第2章 C语言编程基础
本章重点
· C语言基本数据类型
· 常量
· 变量
· 类型转换
在开发C语言程序时,需要掌握一些基本语法,如变量的定义、常量的定义、类型转换等,本章将针对这些知识进行详细地讲解。
认识二进制
二进制是计算技术中广泛采用的一种。据是用0和1两个来表示的数。它的基数为2,进位规则是"逢二进一",借位规则是"借一当二",由18世纪德国数理哲学大师发现。当前的使用的基本上是,数据在计算机中主要是以补码的形式存储的。计算机中的二进制则是一个非常微小的开关,用"开"来表示1,"关"来表示0。
1. 十进制与二进制之间的转换
一个十进制数1024对应的二进制表示为100 0000 0000(为便于阅读,在每四位数之间以一个空格进行分隔)。该如何转换呢?
首先以简单的4位二进制数为例:假设有4个bit,每一个bit的值是0或1,这样一共可以表示24=16个不同的二进制数:
表 2‑1 4位二进制数
把4位二进制数从右到左分别称为第0到3位。根据之前介绍的二进制表示规则,第0位的1表示1个20=1,第1位的1表示1个21=2,第2位的1表示1个22=4,第3位的1表示1个23=8,据此可以写出这16个二进制数所对应的十进制值。以二进制的1101为例,它对应的十进制整数是8 4 1=13,如图2-1所示:

图 2‑1 二进制到十进制的转换示意
下表为4位二进制数到十进制数的转换表。
表 2‑2 4位二进制数和十进制数
(多学一招:负整数的补码表示法
大家已经知道了如何用二进制表示一个正整数,那么二进制又是如何表示负整数的呢?一个很自然的想法是利用最高位来表示符号位,然后利用剩下的bit来表示绝对值。以4位二进制数为例:如果规定最高位用0表示正整数,用1表示负整数的话,16个4位二进制数的值分别是:
表 2‑3 4位二进制数和十进制数
很可惜,这样的表示方法有几个问题:首先,0的表示不唯一;更麻烦的是算术运算变得更加复杂了。以加法为例:当把两个带符号整数相加的时候,如果两个数的符号相同,那么结果的符号不变,绝对值是这两个数的绝对值相加;如果两个数的符号相反,那么把两个数的绝对值相减(大减小),并取绝对值较大的加数的符号作为结果的符号。这样一次简单的加法操作涉及到了多次判断,比大小,甚至是减法。
出于上述考虑,计算机中采用补码来表示负整数。补码表示法不是很直观,但是简化了算术运算。以4位二进制数举例:在补码中,第0到2位的1含义和之前一样,分别表示1,2和4,但是第3位的1表示的不是8,而是-8:
表 2‑4 4位二进制补码和十进制数
以上表中的1010为例:第1位的1表示1个2,第3位的1表示1个-8,所以合起来1010就表示-8 2=-6。可以试着选0111(7)和1111(-1)做加法,看看能否得到0110。
现在大家已经知道了如何从一个二进制正整数算出对应的十进制正整数,那么,如果给定一个十进制正整数,怎样得到它对应的二进制数呢?通常采用的方法是除二取余法:把正整数不断除以2,将每次得到的余数连起来再逆序,就是对应的二进制表示。下面仍以十进制的13为例:
1. 13除以2得6,余数是1;
2. 6除以2得3,余数是0;
3. 3除以2得1,余数是1;
4. 1除以2得0,余数是1;
所以13的二进制表示就是1101。
(多学一招:负整数的补码表示法
比求正整数二进制表示更加困难的是如何从负整数求出对应的二进制补码。在这里以-3为例,求解对应的4位二进制补码:
1. 求绝对值的二进制表示:3的二进制表示是0011;
2. 按位取反:0变1,1变0,得到1100;
3. 加1:1100 1=1101。这就是-3的补码。
可以仿照上述过程求解负整数的补码。
(脚下留心:计算机究竟是存储十进制数,还是存储二进制数?
大家都会有这样的疑问:"讲了十进制数,又讲了二进制数,虽然知道计算机运算时用的是二进制数,但它存储的时候是存储十进制数呢,还是二进制数呢?"要解答这个问题,关键在于理解"数"和"数的表示"之间的区别。
对于一个数而言,在不同表示法下长的样子可能是不一样的。以上文讲的13为例,在十进制表示法下由两位数"1"和"3"组成,而在二进制表示法下由四位数"1""1""0"和"1"组成。尽管这两种表示法看上去不同,但是它们的值是相同的,仍然表示同一个数。
因此计算机存储的既不是十进制数,也不是二进制数——计算机存储的是数值本身;运算时是基于二进制的;至于显示到屏幕上时究竟是显示成十进制还是二进制,这就由大家写的程序决定了。
2.二进制的扩展:八进制与十六进制
除十进制和二进制以外,还有两种在程序中经常使用的进制:八进制和十六进制。所谓八进制就是用0到7组成的数字,每一位的大小分别是1,8,64,512等等。比如八进制的156换算成十进制就是1个64,加上5个8,加上6个1:64 40 6=110。
八进制和二进制之间有十分简单的转换关系:对于八进制数,只要将每一位都按照下表翻译成3位二进制数,并将它们连接在一起即可:
表 2‑5 二进制数和八进制数
举例来说,八进制数156换算成二进制就应该是:001 101 110,也就是1101110,试着将它转换成十进制数:2 4 8 32 64=110,和八进制数一致。
反过来要将二进制数转换成八进制数也很简单:只要将二进制数3个一组,按照上表翻译成对应的八进制数码即可:比如下面这个16位的二进制数:
1001 1100 1010 1011
首先按照3个一组进行分组:
1 001 110 010 101 011
接着将它们转换成对应的八进制数字:
1 1 6 2 5 3
所以对应的八进制数就是116253。可以验证它们的十进制值都是40107。
除了八进制,在程序中更加常用的是十六进制。十六进制用0到9,A到F分别表示0到15这16个值,每一位的大小分别是1,16,162=256等等。每一位表示的分别是160,161,162等等。
表 2‑6 二进制数和十六进制数
二进制和十六进制的转换同二进制和八进制的转换非常类似:只要将二进制数4个一组按照上表进行转换即可。用十六进制替代二进制的一个好处就是书写非常方便。比如一个32位的int类型整数:
0111 1101 1010 1010 0011 0110 1100 1001
转换成对应的16进制整数就是:0x7DAA36C9。它的十进制大小是2108307145
(多学一招:利用windows计算器进行进制转换
Windows 自带的计算器可以方便地实现进制转换的功能,这里以Windows 7上的计算器为例进行简单介绍。按住键盘上的windows键(一般在空格键左侧,带有windows图标) R,输入calc,可以快速启动计算器,如图2-2所示:

图 2‑2 快速启动计算器
启动计算器之后,在"查看"菜单下面找到"程序员",就可以进入专为程序员设计的计算器界面:

图 2‑3 计算器的程序员界面
图2-3中注意到左侧的进制选项,可以分别选择十六进制、八进制、十进制和二进制。选择十进制,并输入一个十进制整数,就可以在数字下方看到它的32位bit表示,选择相应的进制就可以得到进制转换的结果。
(多学一招:如何将八进制和十六进制数转换成十进制?
上文介绍了如何在二进制和八进制、十六进制之间进行转换,那要如何将八进制和十六进制数转换为十进制呢?思路很简单:先将它们转换成二进制数,再根据前文中讲过的二进制到十进制的转换方法转换到十进制数即可。
例如对于十六进制数0xD53A,要转换成十进制数的话需要经过以下过程:
0xD53A = 1101 0101 0011 1010 (二进制) = 54586 (十进制)
八进制数04255,要转换成十进制数的话需要这样做:
04255 = 1000 1010 1101 = 2221
3.有符号数和无符号数
有符号数就是用最高位表示符号(正或负),其余位表示数值大小。比如: 0011 表示 3; 1011 表示 -3。 无符号数全部二进制均代表数值,没有符号位。即第一个"0"或"1"不表示正负。比如: 0011 表示 3; 1011 表示 11。 C支持所有整型数据类型的有符号数和无符号数运算。尽管C标准并没有指定某种有符号数的表示,但是几乎所有的机器都使用二进制补码。通常,大多数数字默认都使有符号的,C也允许无符号数和有符号数之间的转换,当执行一个运算时,如果它的一个运算数是有符号的而另一个是无符号的,那么C会隐含地将有符号参数强制转换为无符号数,并假设这两个数都是非负的,来执行这个运算。
基本数据类型
C语言为大家提供了不同种类的基本数据类型,其中包括整数类型、实型类型、字符类型等等,每一种数据类型用途都是不一样的,本节将针对C语言基本数据类型的相关知识进行详细地讲解。
2.1.1 整数类型
顾名思义,整数类型就是用来保存整数的数据类型。C语言中基本的整数类型为int,一般长度为4个字节,即32位二进制数。
4在int的基础上,C语言还提供了short int、long int和long long int三种整型数据类型,这三种类型名称中的int都可以省略不写,即略写为short、long与long long。这几种类型都是用来保存整数的,除了名字不同之外,还有什么区别呢?顾名思义,"short"意味着短,"long"意味着长,用来存储数字的空间越大,能存储的最大数值就越大。因此一般而言,short型变量能存储的最大数值要比int型变量能存储的最大数值小,而long long型变量能存储的最大数值是最大的。
C语言标准中并没有明确规定以上四种整型数据类型的长度,因此它们的长度由编译器自行决定。大家可以利用C语言提供的sizeof运算符查看自己计算机上这四种整型数据的长度。sizeof运算符接受数据类型的名称,返回以字节为单位的该数据类型的长度。
在Visual Studio中新建一个工程,复制以下代码:
例程 2‑1 查看数据类型的长度
1 /* DataTypeLength Project */
2 #include <stdio.h>
3 int main()
4 {
5 printf("%d\n", sizeof(int));
6 return 0;
7 }
程序的运行结果如图2-5所示:

图 2‑5 int的长度
编译运行该工程后,输出的结果是电脑上int型变量的长度。可以将sizeof后面的int换成short,long和long long分别试验,输出的结果就是对应数据类型的长度。
尽管C语言标准中没有明确规定整型数据的长度,但是有如下要求:首先,short型变量的长度必须不短于2个字节,long型变量的长度不短于4个字节;其次是几种数据类型的相对长度:

在64位计算机系统上利用VS编译上述例程后,得到的以上各种数据类型的长度如下表所示,供大家参考,如表2-7所示:
表 2‑7整型数据的长度的一些参考值
现在大家清楚了,C语言能够理解如下几种整数类型:short、int、long和long long。对于short,计算机会准备2个字节来保存;对于int,计算机会准备4个字节,对于long long,计算机会准备8个字节。接下来第二个问题一定是:4个字节的int究竟能表示多大的整数?
要搞清楚这个问题,从十进制数开始分析。如果有人问:"3位的十进制数可以表示的最大整数是多少?"大家一定会很轻松地回答999,因为对十进制太熟悉了。
遗憾的是,计算机使用的是二进制。下面换一个问法:"32位(4字节)的二进制数可以表示的最大整数是多少?"直觉上,答案应该是下面这个数:
1111 1111 1111 1111 1111 1111 1111 1111
一共32位,每一位都取成最大值1,应该就是32位二进制能表示的最大整数了吧?因为是二进制,每一位只能取0或者1,所以就取成1吧!
这个数大概是十进制的40亿。然而,40亿并不是int能够表示的最大整数——int的最高位被用来区别要表示的数是正数还是负数了,所以实际上int能够表示的最大整数是:
0111 1111 1111 1111 1111 1111 1111 1111
这个数大概是20亿。int能够表示的最小负数大概也是负20亿,所以现在应该有这样的概念:对于正负20亿以内的数,用int来表示就足够了(这句话的意思是说:4个字节就已经够表示这个数了,没有必要用8个字节的long long,多了也浪费是不是?)。下面的表格列出了这几种数据类型能够表示的范围,供需要的时候对照:
表 2‑8 各种整型的表示范围
大家可能已经注意到了int的最高位被用来表示正负数了,如果能够保证不使用负数的话(比如说,定义一个整数来表示人的体重,体重总不可能取到负数的),那最高位不就没什么用了吗?对于这种情况,C中提供了4种非负类型的整数,称为无符号整型:
表 2‑9 各种无符号整型的长度和表示范围
无符号整型看上去很简单,只是在之前的数据类型前面加了一个unsigned,而且不改变字节数。不过,无符号整型只能表示非负整数了,但是非负整数的范围比原来的有符号整型要大,这是非常合理的:因为之前用来表示符号的最高位被用来存储数字。
在本小节结束对整型的讨论之前,还有最后一个疑问:
"如果定义的数超出了范围会怎么样?"
如果对计算机说:
"定义一个short类型的整数,这个整数的值是70000。"
计算机查看了一下上面的几张表,"short类型,要准备2个格子……70000……等一下70000?好像超出范围了……"这个时候计算机会崩溃吗?它不会那么脆弱的,只不过它会对输入的70000做一些偷工减料的处理,从而把它塞到2个字节当中(当然,处理之后的这个数肯定不会是70000了)。具体的做法将在后文中讲解。

图 2‑6 向short型变量中存入70000
小结一下:计算机用2/4/8个字节来表示一个有符号或者无符号的整数,不同的整数类型有不同的范围,大家可以根据想要表示的数选择合适的整数类型,如果想表示的值溢出了,计算机会自己偷偷做一些改动。
(多学一招:int类型的表示范围
int一共包含32位,其中最高位可以区别正负,0表示正数,1表示负数,所以int型变量能够表示的最大正整数应该是:
0111 1111 1111 1111 1111 1111 1111 1111
将这个数换算成十进制就是230 229 228 …… 20=231-1=2147483647,这就是int能够表示的最大整数。
2.1.2 实型类型
实型数据是由整数部分和小数部分组成。除了正确地表示整数之外,还需要利用二进制正确地表示小数。小数的表示要复杂一些,但是思路和整数是一样的:C语言提供了两种类型,分别是浮点型float和双精度浮点型double,float用4个字节,double用8个字节来表示小数,它们也都有各自能表示的范围。
表 2‑10 浮点数的表示范围
当然这里有几个问题需要注意:首先,和整数不一样,小数可能有无限多个,但是由于只有有限个字节,所以有些小数是注定无法准确表示的。比如:

这是一个无限循环小数,程序是没办法用32位或者64位空间来精确表示的——因为它有无限多位。此外,有些看上去很简单的十进制小数也没有办法用float和double来表示,比如0.6。这是由于十进制和二进制之间的转换方式导致的,所以很遗憾,在表示浮点数的时候,最好不要假设浮点数能够被计算机精确地表示。
在Visual Studio中新建一个C工程,如例程2-2所示:
例程 2‑2 浮点数0.6
8 /* float Project */
9 #include <stdio.h>
10 int main()
11 {
12 float f = 0.6f;
13 printf("%.10f\n", f);
14 return 0;
15 }
程序的运行结果如图2-7所示:

图 2‑7 浮点数0.6
例程2-2中程序做了如下几件事情:
定义了一个float类型的数,值为0.6(后面的f只是为了表示这个数是float类型,不影响0.6的值);
在屏幕上输出这个数小数点后10位的值。
运行程序,会发现得到的值是0.6000000238。计算机对于精确表示0.6无能为力,所以它只能尽量做到最好,用一个它能表示的最接近的值来代替0.6。
除了无法精确表示小数,浮点数表示的数是有下限的。对于float来说,10的负38次方是它所能表示的极限,这意味着比这个数量级更小的正数,如1e-100,float是无法表示的(不过0可以精确表示的),这也是由于浮点数的表示方式导致的。
小结:C语言中用4个字节的float或者8个字节的double来表示一个浮点数,但是不一定能精确地表示想要的小数。此外,不要用float或者double去表示特别特别大,或特别特别小的数。当然大部分情况下,float和double提供的范围已经够用了。另外,float和double也可以表示整数,毕竟,整数也是一种"小数",只不过小数部分为0。遗憾的是,对于一部分特别大的整数,即使这个整数在浮点数能够表示的范围之内,float和double也不能保证精确地表示。总之,在使用浮点数时,在任何情况下都不要假设提供的数被精确表示了——除非完全明白浮点数的表示方法。
2.1.3 字符类型
除了表示整数和浮点数,C语言中还需要表示的一类数据就是字符。最常见的字符就是英文字母了,假设现在对本章开头那台高度智能的计算机说:
"定义一个英文字母A。"
对于计算机来说,它只懂二进制,它只知道为大家想要的值分配几个小格子(字节),然后在每个格子里面填上8个0或者1。它是无法直接理解英文字母的。这时候就需要有人告诉计算机一个对应关系:
"存一个英文字母A的时候,就分配一个小格子给它,然后在里面存一个十进制数65。"
大体上,计算机就是这样存储字符的。这种用来存储字符的数据类型叫做char,翻译成中文字符型,长度为一个字节。一张名为"ASCII码表"的表格负责把常见的字符对应到一个字节长的整数:把A对应到65,B对应到66,C对应到67,空格键对应到32,a对应到97,等等。计算机每次碰到一个字符的时候,就去ASCII码表当中去查对应的整数,然后把这个整数存起来,于是字符就被保存下来了。当需要使用这个字符的时候,计算机就把格子里的整数取出来,然后查ASCII码表,找到对应的字符。下表是常见字符到ASCII编码的对应。完整的ASCII码表请参照下一节中,如表2-11所示:
表 2‑11 常见字符的ASCII码
大家肯定已经意识到了,既然只用一个格子来表示字符,而一个格子能表示的数肯定很少(其实只有256个),所的这张ASCII码表应该也很短,能表示的字符也很少。确实是这样,而且它比想象的还要短——基本ASCII码表里面只有128个字符,但是对英文来说这已经够用了。
根据上面的描述,char类型本质上就是长度为一个字节的整数,所以它也可以像int和short那样用来保存整数,也可以在前面加上unsigned变成unsigned char来保存无符号整数。请看下面的例子:
在Visual Studio中新建一个C工程,如例程2-3所示:
例程 2‑3 ASCII码与字符
1 /* ASCII Project */
2 #include <stdio.h>
3 int main()
4 {
5 char ch = 'A';
6 printf("%c %d\n", ch, ch);
7 return 0;
8 }
程序的运行结果如图2-8所示:

图 2-8 ASCII字符
例程2-3中首先定义了一个char类型的英文字母A,然后用两种形式输出:%c把ch看成是字符输出,%d把ch看成是整数输出。最后输出的结果分别是A和65。
可以试着把第一句改成
char ch = 65;
重新编译并运行发现结果是一样的。这说明对于char来说,A和65其实没什么区别。
(多学一招:为什么计算机要采用二进制
大家可能会奇怪,和十进制相比,二进制表示同样的数要占用更多的位数,对使用者来说也更加不直观,为什么计算机还要选择采用二进制来存储和运算呢?这是因为计算机中实际上是以电子元件的状态来保存数据的。具有两种稳定状态(如电压的高与低,二极管的通与断)的电子元件是很容易制造的,因此使用二进制来保存数据就顺理成章了。如果计算机要使用十进制,就意味着在不增加电子元件数量的前提下,每一个元件需要有十种稳定的状态来对应表示0到9这十种可能的值,这比直接使用二进制要困难多了。
通过上一小节的学习,大家应该对C语言中的基本数据类型有了一些基本的认识。同时,也看到了很多的例子中都有这种语句:
float f = 0.6f;
char ch = 'A';
这些语句就在让计算机定义一个浮点数/字符。当然也可以让计算机定义一个整型,比如:
int a = 30;
这行语句就完成了之前的要求:"定义一个整数30"。为了完成这项工作,大家需要让计算机清楚这几件事情:
1. 要定义的是什么样的数据类型,把它写在开头,比如:
int a = 30;
首先告诉计算机:"定义一个int类型的整数"。计算机(其实是编译器)看到int之后,就在它所有的信箱中找出4个空闲的格子(4个字节),准备存放要定义的int。
2. 要给大家的信箱起一个名字
如果楼道口的信箱上没有各家的门牌号,那么所有的信箱看起来就完全一样了,邮递员就无法得知应该把信投到哪个信箱里。类似地,当在第一步中认领了4个格子之后,也要为这4个格子起一个名字,不然计算机就不知道到哪一个格子当中去存放和寻找要保存的整数;在这里,例程起了个很简单的名字:a;
3. 把信件放进信箱(告诉计算机要定义的整数是多少)
在这里大家想要定义一个整数30,就把它写在等号的右边。在C语言中,"="是一种赋值运算符,它表示把右边的数存到左边的格子里。在这个例子中,只要把30这个值存到a所在的4个格子当中,整个工作就完成了!

图 2‑9 定义变量并赋初始值
本节将重点介绍第三步中等号右边的"0.6f"和"30"这样的量怎么写,这些量被称为常量——计算机是按一定规则办事的,它不像人那么高端,能够理解各种自然语言。比如人与人之间可以说:
"定义一个整数10的5次方。"
理解起来毫无问题,但是如果和计算机说:
int a = 10的5次方;
那么很遗憾,计算机是不能理解等号右边这个值的。
即使换成英文也不行:
int a = 10 to 5;
必须写成:
int a = 100000;
2.1.4 ASCII码表
下表为ASCII码表的可打印字符部分(0 ~ 127),供大家查阅使用,如表2-12所示:
表 2‑12 ASCII码表
2.1.5 枚举
枚举用来给一系列整型常量命名。它的使用方法如下:
enum 枚举名 {标识符1 = 整型常量1, 标识符2 = 整型常量2, ...}
和宏定义一样,枚举中的标识符习惯上也使用大写字母和下划线来命名。下面是用枚举定义十二个月份的例子:
enum month{JAN=1, FEB=2, MAR=3, APR=4, MAY=5, JUN=6,
JUL=7, AUG=8, SEP=9, OCT=10, NOV=11, DEC=12};
这样的定义比define要方便不少,但是依然有些冗长。幸运的是,在枚举中,如果不指定标识符的具体值的话,会默认该标识符的值等于前一标识符的值加1。因此可以将上面的定义简化成:
enum month{JAN=1, FEB, MAR, APR, MAY, JUN, JUL, AUG, SEP, OCT, NOV, DEC};
更进一步地,如果不指定第一个标识符对应的常量,则它的默认值是0,如例程2-4所示:
例程 2‑4 枚举的使用
16 /* Enum Project */
17 #include <stdio.h>
18 /* 定义一组常量 */
19 enum Constants {C1, C2, C3 = 4, C4, C5 = 3, C6, C7, C8 = '0', C9};
20 int main()
21 {
22 printf("C1=%d\n", C1);
23 return 0;
24 }
程序的运行结果如图2-10所示:

图 2‑10 枚举的使用
例程2-4中首先用枚举定义了一组常量C1到C9,并在Console窗口中输出常量C1的数值。请大家在编译和运行该例程之前,先试着猜测C1到C9这九个常量的数值。
常量
2.1.6 整型常量
最简单的整型常量是十进制整数,其声明规则为:
[正负号][十进制整数][后缀]
如果声明的是一个十进制正整数,则[正负号]一项中的正号可写可不写。[十进制整数]中,除非声明的常量是0,否则不要以0开头(即不要出现0123这样的数,而应直接写123)。[后缀]可以有以下几种取值(大小写随意):
表 2‑13 整型常量的后缀
如果没有后缀,且常量的大小没有超出int的范围,则默认该整型常量的类型是int。
请参考下面的几个例子以理解整型常量:
表 2‑14整型常量举例
在十进制当中,15,015和0015都是同一个值,但是如果写:
int a = 15;
int a = 015;
这两个值是不一样的。可以动手试试下面的程序:
在Visual Studio中新建一个C工程,如例程2-5所示:
例程 2‑5 八进制整数
9 #include <stdio.h>
10 int main()
11 {
12 int a = 015;
13 printf("%d\n", a);
14 return 0;
15 }
程序运行结果如图2-11所示:

图 2‑11八进制整数
大家会发现最后输出了13。这是因为0打头的整数会被解释成八进制数,而不是十进制数。而八进制的15刚好就是十进制的13。
2.1.7 实型常量
实数常量也叫浮点数常量,它表示的是一个浮点数的值。实数常量有两种表示方式:十进制小数表示和指数表示。当用十进制小数表示时,实数常量的格式为:
[正负号][十进制整数部分][小数点][十进制小数部分][后缀]
其中小数点必须有,正负号一项中如果是正数的话正号可以不写,十进制整数部分或十进制小数部分为0的话可以省略不写,但如果同时为0的话则至少要保留一个,后缀部分只有两种取值(大小写不限):F表示该常量的类型为float,L表示该常量的类型为long double。如果没有后缀,那么默认常量的类型为double。以下是一些正确的实型常量如表2-15所示:
表 2‑15 实数常量举例
声明实数常量的另一种方法是指数表示法,其声明规则为:
[十进制实数][指数符号e或E][十进制指数][后缀]
下面逐个解释各个部分的含义:
1. [十进制实数]可以是一个小数,或者整数。
2. [指数符号e或E]用e或者E表示10的幂,大小写不限。
3. [十进制指数]必须是整数。
4. [后缀]部分的规则和前述"实型常量的十进制小数表示法"中后缀的规则一致。
以下是一些正确的声明方式:
表 2‑16指数表示法常量举例
简单地说:可以按照十进制小数的写法去写,也可以用指数的形式去写。在指数形式中,指数必须是整数。
(脚下留心:整型常量和实型常量后缀中的L
在整型常量中,后缀L表示数据类型为long int;而在实型常量中,后缀L表示数据类型为long double。以实型常量0.123L为例:在声明时,不要把小数点漏掉,否则该常量会变成0123L,这是一个八进制long int类型的整型常量。
2.1.8 字符常量
下面是特别容易和整型常量搞混的字符常量。字符常量是用一对单引号将单个字符括起来的常量,它只有一种类型——char类型,占用8位1个字节。以下是一些字符常量的例子:
'A':字符常量A。
'B':字符常量B。
'0':字符常量0。
' ': 字符空格。
注意:字符'0'和整数0是不一样的!如果去查ASCII码表(下一节提供了ASCII码表供查阅),就可以看到字符'0'实际上是整数48。
在此前查阅ASCII码表的过程中应该留意到,在ASCII码表中,除了可以直接从键盘上输入的字符(如英文字母,标点符号,数字,数学运算符等)以外,还有一些字符是无法用键盘直接输入的,例如表中值为13的回车键——无法通过键盘直接输入来定义一个"回车"字符常量,因为当大家在VS中输入"回车"(键盘上的回车键)的时候,其实际效果就是在文本编辑器上光标跳到了下一行。为了定义"回车"这个字符常量,需要采用一种新的定义方式:转义字符。它以反斜杠\开头,随后接特定的字符。一些常见的转义字符定义如下:
表 2‑16 部分常见转义字符表
在Visual Studio中新建一个C工程,如例程2-5所示:
例程 2‑5 ASCII码与字符
16 /* ASCII Project */
17 #include <stdio.h>
18 int main()
19 {
20 char ch = '\n';
21 printf("%c", ch);
22 return 0;
23 }
程序的运行结果如图2-12所示:

图 2‑12 ASCII字符
请大家试着运行这个程序,看看回车在屏幕上的显示效果。也可以试试上表中其它的转义字符。
在上面的"动手体验"中大家已经了解了利用反斜杠定义字符常量的方法,值得一提的是反斜杠这个字符本身也必须以转义的方式来定义,否则反斜杠会将后面的单引号解释为转义字符而导致编译错误。
(多学一招:回车和换行的区别
大家应该在电影和电视上见过打字机(不是打印机)这种设备:打字员首先将纸张附着在打字机的滚筒上,当开始打字时,打字员敲击键盘输入一个字符,打字机的打字头在纸上打出相应的字符,随后滚筒带动纸张向左移动,等待打字员的下一次输入。当打字员输入完一行即将开始输入新的一行时,打字员手动将滚筒向右推,使得打字头回到纸张上新一行的开头,接着滚筒会将纸张整体向上移动一行。前一个动作被称为回车(carriage return),后一个动作被称为换行(line feed)。在现代计算机上,这两个字符被保留了下来,用作文本文件中的行分隔符,然而,不同的操作系统对于究竟选择使用回车还是换行作为行分隔符是有分歧的:在Windows操作系统中使用的是"回车 换行"的组合,Unix采用的是"换行",Mac OS采用的是"回车"。下面就以Windows下的文本文件为例向大家展示Windows的行分隔符:
打开记事本,键入以下内容,两行文本用正常的回车键分隔,如图2-13所示:

图 2‑13 Windows中的一个文本文件
随后请大家将文本文件保存,注意保存时编码选择"ANSI"(它是在ASCII字符集基础上扩展出的字符编码,这是Windows中记事本保存文本文件时的默认编码)。接下来,利用带有十六进制查看功能的文本编辑器如Sublime Text打开,选择利用16进制查看该文本文件,如图2-14所示:
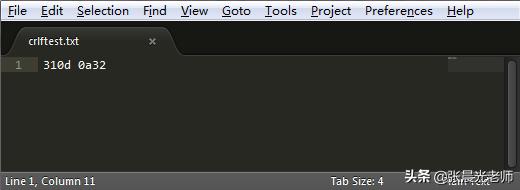
图 2‑14 在16进制下查看文本文件
其中0x31是数字1的ASCII码(十进制49),0x0d和0x0a分别是回车和换行的ASCII码(十进制分别为13和10),0x32是数字2的ASCII码。
2.1.9 宏定义
上文中已经介绍了各种类型常量的定义方法。有些时候,希望能够给常量起一个别名,从而更加直观地表示常量的具体含义。比如当定义了一个实数常量3.1415926时,希望能够给这个常量起一个更加易懂的名字PI来方便阅读和编写程序。C语言中提供了define指令来解决这一问题。define指令的基本格式为:
#define 别名 常量
其中,"别名"习惯上采用大写英文字母和下划线来命名,如"JANUARY"、"MAX_LINE_NUMBER"、"PI"等。下面是一个例子:
#defineFEB 2
在这个例子中,程序给常量2起了一个别名FEB,之后只要是出现FEB的地方都会被程序认为是2。
define指令所做的事情非常非常简单:为指令中的"常量"起一个叫做"别名"的名字。在define指令之后的程序中,凡是出现了这个别名的地方,它一般都将被直接替换为对应的常量,如例程2-6所示:
例程 2‑6 #define用法示例
25 /* Define Project */
26 #include <stdio.h>
27 #definePI 3.1415926f
28 int main()
29 {
30 /* 定义圆的半径为1 */
31 float radius = 1.0f;
32 /* 计算圆的面积 */
33 float area = PI * radius * radius;
34 /* printf输出语句:圆的面积是*/
35 printf("%f\n", area);
36 return 0;
37 }
程序的运行结果如图2-15所示:

图 2‑15define用法
例程2-6中定义了一个半径为1的圆,计算圆的面积并输出。程序利用define指令为常量3.1415926f定义了一个标识符PI,在编译程序之前,编译器会将程序中在define指令之后出现的PI直接替换成常量3.1415926f(记住:define是预处理指令,它和include一样会在编译整个程序之前被处理掉)。
利用define定义符号常量有以下几点优势:
1. 增强程序的可读性。和冷冰冰的数字相比,像PI这样的标识符显然可以提供更多更有意义的信息。尤其是在规模较大的程序中,程序员是很难记住每一个常量的具体含义的,标识符的引入可以给编程中的程序员以有益的提示。
2. 便于对常量进行修改。假设在例程3-3中想要提高程序的计算精度,因此采用一个更加精确的PI值3.141592653589793238463。在引入了符号常量PI之后,只要将#define指令中原有的PI常量修改为新的值即可。如果没有引入符号常量,而是在程序中每一处使用了PI值的地方都直接输入3.1415926的话(这种将常量直接编写在程序中的方式通常被称为"硬编码"),就需要找到每一处3.1415926并进行替换,当一个常量在程序中多次出现时,这样的修改是非常耗时的,而且还可能导致常量前后的不一致,从而引入潜在的错误。
变量
2.1.10 变量的定义
在程序运行期间,随时可能产生一些临时数据,应用程序会将这些数据保存在一些内存单元中,每个内存单元都用一个标识符来标识。这些内存单元我们称之为变量,定义的标识符就是变量名,内存单元中存储的数据就是变量的值。
定义变量的语法如下:
变量类型 变量名 = 变量初值;
例如,定义一个int类型的变量sum,并且令它的初始值为0。其示例代码如下:
int sum = 0;
这条语句的含义是,定义了一个名叫sum的变量,它的数据类型是int。因此,程序在内存中找到4个空闲的字节,并且把整数0写到这4个字节中。
在定义变量时也可以不给出变量的初值,示例代码如下:
int sum;
此时只是告诉了计算机,定义一个int类型变量sum,在内存中分配4个字节的存储空间,但还没有为他赋值。此时,变量sum对应的4个字节在内存中的值是完全不确定的。
在程序中,还可以一次定义多个变量,示例代码如下:
int a, b = 30, c;
上述代码中定义了三个int类型的变量,并分别起名为a、b和c。不同的变量之间用逗号分隔,语句末尾用分号作为结束,不同的变量可以进行赋值也可以不赋值。
2.1.11 C语言关键字
关键字是编程语言里事先规定好特殊含义的词,有些资料上称为"保留字"。C89标准规定了如下32个关键字。为避免冲突,在命名变量时不应该使用它们,如表2-17所示:
表 2‑17 C89标准中的关键字
这些关键字无需记忆,只要了解即可。随着C语言学习的逐步深入,大家会慢慢知道每个关键字的独特作用的。
C99标准新增了五个关键字:_Bool、_Imaginary、_Complex、restrict和inline。请同样在变量命名时避免使用这五个关键字。
2.1.12 变量的使用
定义好变量之后,就可以对变量进行操作了,例如,读取变量的值。在前面的讲解中可以看到很多用printf读取并输出变量的例子,接下来通过具体的案例来演示如何输出变量的值,如例程2-7所示:
例程 2‑7输出变量的值
38 #include <stdio.h>
39 int main()
40 {
41 int a = 30, b = 25;
42 a = b 3;
43 printf("%d\n", a);
44 return 0;
45 }
程序的运行结果如图2-16所示:

图 2‑16输出变量a的值
例程2-7中,首先定义了两个变量a和b,然后将b 3的值赋值给a。在计算b 3时,首先去读取b当前的值25,然后加上3得到28,把28写给a,最后通过printf语句输出a当前的值。
1、变量的命名规范
上文提到在使用一个变量之前需要先给变量起好名字。名字当然不是随便起的,C语言对变量名有如下几条限制:
1. 变量名只能由字母,数字和下划线组成,且第一个字符不能是数字。合法的变量名包括:a1,m_buffer,pName等等。
2. 不能使用C语言的保留字:保留字就是C语言自己预先定义好的一些名字,比如之前看到的return,double,int,char,include等等。这些名字C语言自己要使用,如果大家在程序中定义了一个叫做return的int变量,如下所示:
int return;
return;
C语言是分不清楚大家究竟是想返回还是想定义变量的。
尽管有上述两条限制,程序员可选的变量名还是非常多的,如何为自己的变量起一个好名字也是一门学问。假设想要在程序中求自然数1加到100的和,并这个和存在一个int类型的变量里,可以叫它aaa,也可以叫它sum,它们都是合法的变量名,但是显然后者比前者要好得多,因为sum一词指出了这个变量的含义和作用。
2、常见变量命名法
给变量起一个漂亮又有意义的名字是一门学问。在此向大家介绍两种常用的命名规则:
匈牙利命名法:匈牙利命名法建议使用一个简短的小写字母前缀来标注变量的类型,随后接若干首字母大写的单词来表明变量的作用,比如刚刚的sum,在匈牙利命名法中会被建议命名为iSum:首字母i表示这是一个int类型的变量,Sum指示了这个变量的含义是某些数的和。其他一些常用的前缀包括:
fpSpeed:fp是float point(浮点数)的缩写,这是一个用来记录速度的浮点数变量。
strStudentName:str是string(字符串)的缩写,这是一个用来记录学生姓名的字符串。
u8Color:u是unsigned(无符号整形)的缩写,这是一个用来表示颜色的无符号整数。
匈牙利命名法的前缀并没有严格的规定,程序员也可以发明自己觉得合适的前缀。
驼峰命名法:变量名由一系列首字母大写的单词组成,比如AccountNumber,FirstName,StudentID等等。也有人将变量的第一个单词的首字母小写:accountNumber,firstName,studentID。前者被称为大驼峰式命名法或Pascal命名法,后者被称为小驼峰式命名法。
变量的命名法更多地是出于方便程序员阅读和编程的考虑,编译器只认变量名是否合法,而不会管变量名是否"有意义"。对于开发者来说,变量的命名法也没有高下之分,只要在自己的程序中做到变量命名法则前后一致就可以了。
类型转换
在C程序中,有时候会遇到在两种不同类型的数据之间进行转换的情况。比如利用一个float类型的浮点数给double类型的浮点数赋值,或者利用将两个int整数相加的结果保存在long 类型变量当中。由于不同的数据类型约定了不同的表示数据的方式,因此就需要有一些特定的规则来规定如何在不同的数据类型之间进行转换。
2.1.13 类型提升
在表达式中,char和short 类型的值,无论有符号还是无符号,都会自动转换成int 或unsigned int 类型。举例说明:
char c1=12,c2=108;
c1 c2;
c1和c2都是char型,计算表达式c1 c2会先将c1和c2转换成int 类型,然后再相加,由于c1和c2是被准换成表示范围更大的类型,故而把这种转换称为"提升"。
不光在表达式中,在函数中也会出现"提升"当作为参数传递给函数时,char和short类型会提升成int类型,而float类型则会提升成double类型,如:
char ch= 'a';
printf("ch保存的ASCII码值:%d\n",ch);
ch是char型,作为参数传递给printf函数时,自动提升为int类型,因此不用再将ch强制转换为int 类型。
2.1.14 类型下降
在赋值语句中,赋值运算符左侧的变量是什么类型,右侧的值就要转换成什么类型。这个过程可能导致右侧值的类型提升,也可能导致其类型下降。所谓"下降"是指等级较高的类型被转换成等级较低的类型,也叫强制类型转换如下:
int d;
double x=3.1415926;
d=(int)x;//强制转换
x的级别比d高,因此将x的值赋给d会先将x的值转换为与d同样的类型,这将导致x的值的类型下降(针对x的副本而言),下降可能会丢失数据,因此大部分编译器会发出警告,为避免发出警告,需要进行强制转换。另外需要注意的是,假如右值过大,超出了左值的取值范围,那么强行赋给左值,会导致左值溢出。
2.1.15 常用算术转换
C语言算术表达式的计算,在计算过程中,每一步计算所得结果的数据类型由参与运算的运算对象决定,相同数据类型的两个对象运算,结果数据类型不变,不同数据类型的运算对象进行运算,结果的数据类型由高精度的运算对象决定。精度的高低:double>float>int。
需要注意的是,数据类型的转换是在计算过程中逐步进行的,整个表达式结果的数据类型一定与表达式中出现的精度最高的数据相同,但是具体得到数据值是逐步得到的,例如:
int x=1,y=3; double k=1573.267;
x/y*k
这个表达式计算结果的数据类型是double, 计算结果的答案是 0.0。因为在第一步 x/y 的计算中 结果是一个整型数据 0。第二步计算 0 * 1573.267 结果是一个double类型的数据,但数值是0.0。也就是说,算术表达式计算结果的数据类型与运算的优先级没有关系,一定具有表达式中精度最高的数据类型,但是具体得到数据结果数值,与优先级可就有关系。
2.1.16 赋值中的类型转换
当赋值运算符两边的运算对象类型不同时,将要发生类型转换,转换的规则是:把赋值运算符右侧表达式的类型转换为左侧变量的类型。具体的转换如下:
1、 浮点型与整型
将浮点数(单双精度)转换为整数时,将舍弃浮点数的小数部分,只保留整数部分。将整型值赋给浮点型变量,数值不变,只将形式改为浮点形式,即小数点后带若干个0。注意:赋值时的类型转换实际上是强制的。
2、 单、双精度浮点型
由于C语言中的浮点值总是用双精度表示的,所以float 型数据只是在尾部加0延长为double型数据参加运算,然后直接赋值。double型数据转换为float型时,通过截尾数来实现,截断前要进行四舍五入操作。
3、 char型与int型
int型数值赋给char型变量时,只保留其最低8位,高位部分舍弃。
char型数值赋给int型变量时, 一些编译程序不管其值大小都作正数处理,而另一些编译程序在转换时,若char型数据值大于127,就作为负数处理。对于使用者来讲,如果原来char型数据取正值,转换后仍为正值;如果原来char型值可正可负,则转换后也仍然保持原值, 只是数据的内部表示形式有所不同。
4、 int型与long型
long型数据赋给int型变量时,将低16位值送给int型变量,而将高16 位截断舍弃。(这里假定int型占两个字节)。 将int型数据送给long型变量时,其外部值保持不变,而内部形式有所改变。
5、 无符号整数
将一个unsigned型数据赋给一个占据同样长度存储单元的整型变量时(如:unsigned→int、unsigned long→long,unsigned short→short) ,原值照赋,内部的存储方式不变,但外部值却可能改变。
将一个非unsigned整型数据赋给长度相同的unsigned型变量时, 内部存储形式不变,但外部表示时总是无符号的。
本章小结
本章主要介绍了学习C语言所需的基础知识。其中包括C语言中的二进制、基本数据类型、变量和常量的定义,类型转换等,通过本章的学习初学者能够掌握C语言程序中如何进行进制转换,以及正确的定义变量和常量,并根据变量的数据类型不同进行类型转换等。
,