《测绘学报》
构建与学术的桥梁 拉近与权威的距离
加权混合估计中权值的确定方法
宋迎春1,2, 宋采薇1,2, 左廷英1,2

1. 中南大学有色金属成矿预测与地质环境监测教育部重点实验室, 湖南 长沙 410083;2. 中南大学地球科学与信息物理学院, 湖南 长沙 410083
收稿日期:2018-07-30;修回日期:2019-08-25
基金项目:国家自然科学基金(41574006;41674009;41674012)
第一作者简介:宋迎春(1963-), 男, 博士, 教授, 研究方向为测量数据处理理论与方法。E-mail:csusyc@csu.edu.cn, csusyc@qq.com
通信作者:左廷英, E-mail: zty2003@163.com
摘要:综合了大地测量中各种异方差多源观测模型和联合平差方法,说明了混合估计方法可以用于测量数据融合,平衡附加信息和样本信息对参数估计的影响。通过求取权值使参数估计的协方差阵的迹最小的方法,给出了一个权的最优选择方法。本文扩展了已有的加权混合估计方法,使得新方法中的权不受验前单位权方差的限制,能有效应用于大地测量数据处理。
关键词:随机约束 平差模型 加权混合估计 最优线性无偏估计
A method for determining the weight in weighted mixed estimation
SONG Yingchun1,2, SONG Caiwei1,2, ZUO Tingying1,2
1. Key Laboratory of Metallogenic Prediction of Nonferrous Metals and Geological Environment Monitoring, Ministry of Education, Central South University, Changsha 410083, China;2. School of Geosciences and Info-Physics, Central South University, Changsha 410083, China
Foundation support: The National Natural Science Foundation of China (Nos. 41574006; 41674009; 41674012)
First author: SONG Yingchun (1963—), male, PhD, professor, majors in theory and method of measuring data processing. E-mail:csusyc@csu.edu.cn, csusyc@qq.com.
Corresponding author: ZUO Tingying, E-mail: zty2003@163.com.
Abstract: In this paper, multi-source observation models with various heteroscedastic and combined adjustment methods in geodesy are summarized. It shows that the mixed estimation method can be used for measurement data fusion, and can balance the influence of additional information and sample information on parameter estimation. By calculating the weights to minimize the trace of the covariance matrix of parameter estimation, an optimal selection method of weights is given. This paper extends the existing weighted mixing method so that the given method are not limited by the prior unit weight variance, and can be effectively applied to large measurement data processing.
Key words: stochastic constraint adjustment model weighted mixed estimation optimal linear unbiased estimation
随着测量理论与技术的发展,测量平差的对象已从过去的单一同类观测扩展为同类不同精度,或不同类多源观测,通过多源数据融合可以获取更全面、更有效的信息,产生比单一信息源更精确、更可靠的信息[1-3]。然而,多源观测有不同的函数模型和随机模型,如边角网平差、导线网平差、地面网与空间网联合平差、水准网与重力网联合平差、不同空间网联合平差等[4-6]。另外,多源数据融合也会出现一些关于函数模型和随机模型的先验信息,如参数间往往存在固有的几何关系,构成函数模型约束,参数也可能存在某些先验随机信息,构成随机模型约束[7]。例如,多GNSS系统间存在互操作参数,具有系统性或缓变特性,因此可以通过最初若干历元求得的互操作参数作为先验的随机约束信息,参与后续的互操作参数解算。这些不同的模型,不同的先验信息给多源数据融合带来了挑战。在大地测量中(如复测网),为了融合多源观测数据,获取最优估计值,许多学者提出了联合平差方法,此类方法大多需要知道各类观测量的准确先验方差,从而确定各类融合数据的权[8-12]。在无法准确知道各类观测量的先验方差时,可以采用方差分量估计的方法对方差进行估计后再计算权值,如Helmert方差估计和最小范数二次无偏估计(MINQUE),由于随机约束信息并不能保证能够进行方差估计,因此本文不讨论此类方法。有学者直接提出了迭代求权值方法[10-12],但是迭代重加权最小二乘法是参数的一种非线性估计,其协方差阵计算困难,无法对其进行精度评估。在数学上,许多学者把多源观测数据看成是在新观测得到的样本信息上加上一些先验的随机约束信息[13-16],文献[17—19]研究了这类问题,提出了混合估计。由于附加信息和样本信息在估计过程中作用是不均等的,文献[20]在混合估计的基础上,提出了加权混合估计。这些算法大多注重于算法的效率和估计的优良性,不能直接用于大地测量数据处理。本文综合了大地测量中各种异方差多源观测模型和联合平差方法,利用带有随机约束的线性模型理论,建立了新的加权平差准则,平衡先验约束和观测信息对参数估计的影响,分析了加权混合估计的统计性质,扩展了已有的加权混合方法,提出了权的最优化选择方法,使得加权混合估计方法能有效应用于大测量数据处理。
1 带有随机约束的平差模型与加权混合估计
对于平差模型

式中,L为n维观测向量;A是n×m的设计矩阵;秩(A)=m;X=[x1x2…xm]T为m维未知向量;Δ为n维随机误差向量;ΣΔ为协方差矩阵;Δ~N(0,ΣΔ);ΣΔ=σΔ2PΔ-1;PΔ=σΔ2ΣΔ-1;σΔ2为单位权方差。
式(1)中的X是没有任何约束的,但在一些实际问题中,往往要求X满足某种约束条件,如X是非负的,或X满足某个线性等式约束。文献[18]提出了混合回归模型,将线性约束HX=c随机化得到随机化约束
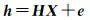
式中,h是p维随机向量;H是p×m矩阵;e是服从正态分布的p维随机误差向量,它的期望为0,协差阵为Σe=σe2Pe-1,即e~N(0,Σe)。Δ与e是独立的。这样就形成了带有随机约束的平差模型

(3)
其参数估计为

(4)
由式(4)可以看出,随机约束下混合估计形式上只需要在无约束最小二乘估计=(ATΣΔ-1A)-1ATΣΔ-1L中添加两项HTΣe-1H和HTΣe-1h即可,它可以解释为附加随机约束条件后给估计带来的调整,因而从这个角度来看,是最小二乘估计的推广。显然,包括了观测信息以外的附加先验信息,它是观测信息与先验信息相结合的混合估计。文献[21]给出了混合估计在测量数据处理中的应用,并证明了附有条件的间接平差、相关序贯平差,以及系统误差补偿及最小二乘配置等方法都是混合估计式(4)的特例。最小二乘滤波解在形式上与式(4)也相同。
现假定ΣΔ=σΔ2PΔ-1,Σe=σe2Pe-1,其中,PΔ、Pe为已知的权矩阵,则式(4)可以写为
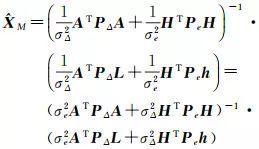
(5)
其协方差为

(6)
令S=ATPΔA,由矩阵公式(A BCD)-1=A-1-A-1B(C-1 DA-1B)DA-1,有

所以


(7)
在随机约束式(2)中,当σe2=0时,约束条件式(2)可以转换为非随机约束h=HX,由式(7)可知其解为

(8)
显然


其中,0≤λ≤1。利用拉格朗日求极限的方法,可以求得

(9)
若λ=1,加权混合估计退化为最小二乘估计;若λ=1/2,加权混合估计退化为普通的最小二乘混合估计。当0.5 <λ< 1时,它表示赋予样本信息的权重高于先验信息;反之,权重0 <λ< 0.5表示赋予先验信息的权重高于样本信息。在式(5)中,若σΔ2和σe2已知,令λ=σe2/(σΔ2 σe2),则式(9)也可以化成式(5)的形式,这时权值λ由单位权方差σΔ2和σe2确定。若假设新的观测信息比先验信息“更准确”,就会有0.5 <λ=σe2/(σΔ2 σe2) < 1。设


(11)
由式(9)有

由于有WL(λ) Wh(λ)=I,I为单位矩阵,故可以将看作和的“加权”平均值。现将L=AX Δ,h=HX e代入式(9),可得

(13)
而E(ATPΔΔ)=0,E(HTPee)=0,有E((λ)-X)=0,这说明在随机约束h=HX e下,是X的无偏估计。即

由式(13)和式(14)可以计算混合估计(λ)的协方差阵

(15)
2 权值确定方法2.1 σΔ2未知、σe2已知
在前面的讨论中,假定单位权方差σΔ2和σe2是已知的,但在测绘工程实际中它们未必知道,或者虽已知,但不准确。若单位权方差σΔ2未知,而σe2已知文献[18-19]建议用单位权方差σΔ2的最小二乘估计

代替σΔ2得到两步混合估计(s12),即

(16)
令PA=A(ATPΔA)-1ATPΔ,有L-A=L-PAL,考虑到(I-PA)A=0,有

(17)
显然(s12)为非线性估计,对于平差模型式(1),在随机线性h=HX e约束下,假定Δ,e相互独立,则两步混合估计(s12)的期望若存在,则(s12)必为X的无偏估计。此方法的不足之处是要求平差模型式(1)多余观测充分,否则s12的估计不准确,对于多余观测充分的平差模型式(1),需要随机约束式(2)有更高的观测精度才能提高融合后的加权混合估计精度。
2.2 σΔ2、σe2都未知
由于σΔ2、σe2都未知,不能采用式(5)来计算,一种可行的方法是令λ=1/2,即看作σΔ2=σε2,实际上就是普通的最小二乘平差方法

其协方差可由式(19)近似计算

(19)
式中,



(20)
由式(20),有

(21)
而E(ATPΔΔ)=0,E(HTPee)=0,有E[ (s12,s22)-X]=0,所以E[(s12,s22)]=X,即(s12,s22)是X的无偏估计,由于s12和s22分别是Δ和e的函数,所以(s12,s22)是非线性估计,(s12,s22)的协方差的计算非常复杂[14]。同样,此方法的不足之处是要求平差模型式(1)和随机约束式(2)的多余观测都充分,否则s12和s22的估计不会准确,利用它进行权值计算就不准确。
2.3 迭代重加权混合估计
加权混合估计方法沿承了经典最小二乘估计的优良特性,是异质传感器数据融合比较理想方法,然而在大地测量实践中, σΔ2、σe2往往是未知的, 无法准确知道加权混合估计中的权,为了得到近似的加权混合估计,采用迭代重加权混合估计方法。迭代重加权法的本质就是为了给σΔ2、σe2较精确的估计,因此,首先利用s12和s22作为σΔ2、σe2的初始估计值

(22)

(23)
然后,进行迭代循环

(24)

(25)

(26)
直到



3 最优权的计算方法
前面的分析说明迭代重加权混合估计方法解决σΔ2、σe2未知时的参数估计问题,却无法进行精度评估,现提出一种最优权计算方法。其基本思路是:把权当作一个非随机变量,先通过迭代方法求出σΔ2、σe2的估计,然后利用加权混合估计均方误差矩阵,求均方误差的极小值从而得到最优的权值,进而得到这组权值下的最小二乘估计,以此作为参数估计结果。设加权混合估计为

(27)
式中,权λ是一个非随机变量,λ∈[0, 1]。由于,对于一般的参数向量θ的一个估计,均方误差矩阵(MSE)定义为

(28)
此处


(29)
建立优化模型


tr(M)为矩阵M的求迹函数,解优化问题式(30),可计算出最优权值λ*,然后代入式(27)可以得到混合估计


对于优化模型式(30)的解算,可在λ满足式(30(b))的条件下,直接利用的搜索算法,λ从0开始到1止,通过增量Δλ(如Δλ=0.001),逐步遍历搜索得到使MSE[(λ)]迹达到最小的λ*,从而求出参数估计值(λ*)和协方差阵

4 实例与分析
如图 1所示的网形,P1、P2为已知点,其坐标分别为(47 502.285, 61 113.496)和(48 013.013, 61 625.845),为了便于分析比较,算例中的点P3、P4、P5的真实坐标假设已知(见表 1)。假设有两类观测值,都是利用真实坐标计算,再加上得到的:第1类是两点间的GPS基线向量观测值(只取二维),其噪声Δ为高斯噪声,单位权方差为σΔ2=0.1 m2,权阵为PΔ,其观测向量和设计矩阵见表 2;第2类是边长观测值,其噪声e为高斯噪声,单位权方差为σe2=0.4 m2,权阵为Pe,其观测向量和设计矩阵见表 2,其中,权矩阵PΔ和Pe为对角矩阵,它们分别为
PΔ=diag(1.214 8, 1.115 9, 1.912 3, 1.810 6, 1.242 7, 1.217 6, 1.647 3, 1.576 9, 2.185 7, 1.965 3, 1.528 5, 1.353 4, 1.248 3, 1.194 4)
Pe=diag(2.677 2, 1.925 0, 2.235 8, 2.488 8, 2.962 5, 0.183 3, 1.305 9)

图 1 三角网形Fig. 1 Triangulation net
图选项
表 1 真实坐标与近似坐标Tab. 1 The true coordinates and approximate coordinates
| 点名 | 真实坐标 | 近似坐标 | ||||
| P3 | P4 | P5 | P3 | P4 | P5 | |
| x/m | 48 521.134 | 48 089.412 | 47 797.210 | 48 521.151 | 48 089.398 | 47 797.234 |
| y/m | 61 103.829 | 60 618.187 | 60 588.498 | 61 103.810 | 60 618.270 | 60 588.590 |
表选项
表 2 第1类观测值的观测向量和设计矩阵(σΔ2=0.4)Tab. 2 Observation vectors and design matrices of the first kind of observations (σΔ2=0.4)
| L | A | |||||
| -0.094 6 | 0 | 0 | 1 | 0 | 0 | 0 |
| 0.000 4 | 0 | 0 | 0 | 1 | 0 | 0 |
| -0.057 7 | 0 | 0 | 0 | 0 | 1 | 0 |
| -0.047 5 | 0 | 0 | 0 | 0 | 0 | 1 |
| -0.096 6 | 1 | 0 | 0 | 0 | 0 | 0 |
| 0.129 0 | 0 | 1 | 0 | 0 | 0 | |
| 0.103 8 | 0 | 0 | 1 | 0 | 0 | 0 |
| -0.010 8 | 0 | 0 | 0 | 1 | 0 | 0 |
| -0.028 1 | -1 | 0 | 1 | 0 | 0 | 0 |
| -0.105 7 | 0 | -1 | 0 | 1 | 0 | 0 |
| -0.062 2 | -1 | 0 | 0 | 0 | 1 | 0 |
| -0.074 2 | 0 | -1 | 0 | 0 | 0 | 1 |
| -0.081 8 | 0 | 0 | -1 | 0 | 1 | 0 |
| -0.079 9 | 0 | 0 | 0 | -1 | 0 | 1 |
表选项
利用上面的观测数据和设计矩阵,可以建立带有随机约束的平差模型式(3),分别用最小二乘估计=(ATΣΔ-1A)-1ATΣΔ-1L和=(HTΣe-1H)-1HTΣe-1h,普通混合估计,扩展最小二乘估计,σΔ2未知的带权混合估计(s12),σΔ2和σΔ2都未知的带权混合估计(s12,s22),σΔ2和σΔ2都未知时的重迭代加权估计,以及加权优化估计(λ*),它们的估计公式对应式(5)、式(16)、式(18)、式(20)、式(24)和式(31),设参数估计的偏差平方和f=(-Xtrue)T(-Xtrue),其计算结果见表 4。
表 3 第2类观测值的观测向量和设计矩阵(σe2=0.1)Tab. 3 Observation vectors and design matrices of the first kind of observations (σe2=0.1)
| h | H | |||||
| 0.065 9 | 0 | 0 | 0.764 4 | -0.644 8 | 0 | 0 |
| 0.116 6 | 0 | 0 | 0 | 0 | 0.489 9 | -0.871 8 |
| 0.026 3 | 0.697 5 | -0.716 6 | 0 | 0 | 0 | 0 |
| -0.026 1 | 0 | 0 | 0.075 6 | -0.997 1 | 0 | 0 |
| 0.011 0 | 0.664 5 | 0.747 3 | -0.664 5 | -0.747 3 | 0 | 0 |
| 3.318 3 | 0.814 7 | 0.579 8 | 0 | 0 | -0.814 7 | -0.579 8 |
| -0.036 7 | 0 | 0 | 0.994 9 | 0.101 1 | -0.994 9 | -0.101 1 |
表选项
表 4 不同参数估计的结果Tab. 4 The results of several different parameter estimates
| Xtrue | (s12) | (s12,s22) | (λ*) | |||||
| -0.017 0 | -0.017 2 | 0.240 5 | 0.013 5 | 0.070 3 | -0.014 9 | -0.016 6 | -0.016 7 | -0.016 7 |
| 0.019 0 | 0.092 9 | 0.131 4 | 0.086 0 | 0.087 3 | 0.092 2 | 0.092 7 | 0.092 7 | 0.092 7 |
| 0.014 0 | -0.005 0 | 0.038 0 | 0.008 7 | 0.029 9 | -0.003 9 | -0.004 7 | -0.0048 | -0.004 8 |
| -0.083 0 | 0.002 0 | 0.085 4 | -0.002 9 | 0.004 4 | 0.001 4 | 0.001 8 | 0.0018 | 0.001 8 |
| -0.024 0 | -0.072 5 | -0.266 5 | -0.070 8 | -0.079 3 | -0.072 2 | -0.072 4 | -0.0725 | -0.072 5 |
| -0.092 0 | -0.035 3 | -0.435 3 | -0.066 1 | -0.124 6 | -0.037 6 | -0.035 9 | -0.035 8 | -0.035 8 |
|
| 0.018 6 | 0.284 5 | 0.014 7 | 0.024 3 | 0.018 1 | 0.018 5 | 0.018 5 | 0.018 5 |
|
| 0.166 7 | 2.454 7 | 0.144 1 | 0.612 1 | — | — | — | 0.010 4 |

表选项
算法分析:
(1) 由于在观测向量L中,观测数n较大,的精度比好,所以把两个观测进行融合得到的混合估计精度有了较大的提高。在测绘工程实际中,单位权方差一般无法准确地知道,算例中提供了多种混合估计的方案,精度都有了明显的提高。
(2) 和,普通混合估计是线性无偏估计,它们的均方误差阵可以由前面推导的协方差公式计算出来,为了比较它们的优良性,本算例中分别计算它们的迹为

另外,从表 4中的偏差平方和也可以看出要优于和。
一般情形下都会有


即和的均方误差大于普通混合估计的均方误差[7, 9, 14-16]。
(3) 当σΔ2和σe2已知时,普通混合估计是最优线性无偏估计,混合估计的权容易确定,当σΔ2未知,而σe2已知时,可以利用(s12)进行混合估计,但是(s12)的协方差计算比较复杂,进行精度评估比较困难,用s12代替σΔ2会有精度损失,从实例计算中也可以看出

(4) 当σΔ2和σe2未知时,扩展最小二乘估计和加权优化估计(λ*)也是线性估计,计算它们的协方差时,可先利用式(24)和式(25)进行迭代求出σΔ2和σe2的估计值,然后再利用式(23)求其近似解。算法中的搜索步长为0.001,本算例中分别计算它们的均方差矩阵的迹为

由于最小二乘估计和加权优化估计(λ*)也是线性无偏估计,以及是最优线性无偏估计,可知一般情形下都有

(5) 迭代重加权法解决了σΔ2、σe2未知时的参数估计问题,但是,迭代的每一步估计

(6) (s12)、(s12,s22)和重迭代加权估计都是利用两步估计计算得到的,它们的协方差阵求解比较困难。无法进行均方误差的比较,其精度评估无法进行,文献[14]给出了(s12,s22)协方差的一个计算公式,但非常复杂。表 4给出的偏差平方和,只能作为一个参考,在实际应用中由于不知道真值,其实无法比较其算法的效果。但从先验信息的利用来看,(s12)应优于(s12,s22)。(s12)、M(s12,s22)和重迭代加权估计也不是线性估计,无法利用的最优线性无偏估计性质进行分析。
5 结束语
联合平差的原理和方法与线性模型中的混合估计理论是一致的,异质观测、前期观测都可以看成是一种随机约束。大地测量中各种异方差多源观测模型进行融合需要进行混合估计,由于附加信息和样本信息在估计过程中作用是不均等的,本文在混合估计理论的基础上,分析了加权混合估计中权值对参数估计的影响,虽然它们的估计效率在数学上已有大量的研究成果,一般都优于最小二乘算法,但用于测量平差算法还存在缺陷。本文综合分析了数学上现有的多种权的选择方法,提出了一个最优化权选择方法,可以使加权混合估计方法更有效地应用于大测量数据处理。
【引文格式】宋迎春, 宋采薇, 左廷英. 加权混合估计中权值的确定方法. 测绘学报,2020,49(1):34-41. DOI: 10.11947/j.AGCS.2020.20180359






