机器之心报道
实现高性能低功耗人工突触,用于神经网络计算
尽管这些年来,计算机技术取得不少进展,但是,在再造大脑低能耗、简洁的信息处理过程这方面,我们仍然步履蹒跚。现在,斯坦福大学和桑迪亚国家实验室的研究人员取得了重要进展,该研究可以帮助计算机模拟某块大脑高效设计,亦即人工突触。

Alberto Salleo,材料科学与工程学副教授,研究生 Scott Keene 在确知用于神经网络计算的人工突触的电化学性能。他们是创造这一新设备团队的成员。
Alberto Salleo 说,它运行起来就像是真的突触,不过,它是一个可以制造出来的电子设备。Alberto Salleo 是斯坦福大学材料科学与工程学副教授,也是这篇论文的资深作者(senior author)。「这是一套全新的设备系列,之前并没有看到过这类架构。许多关键标准测评后,我们发现,这款设备的性能要比其他任何非有机设备要好。」
相关研究发表在了 2 月 20 日 的 Nature Materials上,该人工突触模仿了大脑突触从通过其中的信号中进行学习的方式。较之传统计算方式,这种方式要节能得多,传统方法通常分别处理信息然后再将这些信息存储到存储器中。就是在这里,处理过程创造出记忆。
或许有一天,这款突触能够成为一台更接近大脑计算机的一部分,它特别有利于处理视觉、听觉信号的计算过程。比如,声控接口以及自动驾驶汽车。过去,这一领域已经研究出人工智能算法支持下的高效神经网络,但是,这些模仿者距离大脑仍然比较遥远,因为,它们还依赖传统的能耗计算机硬件。
建造一个大脑
人类学习时,电子信号会在大脑神经元之间传递。首次横穿神经元最耗费能量。再往后,连接所需的能力就少了。这也是突触为学习新东西、记住已学内容创造便利条件的方式。人工突触,和所有其他类脑计算版本不同,可以同时完成(学习和记忆)这两项任务,并能显著节省能量。
深度学习算法非常强大,不过,仍然依赖处理器来计算、模拟电子状态并将其保存在某个地方,就能耗和时间而言,这可不够高效,Yoeri van de Burgt 说,他之前是 Salleo lab 的博士后研究人员(postdoctoral scholar),也是这篇论文的第一作者。「我们没有模拟一个神经网络,而是试着制造一个神经网络。」
这款人工突触是以电池设计为基础的。由两个灵活的薄膜组成,薄膜带有三个终端,这些终端通过盐水电解质连接起来。它的功能就像一个晶体管,其中一个终端控制其与其他两个终端之间的电流。
就像大脑中的神经通路可以通过学习得到加强,研究人员通过重复放电、充电,为人工突触编程。训练后,他们就能预测(不确定性仅为 1%)需要多少伏电,才能让突触处于某种特定电信号状态(electrical state),而且一旦抵达那种状态,它就可以保持该状态。易言之,不同于普通电脑,关掉电脑前,你会先将工作保存在硬件上,人工突触能回忆起它的编程过程而无需任何其他操作或部件。
测试人工突触网络
桑迪亚国家实验室的研究者目前只制造了一个人工神经突触,但是,他们使用有关突触实验中获得的 15,000 个测量结果来模拟某一列(array)突触在神经网络中的运行方式。他们测试了模拟网络识别手写数字 0 到 9 的能力。三个数据集上的测试结果显示其识别手写数字准确度达 93%~97%。
尽管这项工作对于人类来说显得相对简单,但是对于传统计算机而言,要解释视觉与听觉信号曾经是非常困难的。
「我们期望计算设备能做的工作越来越多,这就需要模拟大脑工作方式的计算方式,因为用传统计算来完成这些工作,能耗巨大,」A. Alec Talin 说,「我们已经证实这款设备很适合实现这些算法,而且很节能。」A. Alec Talin 是桑迪亚国家实验室的杰出技术研究员,也是这篇论文的资深作者。
该设备极其适合于传统计算机执行起来很费劲的信号识别和分类工作。数字晶体管只能处于两种状态,比如 0 或 1,但是研究人员在一个人工突触上成功编码了 500 种状态,对于神经元类计算模型来说,这很有用。从一种状态切换到另一种状态所使用的能耗约为当前最先进计算系统的 1/10,最先进的计算系统需要这些能耗将数据从处理单元移动到存储器。
然而,较之一个生物突触引发放电所需的最低能耗,这款人工突触仍然不够节能,所需能耗是前者的 10000 倍。研究人员希望,一旦他们测试用于更小的设备的人工神经突触,他们可以实现类似生物神经元级别的能耗水平。
有机材料的潜力
设备的每一部分都由便宜的有机材料制成。虽然在自然界中找不到这些材料,但是它们大部分都由氢、碳两种元素构成,而且与大脑化学物质兼容。细胞已经可以在这些物质上生长,并且已经被来打造用于神经递质(neural transmitters)的人工泵。用于训练这类人工突触的电伏也和穿行人类神经元所需的能量相同。
这些都使得人工神经突触与生物神经元之间的交流成为可能,可借此改进脑机接口。同时,设备的柔软性与灵活性也使得它可被用于生物环境。但是,进行任何生物学方面应用之前,团队计划先打造一列人工神经突触,用于进一步研究与测试。
剖析DeepMind神经网络记忆研究:模拟动物大脑实现连续学习
实现通用人工智能的关键步骤是获得连续学习的能力,也就是说,一个代理(agent)必须能在不遗忘旧任务的执行方法的同时习得如何执行新任务。然而,这种看似简单的特性在历史上却一直未能实现。McCloskey 和 Cohen(1989)首先注意到了这种能力的缺失——他们首先训练一个神经网络学会了给一个数字加 1,然后又训练该神经网络学会了给数字加 2,但之后该网络就不会给数字加 1 了。他们将这个问题称为「灾难性遗忘(catastrophic forgetting)」,因为神经网络往往是通过快速覆写来学习新任务,而这样就会失去执行之前的任务所必需的参数。
克服灾难性遗忘方面的进展一直收效甚微。之前曾有两篇论文《Policy Distillation》和《Actor-Mimic: Deep Multitask and Transfer Reinforcement Learning》通过在训练过程中提供所有任务的数据而在混合任务上实现了很好的表现。但是,如果一个接一个地引入这些任务,那么这种多任务学习范式就必须维持一个用于记录和重放训练数据的情景记忆系统(episodic memory system)才能获得良好的表现。这种方法被称为系统级巩固(system-level consolidation),该方法受限于对记忆系统的需求,且该系统在规模上必须和被存储的总记忆量相当;而随着任务的增长,这种记忆的量也会增长。
然而,你可能也直觉地想到了带着一个巨大的记忆库来进行连续学习是错误的——毕竟,人类除了能学会走路,也能学会说话,而不需要维持关于学习如何走路的记忆。哺乳动物的大脑是如何实现这一能力的?Yang, Pan and Gan (2009) 说明学习是通过突触后树突棘(postsynaptic dendritic spines)随时间而进行的形成和消除而实现的。树突棘是指「神经元树突上的突起,通常从突触的单个轴突接收输入」,如下所示:
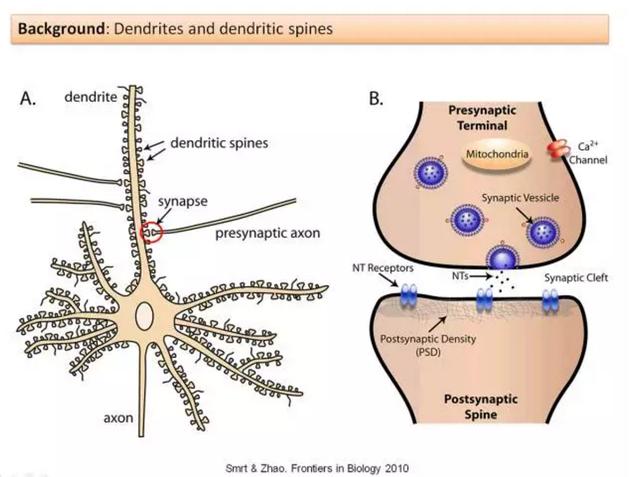
具体而言,这些研究者检查了小鼠学习过针对特定新任务的移动策略之后的大脑。当这些小鼠学会了最优的移动方式之后,研究者观察到树突棘形成出现了显著增多。为了消除运动可能导致树突棘形成的额外解释,这些研究者还设置了一个进行运动的对照组——这个组没有观察到树突棘形成。然后这些研究者还注意到,尽管大多数新形成的树突棘后面都消失了,但仍有一小部分保留了下来。2015 年的另一项研究表明当特定的树突棘被擦除时,其对应的技能也会随之消失。
Kirkpatrick et. 在论文《Overcoming catastrophic forgetting in neural networks》中提到:「这些实验发现……说明在新大脑皮层中的连续学习依赖于特定于任务的突触巩固(synaptic consolidation),其中知识是通过使一部分突触更少塑性而获得持久编码的,所以能长时间保持稳定。」我们能使用类似的方法(根据每个神经元的重要性来改变单个神经元的可塑性)来克服灾难性遗忘吗?
这篇论文的剩余部分推导并演示了他们的初步答案:可以。
直觉
假设有两个任务 A 和 B,我们想要一个神经网络按顺序学习它们。当我们谈到一个学习任务的神经网络时,它实际上意味着让神经网络调整权重和偏置(统称参数/θ)以使得神经网络在该任务上实现更好的表现。之前的研究表明对于大型网络而言,许多不同的参数配置可以实现类似的表现。通常,这意味着网络被过参数化了,但是我们可以利用这一点:过参数化(overparameterization)能使得任务 B 的配置可能接近于任务 A 的配置。作者提供了有用的图形:
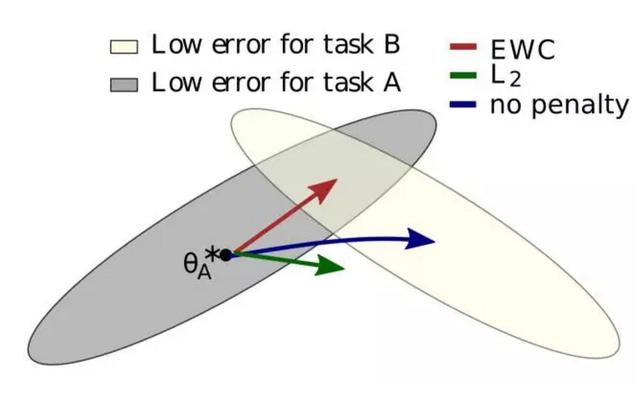
在图中,θ∗A 代表在 A 任务中表现最好的 θ 的配置,还存在多种参数配置可以接近这个表现,灰色表示这一配置的集合;在这里使用椭圆来表示是因为有些参数的调整权重比其他参数更大。如果神经网络随后被设置为学习任务 B 而对记住任务 A 没有任何兴趣(即遵循任务 B 的误差梯度),则该网络将在蓝色箭头的方向上移动其参数。B 的最优解也具有类似的误差椭圆体,上面由白色椭圆表示。
然而,我们还想记住任务 A。如果我们只是简单使参数固化,就会按绿色箭头发展,则处理任务 A 和 B 的性能都将变得糟糕。最好的办法是根据参数对任务的重要程度来选择其固化的程度;如果这样的话,神经网络参数的变化方向将遵循红色箭头,它将试图找到同时能够很好执行任务 A 和 B 的配置。作者称这种算法「弹性权重巩固(EWC/Elastic Weight Consolidation)」。这个名称来自于突触巩固(synaptic consolidation),结合「弹性的」锚定参数(对先前解决方案的约束限制参数是二次的,因此是弹性的)。
数学解释
在这里存在两个问题。第一,为什么锚定函数是二次的?第二,如何判定哪个参数是「重要的」?
在回答这两个问题之前,我们先要明白从概率的角度来理解神经网络的训练意味着什么。假设我们有一些数据 D,我们希望找到最具可能性的参数,它被表示为 p(θ|D)。我们可以是用贝叶斯规则来计算这个条件概率。

如果我们应用对数变换,则方程可以被重写为:

假设数据 D 由两个独立的(independent)部分构成,用于任务 A 的数据 DA 和用于任务 B 的数据 DB。这个逻辑适用于多于两个任务,但在这里不用详述。使用独立性(independence)的定义,我们可以重写这个方程:

看看(3)右边的中间三个项。它们看起来很熟悉吗?它们应该。这三个项是方程(2)的右边,但是 D 被 DA 代替了。简单来说,这三个项等价于给定任务 A 数据的网络参数的条件概率的对数。这样,我们得到了下面这个方程:

让我们先解释一下方程(4)。左侧仍然告诉我们如何计算整个数据集的 p(θ| D),但是当求解任务 A 时学习的所有信息都包含在条件概率 p(θ| DA)中。这个条件概率可以告诉我们哪些参数在解决任务 A 中很重要。
下一步是不明确的:「真实的后验概率是难以处理的,因此,根据 Mackay (19) 对拉普拉斯近似的研究,我们将该后验近似为一个高斯分布,其带有由参数θ∗A 给定的均值和一个由 Fisher 信息矩阵 F 的对角线给出的对角精度。」
让我们详细解释一下。首先,为什么真正的后验概率难以处理?论文并没有解释,答案是:贝叶斯规则告诉我们
p(θ|DA) 取决于 p(DA)=∫p(DA|θ′)p(θ′)dθ′,其中θ′是参数空间中的参数的可能配置。通常,该积分没有封闭形式的解,留下数值近似以作为替代。数值近似的时间复杂性相对于参数的数量呈指数级增长,因此对于具有数亿或更多参数的深度神经网络,数值近似是不实际的。
然后,Mackay 关于拉普拉斯近似的工作是什么,跟这里的研究有什么关系?我们使用θ*A 作为平均值,而非数值近似后验分布,将其建模为多变量正态分布。方差呢?我们将把每个变量的方差指定为方差的倒数的精度。为了计算精度,我们将使用 Fisher 信息矩阵 F。Fisher 信息是「一种测量可观察随机变量 X 携带的关于 X 所依赖的概率的未知参数θ的信息的量的方法。」在我们的例子中,我们感兴趣的是测量来自 DA 的每个数据所携带的关于θ的信息的量。Fisher 信息矩阵比数值近似计算更可行,这使得它成为一个有用的工具。
因此,我们可以为我们的网络在任务 A 上训练后在任务 B 上再定义一个新的损失函数。让 LB(θ)仅作为任务 B 的损失。如果我们用 i 索引我们的参数,并且选择标量λ来影响任务 A 对任务 B 的重要性,则在 EWC 中最小化的函数 L 是:
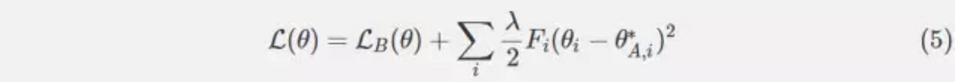
作者声称,EWC 具有相对于网络参数的数量和训练示例的数量是线性的运行时间。
,




