主要指对图像进行几何畸变校正和噪声点的抑制等,让参考图像和待拼接图像不存在明显的几何畸变。在图像质量不理想的情况下进行图像拼接,如果不经过图像预处理,很容易造成一些误匹配。图像预处理主要是为下一步图像配准做准备,让图像质量能够满足图像配准的要求。图像配准主要指对参考图像和待拼接图像中的匹配信息进行提取,在提取出的信息中寻找最佳的匹配,完成图像间的对齐。图像拼接的成功与否主要是图像的配准。待拼接的图像之间,可能存在平移、旋转、缩放等多种变换或者大面积的同色区域等很难匹配的情况,一个好的图像配准算法应该能够在各种情况下准确找到图像间的对应信息,将图像对齐。图像融合指在完成图像匹配以后,对图像进行缝合,并对缝合的边界进行平滑处理,让缝合过渡。由于任何两幅相邻图像在采集条件上都不可能做到完全相同,因此,对于一些本应该相同的图像特性,如图像的光照特性等,在两幅图像中就不会表现的完全一样。图像拼接缝隙就是从一幅图像的图像区域过渡到另一幅图像的图像区域时,由于图像中的某些相关特性发生了跃变而产生的。图像融合就是为了让图像间的拼接缝隙不明显,拼接更自然
2.2 图像的获取方式
图像拼接技术原理是根据图像重叠部分将多张衔接的图像拼合成一张高分辨率全景图 。这些有重叠部分的图像一般由两种方法获得 : 一种是固定照相机的转轴 ,然后绕轴旋转所拍摄的照片 ;另一种是固定照相机的光心 ,水平摇动镜头所拍摄的照片。其中 ,前者主要用于远景或遥感图像的获取 ,后者主要用于显微图像的获取 ,它们共同的特点就是获得有重叠的二维图像。
2.3 图像的预处理
2.3.1 图像的校正
当照相系统的镜头或者照相装置没有正对着待拍摄的景物时候,那么拍摄到的景物图像就会产生一定的变形。这是几何畸变最常见的情况。另外,由于光学成像系统或扫描系统的限制而产生的枕形或桶形失真,也是几何畸变的典型情况。几何畸变会给图像拼接造成很大的问题,原本在两幅图像中相同的物体会因为畸变而变得不匹配,这会给图像的配准带来很大的问题。因此,解决几何畸变的问题显得很重要。
图象校正的基本思路是,根据图像失真原因,建立相应的数学模型,从被污染或畸变的图象信号中提取所需要的信息,沿着使图象失真的逆过程恢复图象本来面貌。实际的复原过程是设计一个滤波器,使其能从失真图象中计算得到真实图象的估值,使其根据预先规定的误差准则,最大程度地接近真实图象。
2.3.2 图像噪声的抑制
图像噪声可以理解为妨碍人的视觉感知,或妨碍系统传感器对所接受图像源信息进行理解或分析的各种因素,也可以理解成真实信号与理想信号之间存在的偏差。一般来说,噪声是不可预测的随机信号,通常采用概率统计的方法对其进行分析。噪声对图像处理十分重要,它影响图像处理的各个环节,特别在图像的输入、采集中的噪声抑制是十分关键的问题。若输入伴有较大的噪声,必然影响图像拼接的全过程及输出的结果。根据噪声的来源,大致可以分为外部噪声和内部噪声;从统计数学的观点来定义噪声,可以分为平稳噪声和非平稳噪声。各种类型的噪声反映在图像画面上,大致可以分为两种类型。一是噪声的幅值基本相同,但是噪声出现的位置是随机的,一般称这类噪声为椒盐噪声。另一种是每一点都存在噪声,但噪声的幅值是随机分布的,从噪声幅值大小的分布统计来看,其密度函数有高斯型、瑞利型,分别成为高斯噪声和瑞利噪声,又如频谱均匀分布的噪声称为白噪声等。
1.均值滤波
所谓均值滤波实际上就是用均值替代原图像中的各个像素值。均值滤波的方法是,对将处理的当前像素,选择一个模板,该模板为其邻近的若干像素组成,用模板中像素的均值来替代原像素的值。如图2.4所示,序号为0是当前像素,序号为1至8是邻近像素。求模板中所有像素的均值,再把该均值赋予当前像素点((x, y),作为处理后图像在该点上的灰度g(x,y),即
g(x,y)=

(2-2-2-1)
其中,s为模板,M为该模板中包含像素的总个数。
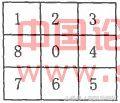
图2.2.2.1模板示意图
2.中值滤波
中值滤波是基于排序统计理论的一种能有效抑制噪声的非线性信号处理技术。它的核心算法是将模板中的数据进行排序,这样,如果一个亮点(暗点)的噪声,就会在排序过程中被排在数据序列的最右侧或者最左侧,因此,最终选择的数据序列中见位置上的值一般不是噪声点值,由此便可以达到抑制噪声的目的。取某种结构的二维滑动模板,将模板内像素按照像素值的大小进行排序,生成单调上升(或下降)的二维数据序列。二维德中值滤波输出为 ( 2-2-2-2 )
其中,f(x,y),g (x,y)分别为原图像和处理后的图像,w二维模板,k ,l为模板的长宽,Med 为取中间值操作,模板通常为3 3 、5 5 区域,也可以有不同形状,如线状、圆形、十字形、圆环形。
2.4 本章小结
本章主要介绍了图像几何畸变校正和图像噪声抑制两种图像预处理.
第三章 图像配准算法
3.1 图像配准的概念
图像配准简而言之就是图像之间的对齐。图像配准定义为:对从不同传感器或不同时间或不同角度所获得的两幅或多幅图像进行最佳匹配的处理过程。为了更清楚图像配准的任务,我们将图像配准问题用更精确的数学语言描述出来。配准可以用描述为如下的问题:
给定同一景物的从不同的视角或在不同的时间获取的两个图像I ,I 和两个图像间的相似度量S(I ,I ),找出I ,I 中的同名点,确定图像间的最优变换T,使得S(T(I ),I )达到最大值。
图像配准总是相对于多幅图像来讲的,在实际工作中,通常取其中的一幅图像作为配准的基准,称它为图,另一幅图像,为搜索图。图像配准的一般做法是,首先在参考图上选取以某一目标点为中心的图像子块,并称它为图像配准的模板,然后让模板在搜索图上有秩序地移动,每移到一个位置,把模板与搜索图中的对应部分进行相关比较,直到找到配准位置为止。
如果在模板的范围内,同一目标的两幅图像完全相同,那么完成图像配准并不困难。然而,实际上图像配准中所遇到的同一目标的两幅图像常常是在不同条件下获得的,如不同的成像时间、不同的成像位置、甚至不同的成像系统等,再加上成像中各种噪声的影响,使同一目标的两幅图像不可能完全相同,只能做到某种程度的相似,因此图像配准是一个相当复杂的技术过程。 3.2 基于区域的配准
3.2.1 逐一比较法
设搜索图为s待配准模板为T,如图3.1所示,S大小为M N,T大小为U V,如图所示。

图3.1搜索图S与模板T示意图
逐一比较法的配准思想是:
在搜索图S中以某点为基点(i,j),截取一个与模板T大小一样的分块图像,这样的基点有(M-U 1) (N-V 1)个,配准的目标就是在(M-U 1)(N-V 1)个分块图像中找一个与待配准图像最相似的图像,这样得到的基准点就是最佳配准点。
设模板T在搜索图s上移动,模板覆盖下的那块搜索图叫子图S ,(i,j)为这块子图的左上角点在S图中的坐标,叫做参考点。然后比较T和S的内容。若两者一致,则T和S之差为零。在现实图像中,两幅图像完全一致是很少见的,一般的判断是在满足一定条件下,T和S 之差最小。
根据以上原理,可采用下列两种测度之一来衡量T和S 的相似程度。D(i,j)的值越小,则该窗口越匹配。

或

(3-2)
或者利用归一化相关函数。将式(3-1)展开可得:

(3-3)
式中等号右边第三项表示模板总能量,是一常数,与(i,j)无关;第一项是与模板匹配区域的能量,它随((i,j)的改变而改变,当T和S 匹配时的取最大值。因此相
关函数为:
R(i,j)=

(3-4)

(3-5)
1,并且仅当值S (m, n)/T (m, n)=常数时,R(i,j)取极大值。
该算法的优点:
(1)算法思路比较简单,容易理解,易于编程实现。
(2)选用的模板越大,包含的信息就越多,匹配结果的可信度也会提高,同时能够对参考图像进行全面的扫描。
该算法的缺点:
(1)很难选择待配准图像分块。因为一个如果分块选择的不正确,缺少信息量,则不容易正确的匹配,即发生伪匹配。同时,如果分块过大则降低匹配速度,如果分块过小则容易降低匹配精度。
(2)对图像的旋转变形不能很好的处理。算法本身只是把待配准图像分块在标准参考图像中移动比较,选择一个最相似的匹配块,但是并不能够对图像的旋转变形进行处理,因此对照片的拍摄有严格的要求。
3.2.2 分层比较法
图像处理的塔形(或称金字塔:Pyramid)分解方法是由Burt和Adelson首先提出的,其早期主要用于图像的压缩处理及机器人的视觉特性研究。该方法把原始图像分解成许多不同空间分辨率的子图像,高分辨率(尺寸较大)的子图像放在下层,低分辨率(尺寸较小)的图像放在上层,从而形成一个金字塔形状。
在逐一比较法的思想上,为减少运算量,引入了塔形处理的思想,提出了分层比较法。利用图像的塔形分解,可以分析图像中不同大小的物体。同时,通过对低分辨率、尺寸较小的上层进行分析所得到的信息还可以用来指导对高分辨率、尺寸较大的下层进行分析,从而大大简化分析和。在搜索过程中,首先进行粗略匹配,每次水平或垂直移动一个步长,计算对应像素点灰度差的平方和,记录最小值的网格位置。其次,以此位置为中心进行精确匹配。每次步长减半,搜索当前最小值,循环这个过程,直到步长为零,最后确定出最佳匹配位置。
算法的具体实现步骤如下:
(1)将待匹配的两幅图像中2
2邻域内的像素点的像素值分别取平均,作为这一区域(2*2)像素值,得到分辨率低一级的图像。然后,将此分辨率低一级的图像再作同样的处理,也就是将低一级的图像4*4邻域内的像素点的像素值分别取平均,作为这一区域(4*4)点的像素值,得到分辨率更低一级的图像。依次处理,得到一组分辨率依次降低的图像。
(2)从待匹配的两幅图像中分辨率最低的开始进行匹配搜索,由于这两幅图像像素点的数目少,图像信息也被消除一部分,因此,此匹配位置是不精确的。所以,在分辨率更高一级的图像中搜索时,应该在上一次匹配位置的附近进行搜索。依次进行下去,直到在原始图像中寻找到精确的匹配位置。
算法的优点:
(1)该算法思路简单,容易理解,易于编程实现。
(2)该算法的搜索空间比逐一比较要少,在运算速度较逐一比较法有所提高。
算法的缺点:
(1)算法的精度不高。在是在粗略匹配过程中,移动的步长较大,很有可能将第一幅图像上所取的网格划分开,这样将造成匹配中无法取出与第一幅图像网格完全匹配的最佳网格,很难达到精确匹配。
(2)对图像的旋转变形仍然不能很好的处理。与逐一比较法一样,该算法只是对其运算速度有所改进,让搜索空间变小,并无本质变化,因此对图像的旋转变形并不能进行相应处理。
3.2.3 相位相关法
相位相关度法是基于频域的配准常用算法。它将图像由空域变换到频域以后再进行配准。该算法利用了互功率谱中的相位信息进行图像配准,对图像间的亮度变化不敏感,具有一定的抗干扰能力,而且所获得的相关峰尖锐突出,位移检测范围大,具有较高的匹配精度。
相位相关度法思想是利用傅立叶变换的位移性质,对于两幅数字图像s,t,其对应的傅立叶变换为S,T,即:

(3-6)
若图像s,t相差一个平移量(x ,y ),即有:
s(x,y) = t(x-x ,y-y ) (3-7)
根据傅立叶变换的位移性质,上式的傅立叶变换为:

(3-8)
也就是说,这两幅图像在频域中具有相同的幅值,只是相位不同,他们之间的相位差可以等效的表示为互功率谱的相位。两幅图的互功率谱为:

(3-9)
其中*为共扼符号, 表示频谱幅度。通过对互功率谱式(3-9)进行傅立叶逆变换,在((x,y)空间的(x ,y ),即位移处,将形成一个单位脉冲函数 ,脉冲位置即为两幅被配准图像间的相对平移量x 和y
式(3-9)表明,互功率谱的相位等价于图像间的相位差,故该方法称作相位相关法。
相位相关度法的优点:
(1)该算法简单速度快,因此经常被采用。对于其核心技术傅立叶变换,现在己经出现了很多有关的快速算法,这使得该算法的快速性成为众多算法中的一大优势。另外,傅立叶变换的硬件实现也比其它算法容易。
(2)该算法抗干扰能力强,对于亮度变化不敏感。
相位相关度法的缺点:
(1)该算法要求图像有50%左右的重叠区域,在图像重叠区域很小的时,算法的结果很难保证,容易造成误匹配。
(2)由于Fourier变换依赖于自身的不变属性,所以该算法只适用于具有旋转、平移、比例缩放等变换的图像配准问题。对于任意变换模型,不能直接进行处理,而要使用控制点方法,控制点方法可以解决诸如多项式、局部变形等问题。
3.3 基于特征的配准
3.3.1 比值匹配法
比值匹配法算法思路是利用图像中两列上的部分像素的比值作为模板,即在参考图像T的重叠区域中分别在两列上取出部分像素,用它们的比值作为模板,然后在搜索图S中搜索最佳的匹配。匹配的过程是在搜索图S中,由左至右依次从间距相同的两列上取出部分像素,并逐一计算其对应像素值比值;然后将这些比值依次与模板进行比较,其最小差值对应的列就是最佳匹配。这样在比较中只利用了一组数据,而这组数据利用了两列像素及其所包含的区域的信息。
该算法的具体实现步骤如下:
(1)在参考图像T中间隔为c个像素的距离上的两列像素中,各取m个像素,计算这m个像素的比值,将m个比值存入数组中,将其作为比较的模板。
(2)从搜索图S中在同样相隔c个像素的距离上的两列,各取出m n个像素,计算其比值,将m n个比值存入数组。假定垂直错开距离不超过n个像素,多取的n个像素则可以解决图像垂直方向上的交错问题。
(3)利用参考图像T中的比值模板在搜索图S中寻找相应的匹配。首先进行垂直方向上的比较,即记录下搜索图S中每个比值数组内的最佳匹配。再将每个数组的组内最佳匹配进行比较,即进行水平方向的比较,得到的最小值就认为是全局最佳匹配。此时全局最佳匹配即为图像间在水平方向上的偏移距离,该全局最佳匹配队应的组内最佳匹配即为图像间垂直方向上的偏移距离。
比值匹配法的优点:
(1)算法思路清晰简单,容易理解,实现起来比较方便。
(2)在匹配计算的时候,计算量小,速度快。 比值匹配法的缺点:
(1)利用图像的特征信息太少。只利用了两条竖直的平行特征线段的像素的信息,没有能够充分利用了图像重叠区域的大部分特征信息。虽然算法提到,在搜索图S中由左至右依次从间距相同的两列上取出部分像素,计算其对应像素的比值,然后将这些比值依次与模版进行比较,好像是利用了搜索图S中的重叠区域的大部分图像信息,但在参考图像T中,只是任意选择了两条特征线,没有充分利用到参考图像T的重叠区域的特征信息。
(2)对图片的采集提出了较高的要求。此算法对照片先进行垂直方向上的比较,然后再进行水平方向上的比较,这样可以解决上下较小的错开问题。在采集的时候只能使照相机在水平方向上移动。然而,有时候不可避免的照相机镜头会有小角度的旋转,使得拍摄出来的照片有一定的旋转,在这个算法中是无法解决的。而且对重叠区域无明显特征的图像,比较背景是海洋或者天空,这样在选取特征模版的时候存在很大的问题。由于照片中存在大块纹理相同的部分,所以与模版的差别就不大,这样有很多匹配点,很容易造成误匹配。
(3)不易对两条特征线以及特征线之间的距离进行确定。算法中在参考图像T的重叠区域中取出两列像素上的部分像素,并没有给出选择的限制。然而在利用拼接算法实现自动拼接的时候,如果选取的特征线不是很恰当,那么这样的特征线算出来的模版就失去了作为模版的意义。同时,在确定特征线间距时,选的过大,则不能充分利用重叠区域的图像信息。选择的过小,则计算量太大。
3.3.2 特征点匹配法
比值匹配法利用图像特征较少,而且在图像发生小角度旋转的时候容易发生误匹配。基于特征点的匹配法可以很好的解决这类问题。特征点主要指图像中的明显点,如房屋角点、圆点等。用于点特征提取得算子称为有利算子或兴趣算子。自七十年代以来出现一系列各不相同、各有特色的兴趣算子,较知名的有Moravec算子、Hannah算子与Foistner等。
本文采用Moravec算子进行特征点提取:
Moravec算子的基本思想是,以像素点的四个主要方向上最小灰度方差表示该像素点与邻近像素点的灰度变化情况,即像素点的兴趣值,然后在图像的局部选择具有最大的兴趣值得点(灰度变化明显得点)作为特征点,具体算法如下:
(1)各像素点的兴趣值IV (interest value),例如计算像素点(c,r)的兴趣值,先在以像素点((cr)为中心的n n的影像窗口中(如图3.3.2所示的5 5的窗口),计算四个主要方向相邻像元灰度差的平方和。

图3.3.2 Moravec 算子特征点提取示意图

其中k=INT(n/2)。取其中最小者为像元((c,r)的兴趣值:
IV(c,r)=V=min{ V1,V2,V3,V4}
(2)根据给定的阂值,选择兴趣值大于该阐值的点作为特征点的候选点。设VR
为事先设定好的闭值,如果V > VR ,则V为特征点的候选点。
阑值得选择应以候选点中包括需要的特征点,而又不含过多的非特征点。
(3)在候选点中选取局部极大值点作为需要的特征点。在一定大小的窗口内(可不同于兴趣值计算窗口),去掉所有不是最大兴趣值的候选点,只留下兴趣值最大者,该像素即为一个特征点。
在有了以上的特征点提取的基础上,基于特征点匹配算法主要步骤如下:
(1)在图像T的重叠部分中选取4个区域,每个区域利用Moravec算子找出特征点。
(2)选取以特征点为中心的区域,本文大小选择7X7的区域,在搜索图S中寻找最相似的匹配。因为有4个特征点,故有4个特征区域,找到相应的特征区域的匹配也有4块。
(3)利用这4组匹配的特征区域的中心点,也就是4对匹配的特征点,代入方程式(3-2-2)求解,所求的解即为两幅图像间的变换系数。

(3-2-2)
该算法的主要优点:
(1)图像的特征信息得到了利用,能够有的放矢,不是在盲目的搜索。
(2)误匹配发生的概率小,因为利用了参考图像T包含特征点的特征区域来寻找相应匹配,因此在搜索图S中相应的特征区域容易确认。
该算法的主要缺点:
(1)计算的代价高,计算量大。该算法需要计算出特征点以及特征点的匹配点,同时还要将所有4对特征点带入式3-2-2求解变换系数,计算量大。
3.4 本章小结
本章分析了现有的多种图像配准算法以及图像配准中的难点。
第四章 图像融合技术
4.1 图像融合技术的基本概念
数字图像融合(Digital Image Fusion)是以图像为主要研究内容的数据融合技术,是把多个不同模式的图像传感器获得的同一场景的多幅图像或同一传感器在不同时刻获得的同一场景的多幅图像合成为一幅图像的过程。由于不同模式的图像传感器的成像机理不同,工作电磁波的波长不同,所以不同图像传感器获得的同一场景的多幅图像之间具有信息的冗余性和互补性,经图像融合技术得到的合成图像则可以更全面、更精确地描述所研究的对象。正是由于这一特点,图像融合技术现已广泛地应用于军事、遥感、计算机视觉、医学图像处理等领域中。
数字图像融合是图像分析的一项重要技术,该技术在数字地图拼接、全景图、虚拟现实等领域有着重要应用。虽然Photoshop等图像处现软件提供了图像处理功能,可以通过拖放的方式进行图像拼接,但由于完全是手工操作,单调乏味,且精度不高,因此,有必要寻找一种方便可行的图像融合方法。Matlab具有强大的计算功能和丰富的工具箱函数,例如图像处理和小波工具箱包含了大多数经典算法,并且它提供了一个非常方便快捷的算法研究平台,可让用户把精力集中在算法上而不是编程上,从而能大大提高研究效率。
4.2 手动配准与图象融合
图像融合包含图像配准和无缝合成两个部分.由于成像时受到各种变形因素的影响,得到的各幅图像间存在着相对的几何差异。图像配准是通过数学模拟来对图像间存在着的几何差异进行校正,把相邻两幅图像合成到同一坐标系下,并使得相同景物在不同的局部图像中对应起来,以便于图像无缝合成。本文采用Matlab中的cpselect、cp2tform函数完成几何配准。cpselect函数显示图像界面,手动在两幅图像的重叠部分选取配准控制点,Matlab自动进行亚像素分析,由cp2tform函数值正重叠部分的几何差异。Matlab中的cp2tform函数能修正6种变形,分别是图(b):线性相似;图(c):仿射;图(d):投影;图(e):多顶式;图(o:分段线性;图(g):局部加权平均。前4种为全局变换,后两种为局部变换,如图I所示,图(a)为修正结果;图(b)至图(g)为对应的变形。

图1-1 cp2tform函数能修正的6种几何变形
图像配准之后,由于图像重叠区域之间差异的存在,如果将图像象素简单叠加,拼按处就会出现明显的拼接缝,因此需要一种技术修正待拼接图像拼接缝附近的颜色值,使之平滑过渡,实现无缝合成。传统的融合方法多是在时间域对图像进行算术运算,没有考虑处理图像时其相应频率域的变化。从数学上讲,拼接缝的消除相当于图像颜色或灰度曲面的光滑连接,但实际上图像的拼接与曲面的光滑不同,图像颜色或灰度曲面的光滑表现为对图像的模糊化,从而导致图像模糊不清。
4.3 图像融合规则
图像的融合规则(Fusion rule)是图像融合的核心,融合规则的好坏直接影响融合图像的速度和质量。
Burt提出了基于像素选取的融合规则,在将原图像分解成不同分辨率图像的基础上,选取绝对值最大的像素值(或系数)作为融合后的像素值(或系数)。这是基于在不同分辨率图像中,具有较大值的像素(或系数)包含更多的图像信息。
Petrovic和Xydeas提出了考虑分解层内各图像(若存在多个图像)及分解层间的相关性的像素选取融合规则。蒲恬在应用小波变换进行图像融合时,根据人类视觉系统对局部对比度敏感的特性,采用了基于对比度的像素选取融合规则。
基于像素的融合选取仅是以单个像素作为融合对象,它并未考虑图像相邻像素间的相关性,因此融合结果不是很理想。考虑图像相邻像素间的相关性,Burt和Kolczynski提出了基于区域特性选择的加权平均融合规则,将像素值(或系数)的融合选取与其所在的局部区域联系起来。
在Lietal提出的融合规则中,其在选取窗口区域中较大的像素值(或系数)作为融合后像素值(或系数)的同时,还考虑了窗口区域像素(或系数)的相关性。Chibani和Houacine在其融合规则中,通过计算输入原图像相应窗口区域中像素绝对值相比较大的个数,决定融合像素的选取。基于窗口区域的融合规则由于考虑相邻像素的相关性,因此减少了融合像素的错误选取。融合效果得到提高。
ZZhang和Blum提出了基于区域的融合规则,将图像中每个像素均看作区域或边缘的一部分,并用区域和边界等图像信息来指导融合选取。采用这种融合规则所得到的融合效果较好,但此规则相对其他融合规则要复杂。对于复杂的图像,此规则不易于实现。
4.4 图像融合方法
迄今为止,数据融合方法主要是在像元级和特征级上进行的。常用的融合方法有HIS融合法、KL变换融合法、高通滤波融合法、小波变换融合法、金字塔变换融合法、样条变换融合法等。下面简要介绍其中的几种方法。
(1) HIS融合法
HIS融合法在多传感器影象像元融合方面应用较广,例如:一低分辨率三波段图象与一高分辨率单波段图象进行 融合处理。这种方法将三个波段的低分辨率的数据通过HIS变换转换到HIS空间,同时将单波段高分辨率图象进行对比度拉伸以使其灰度的均值与方差和HIS空间中亮度分量图象一致,然后将拉伸过的高分辨率图象作为新的亮度分量代入HIS反变换到原始空间中。这样获得的高分辨率彩色图象既具有较高空间分辨率,同时又具有与影象相同的色调和饱和度,有利于目视解译和计算机识别。
(2) KL变换融合法
KL变换融合法又称为主成分分析法。与HIS变换法类似,它将低分辨率的图象(三个波段或更多)作为输入分量进行主成分分析,而将高分辨率图象拉伸使其具有于第一主成分相同的均值和方差,然后用拉伸后的高分辨率影象代替主成分变换的第一分量进行逆变换。高空间分辨率数据与高光谱分辨率数据通过融合得到的新的数据包含了源图象的高分辨率和高光谱分辨率特征,保留了原图象的高频信息。这样,融合图象上目标细部特征更加清晰,光谱信息更加丰富。
(3) 高通滤波融合法
高通滤波融合法将高分辨率图象中的边缘信息提取出来,加入到低分辨率高光谱图象中。首先,通过高通滤波器提取高分辨率图象中的高频分量,然后将高通滤波结果加入到高光谱分辨率的图象中,形成高频特征信息突出的融合影象。
(4) 小波变换融合法
利用离散的小波变换,将N幅待融合的图象的每一幅分解成M幅子图象,然后在每一级上对来自N幅待融合图象的M幅子图象进行融合,得到该级的融合图象。在得到所有M级的融合图象后,实施逆变换得到融合结果。
4.5 图像融合步骤
目前国内外己有大量图像融合技术的研究报道,不论应用何种技术方法,必须遵守的基本原则是两张或多张图像上对应的每一点都应对位准确。由于研究对象、目的不同,图像融合方法亦可多种多样,其主要步骤归纳如下:
(1) 预处理:对获取的两种图像数据进行去噪、增强等处理,统一数据格式、图像大小和分辨率。对序列断层图像作三维重建和显示,根据目标特点建立数学模型;

SHAPE \* MERGEFORMAT
图3-1 图像融合步骤示意图
(2) 分割目标和选择配准特征点:在二维或三维情况下,对目标物或兴趣区进行分割。选取的特点应是同一物理标记在两个图像上的对应点,该物理标记可以是人工标记,也可以是人体解剖特征点;
(3 )利用特征点进行图像配准:可视作两个数据集间的线性或非线性变换,使变换后的两个数据集的误差达到某种准则的最小值;
(4) 融合图像创建:配准后的两种模式的图像在同一坐标系下将各自的有用信息融合表达成二维或三维图像;
(5) 参数提取:从融合图像中提取和测量特征参数,定性、定量分析
4.6 本章小结
本章主要介绍了图像融合的概念,方法以及步骤。
第五章 图像拼接matlab实现
5.1 Matlab简介
MATLAB 的名称源自 Matrix Laboratory ,它是一种计算软件,专门以矩阵的形式处理数据。 MATLAB 将高性能的数值计算和可视化集成在一起,并提供了大量的内置函数,从而被广泛地应用于科学计算、控制系统、信息处理等领域的分析、仿真和设计工作,而且利用 MATLAB 产品的开放式结构,可以非常容易地对 MATLAB 的功能进行扩充,从而在不断深化对问题认识的同时,不断完善 MATLAB 产品以提高产品自身的竞争能力。
Matlab语言有如下特点: 1.编程效率高 它是一种面向科学与工程计算的高级语言,允许用数学形式的语言编写程序,且比Basic、Fortran和C等语言更加接近我们书写计算公式的思维方式,用Matlab编写程序犹如在演算纸上排列出公式与求解问题。Matlab编写简单,所以编程效率高,易学易懂。 2.用户使用方便 Matlab语言是一种解释执行的语言(在没被专门的工具编译之前),它灵活、方便,其调试程序手段丰富,调试速度快,需要学习时间少。人们用任何一种语言编写程序和调试程序一般都要经过四个步骤:编辑、编译、连接以及执行和调试。各个步骤之间是顺序关系,编程的过程就是在它们之间作瀑布型的循环。
3.扩充能力强
高版本的Matlab语言有丰富的库函数,在进行复杂的数学运算时可以直接调用,而且Matlab的库函数同用户文件在形成上一样,所以用户文件也可作为Matlab的库函数来调用。
4.语句简单,内涵丰富
Mat1ab语言中最基本最重要的成分是函数,其一般形式为[a,6,c……] = fun(d,e,f,……),即一个函数由函数名,输入变量d,e,f,……和输出变量a,b,c……组成,同一函数名F,不同数目的输入变量(包括无输入变量)及不同数目的输出变量,代表着不同的含义(有点像面向对象中的多态性。。 5.高效方便的矩阵和数组运算 Matlab语言象Basic、Fortran和C语言一样规定了矩阵的算术运算符、关系运算符、逻辑运算符、条件运算符及赋值运算符,而且这些运算符大部分可以毫无改变地照搬到数组间的运算,有些如算术运算符只要增加"·"就可用于数组间的运算,另外,它不需定义数组的维数,并给出矩阵函数、特殊矩阵专门的库函数,使之在求解诸如信号处理、建模、系统识别、控制、优化等领域的问题时,显得大为简捷、高效、方便,这是其它高级语言所不能比拟的。
6.方便的绘图功能
Matlab的绘图是十分方便的,它有一系列绘图函数(命令),例如线性坐标、对数坐标,半对数坐标及极坐标,均只需调用不同的绘图函数(命令),在图上标出图题、XY轴标注,格(栅)绘制也只需调用相应的命令,简单易行。另外,在调用绘图函数时调整自变量可绘出不变颜色的点、线、复线或多重线。这种为科学研究着想的设计是通用的编程语言所不及的。
总之,Matlab语言的设计思想可以说代表了当前计算机高级语言的方向。我们相信,在不断使用中,读者会发现它的巨大潜力。因此本文采用matlab来实现本文的算法。
5.2 各算法程序
5.2.1 一般方法
图像融合是通过一个数学模型把来自不同传感器的多幅图像综合成一幅满足特定应用需求的图像的过程,从而可以有效地把不同图像传感器的优点结合起来,提高对图像信息分析和提取的能力。简单的图像融合方法不对参加融合的源图像进行任何变换和分解,而是直接对源图像中的各对应像素分别进行选择、平均或加权平均、多元回归或其它数学运算等处理后,最终合成一幅融合图像。
对于图像融合的对象,可以分为两大类,即多光谱图像(通常为RGB彩色图像)与灰度图像之间的融合,以及灰度图像之间的融合。灰度图像之间的融合,在大体上可分为三大类。一类是简单融合方法,包括将空间对准的两幅图像直接求加权平均值。另一类方法是基于金字塔形分解和重建算法的融合方法,主要包括梯度金字塔法、对比度和比率金字塔法以及拉普拉斯金字塔法等,它们首先构造输入图像的金字塔,再按一定的特征选择方法取值形成融合金字塔,通过对金字塔实施逆变换进行图像重建,最终生成融合图像,它们的融合效果要远优于第一类方法,然而它也有很多不尽如人意的地方。还有一类方法就是近几年兴起的基于小波变换的图像融合方法,它通常采用多分辨分析和Mallat快速算法,通过在各层的特征域上进行有针对性的融合,比较容易提取原始图像的结构信息和细节信息,所以融合效果要好于基于金字塔形变换的图像融合法。这是因为小波变换更为紧凑;小波表达式提供了方向信息,而金字塔表达式未将空间方向选择性引入分解过程;由于可以选择正交小波核,因此不同分辨率包含的信息是唯一的,而金字塔分解在两个不同的尺度之间含有冗余,另外金字塔不同级的数据相关,很难知道两级之间的相似性是由于冗余还是图像本身的性质引起的;金字塔的重构过程可能具有不稳定性,特别是两幅图像存在明显差异区域时,融合图像会出现斑块,而小波变换图像融合则没有类似的问题。此外,小波变换具function Y = fuse_pca(M1, M2)
%Y = fuse_pca(M1, M2) image fusion with PCA method
%
% M1 - input image #1
% M2 - input image #2
%
% Y - fused image
% (Oliver Rockinger 16.08.99)
% check inputs
[z1 s1] = size(M1);
[z2 s2] = size(M2);
if (z1 ~= z2) | (s1 ~= s2)
error('Input images are not of same size');
end;
% compute, select & normalize eigenvalues
[V, D] = eig(cov([M1(:) M2(:)]));
if (D(1,1) > D(2,2))
a = V(:,1)./sum(V(:,1));
else
a = V(:,2)./sum(V(:,2));
end;
% and fuse
Y = a(1)*M1 a(2)*M2;
5.2.3 金字塔(Pyramid)算法程序
金字塔图像融合法:用金字塔在空间上表示图像是一种简单方便的方法。概括地说金字塔图像融合法就是将参加融合的每幅源图像作金字塔表示,将所有图像的金字塔表示在各相应层上以一定的融合规则融合,可得到合成的金字塔。将合成的金字塔,用金字塔生成的逆过程重构图像,则可得到融合图像。金字塔可分为:Laplacian金字塔、Gaussian金字塔、梯度金字塔、数学形态金字塔等。
基于FSD Pyramid的图像融合算法程序:
function Y = fuse_fsd(M1, M2, zt, ap, mp)
%Y = fuse_fsd(M1, M2, zt, ap, mp) image fusion with fsd pyramid
%
% M1 - input image A
% M2 - input image B
% zt - maximum decomposition level
% ap - coefficient selection highpass (see selc.m)
% mp - coefficient selection base image (see selb.m)
%
% Y - fused image
% (Oliver Rockinger 16.08.99)
% check inputs
[z1 s1] = size(M1);
[z2 s2] = size(M2);
if (z1 ~= z2) | (s1 ~= s2)
error('Input images are not of same size');
end;
% define filter
w = [1 4 6 4 1] / 16;
% cells for selected images
E = cell(1,zt);
% loop over decomposition depth -> analysis
for i1 = 1:zt
% calculate and store actual image size
[z s] = size(M1);
zl(i1) = z; sl(i1) = s;
% check if image expansion necessary
if (floor(z/2) ~= z/2), ew(1) = 1; else, ew(1) = 0; end;
if (floor(s/2) ~= s/2), ew(2) = 1; else, ew(2) = 0; end;
% perform expansion if necessary
if (any(ew))
M1 = adb(M1,ew);
M2 = adb(M2,ew);
end;
% perform filtering
G1 = conv2(conv2(es2(M1,2), w, 'valid'),w', 'valid');
G2 = conv2(conv2(es2(M2,2), w, 'valid'),w', 'valid');
% select coefficients and store them
E(i1) = {selc(M1-G1, M2-G2, ap)};
% decimate
M1 = dec2(G1);
M2 = dec2(G2);
end;
% select base coefficients of last decompostion stage
M1 = selb(M1,M2,mp);
% loop over decomposition depth -> synthesis
for i1 = zt:-1:1
% undecimate and interpolate
M1T = conv2(conv2(es2(undec2(M1), 2), 2*w, 'valid'), 2*w', 'valid');
% add coefficients
M1 = M1T E{i1};
% select valid image region
M1 = M1(1:zl(i1),1:sl(i1));
end;
% copy image
Y = M1;
.2 .4 小波变换(DWT)算法程序
在众多的图像融合技术中,基于小波变换的图像融合方法已成为现今研究的一个热点。这类算法主要是利用人眼对局部对比度的变化比较敏感这一事实,根据一定的融合规则,在多幅原图像中选择出最显著的特征,例如边缘、线段等,并将这些特征保留在最终的合成图像中。在一幅图像的小波变换中,绝对值较大的小波系数对应于边缘这些较为显著的特征,所以大部分基于小波变换的图像融合算法主要研究如何选择合成图像中的小波系数,也就是三个方向上的高频系数,从而达到保留图像边缘的目的。虽然小波系数(高频系数)的选择对于保留图像的边缘等特征具有非常主要的作用,但尺度系数(低频系数)决定了图像的轮廓,正确地选择尺度系数对提高合成图像的视觉效果具有举足轻重的作用。
基于SIDWT(Shift Invariance Discrete Wavelet Transform)小波变换的算法程序:
function Y = fuse_sih(M1, M2, zt, ap, mp)
%Y = fuse_sih(M1, M2, zt, ap, mp) image fusion with SIDWT, Wavelet is Haar
%
% M1 - input image A
% M2 - input image B
% zt - maximum decomposition level
% ap - coefficient selection highpass (see selc.m)
% mp - coefficient selection base image (see selb.m)
%
% Y - fused image
% (Oliver Rockinger 16.08.99)
% check inputs
[z1 s1] = size(M1);
[z2 s2] = size(M2);
if (z1 ~= z2) | (s1 ~= s2)
error('Input images are not of same size');
end;
% cells for selected images
E = cell(3,zt);
% loop over decomposition depth -> analysis
for i1 = 1:zt
% calculate and store actual image size
[z s] = size(M1);
zl(i1) = z; sl(i1) = s;
% define actual filters (inserting zeros between coefficients)
h1 = [zeros(1,floor(2^(i1-2))), 0.5, zeros(1,floor(2^(i1-1)-1)), 0.5, zeros(1,max([floor(2^(i1-2)),1]))];
g1 = [zeros(1,floor(2^(i1-2))), 0.5, zeros(1,floor(2^(i1-1)-1)), -0.5, zeros(1,max([floor(2^(i1-2)),1]))];
fh = floor(length(h1)/2);
% image A
Z1 = conv2(es(M1, fh, 1), g1, 'valid');
A1 = conv2(es(Z1, fh, 2), g1','valid');
A2 = conv2(es(Z1, fh, 2), h1','valid');
Z1 = conv2(es(M1, fh, 1), h1, 'valid');
A3 = conv2(es(Z1, fh, 2), g1','valid');
A4 = conv2(es(Z1, fh, 2), h1','valid');
% image B
Z1 = conv2(es(M2, fh, 1), g1, 'valid');
B1 = conv2(es(Z1, fh, 2), g1','valid');
B2 = conv2(es(Z1, fh, 2), h1','valid');
Z1 = conv2(es(M2, fh, 1), h1, 'valid');
B3 = conv2(es(Z1, fh, 2), g1','valid');
B4 = conv2(es(Z1, fh, 2), h1','valid');
% select coefficients and store them
E(1,i1) = {selc(A1, B1, ap)};
E(2,i1) = {selc(A2, B2, ap)};
E(3,i1) = {selc(A3, B3, ap)};
% copy input image for next decomposition stage
M1 = A4;
M2 = B4;
end;
% select base coefficients of last decompostion stage
A4 = selb(A4,B4,mp);
% loop over decomposition depth -> synthesis
for i1 = zt:-1:1
% define actual filters (inserting zeros between coefficients)
h2 = fliplr([zeros(1,floor(2^(i1-2))), 0.5, zeros(1,floor(2^(i1-1)-1)), 0.5, zeros(1,max([floor(2^(i1-2)),1]))]);
g2 = fliplr([zeros(1,floor(2^(i1-2))), 0.5, zeros(1,floor(2^(i1-1)-1)), -0.5, zeros(1,max([floor(2^(i1-2)),1]))]);
fh = floor(length(h2)/2);
% filter (rows)
A4 = conv2(es(A4, fh, 2), h2', 'valid');
A3 = conv2(es(E{3,i1}, fh, 2), g2', 'valid');
A2 = conv2(es(E{2,i1}, fh, 2), h2', 'valid');
A1 = conv2(es(E{1,i1}, fh, 2), g2', 'valid');
% filter (columns)
A4 = conv2(es(A4 A3, fh, 1), h2, 'valid');
A2 = conv2(es(A2 A1, fh, 1), g2, 'valid');
% add images
A4 = A4 A2;
end;
% copy image
Y = A4;
5.3实验结果
下面将本文的算法用于多聚焦图像的融合。多聚焦图像指的是对相同的场景用不同的焦距进行拍摄,得到镜头聚焦目标不同的多个图像。经过图像融合技术后,就可以得到一个所有目标都聚焦清晰的图像。图5-1中左边的目标较为清晰,图5-2中右边的目标较为清晰。

图5-1 聚焦在左边的图像

图5-2 聚焦在右边的图像
我们分别利用基于PCA的算法、金字塔图像融合法和小波变换法的算法程序得到的的融合图像结果,如图5-3、图5-4、图5-5所示

图5-3 基于PCA算法的融合图像

图5-4 基于金字塔图像融合算法的融合图像

图5-5 基于SIDWT小波变换的融合图像
从实验结果可以看出,三种方案都可以得到较满意的视觉效果,消除了原图像的聚焦差异,提高了图像的清晰度,在合成图像中左、右两边的目标都很清晰。但通过比较分析,我们可以看出基于小波变换的融合图像(图5-5)最为清晰,所表现的图像细节效果最好,重影现象消除得最干净。图5-3的清晰度不够,而图5-4的细节表现力较弱,只有图5-5的边缘最清晰,重影消除地最干净,细节得到了最好地保留。
第六章 与展望
6.1 本工作的总结
图像拼接技术一直是机视觉、图像处理和计算机图形学的热点研究方向。它可以用来建立大视角的高分辨率图像,在虚拟现实领域、医学图像处理领域、遥感技术领域和军事领域中均有广泛的应用。
本文总结了前人在图像拼接领域的研究成果和研究现状,按照图像拼接的流程(图像预处理、图像配准和图像融合),详细介绍了图像拼接技术,主要完成的工作有:(1)图像预处理主要指对图像进行几何畸变校正和噪声点的抑制等,让图像和待拼接图像不存在明显的几何畸变。
(2)图像配准主要指对参考图像和待拼接图像中的匹配信息进行提取,在提取出的信息中寻找最佳的匹配,完成图像间的对齐。图像配准是图像拼接技术中的核心部分。本文分析了现有的多种图像配准算法。
(3)图像融合指在完成图像匹配以后,对图像进行缝合,并对缝合的边界进行平滑处理,让缝合过渡。
(4)论文的最后简要介绍了利用matlab实现的图像拼接软件,该软件实现了本文讨论到的所有方法。
6.2展望
经过3个月的研究,本文对图像拼接技术的研究涉及到了现有图像拼接领域的大多方法。但对于这一研究领域来说,本文所作的工作只是沧海一粟。事实上,还有很多图像拼接问题值得去研究和解决,由于时间的关系,本文没有做进一步的研究。
根据图像拼接技术的研究体会,本人认为以下几个方面有待于进一步研究:
(1)本文的图像拼接算法的研究,是基于两幅图像间重叠区域并不存在运动的物体的假设的。但是在有些情况下,待拼接的图像采集过程中,会有运动的物体出现。如果在重叠区域存在运动物体的情况下,如何消除运动物体对拼接图像带来的影响例如,两幅图像因为重叠区域的运动物体,在合成的图像中该区域出现重影),是需要进一步研究的问题。
(2)本文讨论的图像拼接算法,并不是针对特定图像的研究。但是,图像拼接在用于实际应用的时候,有时是针对某一特定的图像。如何通过特定目标的特征从图像中提取出特定目标(例如,人脸、足球),以此来帮助完成图像拼接,这需要加深对图像中特定目标的理解和分割。因此,如何更好的理解图像,分割出特定图像中的目标物体,通过特征物体的配准来完成图像拼接,是一个可以重点研究的方向。
,




