(报告出品方/分析师:东方财富证券 高博文 陈子怡)
1.趋势1.1.发展历程:算法不断迭代,效果日渐逼真
AIGC(AI-Generated Content)尚无统一规范的定义,国内产学研各界对于AIGC的理解是“继PGC(Professional Generated Content)和UGC(User Generated Content)之后”,利用人工智能技术自动生成内容的新型生产方式。

国际上对应的术语是“人工智能合成媒体(AI-Generated Media或Synthetic Media)”,是通过人工智能算法对数据或媒体进行生产、操控和修改的统称。
AIGC、NFT和VR是元宇宙和Web3.0的三大基础设施,随着数据积累、算力提升和算法迭代,人工智能正逐步在写作、编曲、绘画和视频制作等创意领域渗透。
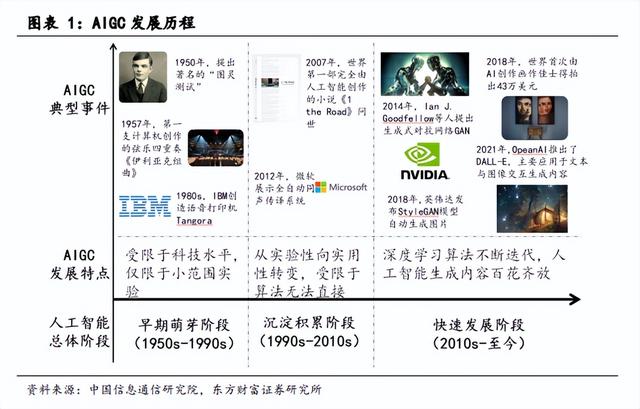
结合人工智能的演进历程,AIGC的发展大致分为三个阶段:
萌芽阶段(1950s-1990s):受限于科技水平,仅限于小范围实验。1957年,莱杰伦·希勒和伦纳德·艾萨克森通过将计算机程序中的控制变量换成音符,完成了历史上第一支由计算机创作的音乐作品——《依利亚克组曲(Illiac Suite)》。80年代中期,IBM基于隐形马尔科夫链模型创造了语音控制打字机“坦戈拉(Tangora)”。由于高昂的系统成本却无法带来可观的商业化,人工智能领域的投入持续减少。
积累阶段(1990s-2010s):AIGC从实验性向实用性逐渐转变。2007年,罗斯·古德温使用人工智能系统通过对公路旅行中的一切所见所闻进行记录,撰写世界第一部完全由人工智能创作的小说,但整体可读性不强且缺乏逻辑。2012年,微软公开展示了全自动同声传译系统,基于深层神经网络通过语音识别、翻译和合成生成他国语音。算力性能提升和互联网数据膨胀为人工智能提供了海量训练数据,使其取得了显著发展。
提速阶段(2010s-至今):随着生成式对抗网络(Generative Adversarial Network)为代表的深度学习算法的迭代创新,AIGC内容的效果日渐逼真。2018年,英伟达发布的StyleGAN模型可以自动生成图片。
2019年,DeepMind发布了DVD-GAN模型用以生成连续视频,在草地、广场等明确场景表现突出。
2021年OpenAI推出DALL-E,并根据Diffusion models推出升级版本DALL-E-2,主要应用于文本与图像的交互生成内容,用户只需要输入简短的描述性文字,即可得到高质量的各类风格绘画作品。

1.2.内容生产:从 PGC 到 UGC,从 UGC 到 AIGC
随着技术的发展,内容的生产方式也随之变化,从PGC到UGC,再从UGC到AIGC。
根据Questmobile数据显示,2022年上半年以UGC为主要生产方式的短视频时长进一步增长2.3个百分点达28.0%,以PGC为主要生产方式的在线视频时长下降0.2个百分点达6.6%。相比于PGC,UGC具有供给量充足、快速试错、优胜劣汰等优势,成为当前内容生产的主要形态。

AIGC是UGC发展到一定阶段的必然产物。
一方面,内容生产的升级依赖于工具的迭代,而工具的迭代依赖于对优质内容的总结。以抖音为例,美颜、配音和特效简化内容制作,而创作者对于热门和优质内容的模仿又推动优质内容的集中产出。
事实上,推荐算法的结果将加剧局部的中心化,一个爆款内容往往带动的是一类爆款内容。可以说UGC是基于PGC内容的,从影视内容的二次创作到爆款内容的扩散。同理,大量的UGC内容也是AIGC的温床,AI通过对数据的深度学习和归纳,不断提高内容的质量。
将UGC供给量充足、快速试错、优胜劣汰的优势进一步深化。

另一方面,尽管UGC极大提升了内容的供给量,但仍难以满足日益增长的用户需求。
以哔哩哔哩为例,自2017年第一季度到2022年第二季度,用户日均观看量从6.6上升至33.8个视频/天,用户对内容的需求不断提升。而内容创作者渗透率约1.2%,月均投稿3.7篇/月,仍然难以满足用户的消费需求,短视频相对供给更充足但内容质量略低。AIGC将弥补这一供给缺口。

AIGC并不是一蹴而就,百度创始人、董事长兼首席执行官李彦宏在百度世界大会中判断AIGC将迎来三个发展阶段:
1)助手阶段,AIGC辅助人类进行内容生产;
2)协作阶段,AIGC以虚实并存的虚拟人形态出现,形成人机共生;
3)原创阶段,AIGC将独立完成内容创作。

1.3.内容形态:从文字到图片,从图片到视频,从视频到游戏
内容生产方式和内容形态不可分割。从内容形态的难易程度来看,依次是文字、图片、视频和游戏。游戏领域的UGC仍不成熟,文字领域的AIGC日趋成熟,由此推演,图片和视频领域的AIGC化即将到来。

文字:相对专业性较强的博客自2000年进入中国,用户仅停留在数十万级别。
微博于2009年上线,对文字内容的数量和质量要求大幅下降,到了2010年10月底微博的注册用户即超过5000万。2015年腾讯财经开发的写稿机器人Dreamwriter发出第一篇稿件。发展至今,青云智能开放平台(Dreamwriter)年发稿量30万篇,稿件字数6000万,平均成文速度为0.46秒/篇,涵盖财经、体育、房产、法律等二十多个场景。
图片:视觉中国成立于2000年,逐步从编辑类图片涉及创意类图片,与海外图片巨头Getty有稳定的合作。
2008年以后,像我图网、图虫网这样的UGC类型摄影师社区也逐步出现,视觉中国也于2018年收购了全球知名摄影社区500px。2022年,OpenAI宣布开放DALL.E 2接口,已有300万人使用过DALL.E 2,每天创造图片数量超过400万。国内诸如盗梦师等品牌纷纷推出自研的AI绘画工具,可以通过文字AI生成多种风格和画师的画作。

视频:国内三大长视频网站中优酷(2006年)、爱奇艺(2010年)、腾讯视频(2011年),早期优酷尝试过偏UGC模式,但由于版权等问题,最后仍以PGC内容为主。
2009年,以PUGC内容为核心的哔哩哔哩成立了,并且逐步从二次元内容向游戏、科技、动漫、影视、生活等多领域延伸。真正实现视频UGC的大规模普及还是由抖音(2016年)和快手推动,其用户超过70%都上传过内容。短视频的AIGC化也初见成效,MOBA类国民级游戏王者荣耀2020年7月上线了视频战报功能,可以将玩家的精彩瞬间汇集成1分钟的短视频内容。
游戏:游戏的互动性更强,其制作难度远高于视频。
1997年,全球第一款图形图像多人在线网络游戏《Ultima Online》由美国EA公司推出。至今为止,游戏的制作仍然以专业机构为主。
元宇宙第一股Roblox于2006年成立,是世界最大的多人在线创作游戏,其中大多数游戏作品都是用户自行建立,从FPS、RPGC到竞速、解密,全由玩家操控的圆柱和方块形小人参与完成。
Roblox尽管提供了非常优秀的创作工具,但其画面效果仍较为粗糙,游戏领域的UGC化并不普及。
另一个广为人知的游戏UGC案例是DOTA,其是基于《魔兽争霸》的地图编辑器而来,通过一系列特定的游戏规则和英雄,打造成风靡一时的游戏,并持续影响着诸如《英雄联盟》和《王者荣耀》等MOBA类游戏。

2.1.NLP:AIGC发展最早技术,多应用场景商业化落地
自然语言处理(NLP,Natural Language Processing)是研究人与计算机交互的语言问题的科学,是人工智能的核心课题之一。

基于NLP技术的文本生成则是AIGC发展最早的技术,已经在众多应用场景中大范围商业化落地。比如“搜索的自动更正”,当你在搜索引擎中输入几个文字后,系统自动显示可能的搜索关键词;当你搜索文字存在错别字的情况下,系统自动更正错别字。“语音助理”,像苹果Siri等,通过自然语言处理来理解用户的口头命令并执行相应的操作。
这些自然语言处理的应用场景如今可谓是随处可见。

NLP经历了“One-Hot”、“Word2Vec”、“Bert”等多代技术的更迭。
1)One-Hot是NLP的第一代技术,其做法简单,NLP以“词”为单位,将整个样本库的所有词转换成一个词典,不同的词做成不同的维度矩阵来表示。每一个维度代表一个词,不能重复。转换的过程就像填空题,将对应的维度位置作为1,那其他的剩余的维度位置都是0,这也是“One-Hot”用作命名的原因。
2)Word2Vec是NLP的第二代技术。One-Hot的运用简单粗暴,但大量的数字造成空间的浪费。Word2Vec是在第一代的基础上,塞进了CBOW模型(通过上下文的词预测中心词)、Skip-gram模型(通过中心词预测上下文的词),将其维度降低。Word2Vec与深度学习有着密不可分的关系,其能将关系表示出来,比如“King – Man Woman = Queen”。
3)Bert是NLP的第三代技术。One-Hot和Word2Vec在遇到多义词上显得比较乏力。Bert基于PTM(预训练模型),其在SQuAD任务中有着非常优秀的表现。Bert采用两阶段过程,第一个阶段是利用语言模型进行预训练,第二阶段通过Fine-tuning的模式解决下游任务。

NLP的核心任务是“判别”与“生成”。
1)自然语言理解:使计算机能够与人一样拥有正常的语言理解能力。以往,计算机只能处理结构化数据,而自然语言理解使得计算机能够识别语意。
2)自然语言生成:将非语言格式的数据转换成可以理解的语言格式,如文章等。自然语言生成主要包括:内容确定、文本结构、句子聚合、语法化、参考表达方式以及语言实现。
综合来看,自然语言理解是人工智能的基础功能,无论是文字、图片、视频还是游戏的AIGC,理解人类语言并转化成为计算机能够识别的数据都是非常有必要的。而自然语言生成是文字AIGC化的核心,最终的输出形式是符合人类理解的语言格式。
2.2.GAN:图像生成传统思路,仍需解决不稳定等问题
生成式对抗网络(GAN, Generative Adversarial Networks)是一种深度学习模型,是近年来复杂分布上无监督学习最具前景的方法之一。
其由生成器和判别器两部分组成,生成器将抓取数据、产生新的生成数据,并将其混入原始数据中送交判别器区分。
这一过程将反复进行,直到判别器无法以超过50%的准确度分辨出真实样本。

2014年,自Ian Goodfellow等人提出《对抗式生成网络》并将其应用于图片和视频领域,其应用场景不断丰富。Han Zhang等人于2016年发表题为《StackGAN:使用堆叠GAN技术进行文字-图片转化及合成》的论文,介绍了如何运用StackGAN将对于简单物体的文字描述转化为现实图片。
2018年,Andrew Brock等人发表了题为《用于高保真自然图像合成的GAN规模化训练》的论文,展示了用BigGAN技术生成合成照片。

相较于2014年初现期,现有的GAN在神经网络架构、损失函数设计、模型训练稳定性、模型崩溃问题上取得了相应突破,提升了最终图像的特定细节、内在逻辑、生成速度等。
但要在实际应用中大规模稳定应用,GAN仍需解决以下问题:
1)训练不稳定:GAN模型在相互博弈过程中容易造成训练不稳定,使得训练难以收敛。
2)样本大量重复相似:是GAN模型图像生成时最难解决的问题,会造成训练结果冗余、图像质量差和样本单一等问题。
3)GAN模型需要压缩:将GAN模型镶嵌入小型软件中,需要根据需求调整模型大小。
2.3.Diffusion:新一代图像生成主流模型,带动AIGC进入新篇章
2022年,Diffusion Model成为图像生成领域的重要发现,甚至有超越GAN的势头。其模型来源于2020年名为《Denoising Diffusion Probabilistic Models》的研究,并被DALL·E等应用而爆火。Diffusion Model和其他模型的不同点在于其latent code(z)和原图是同尺寸大小的。Diffusion Model通过前向过程(Forward diffusion process)往图片上添加噪声,再通过逆向过程(Reverse diffusion process)去噪推断过程。

估值200亿美元的人工智能巨头OpenAI专门写了一篇名为《Hierarchical Text-Conditional Image Generation with CLIP Latents》的论文,来说明用Diffusion Model生成的图像质量明显优于GAN模型。
此外,Stable AI 公司向公众开放了Stable Diffusion的预训练模型权重,任何人都可以在为普通消费者设计的硬件上下载和使用 Stable Diffusion。
也就是说,新一代图像生成模型Diffusion Model的竞争更多不是基于技术的,而是数据和商业化上的竞争。

3.1.Rosebud AI:广告行业采用率高,即将上线AI素材平台
Rosebud由Lisha Li于2018年创办,总部位于旧金山。Rosebud AI是一款生成文本、图像、视频和语音的工具,其使用 AI 以编程方式创建图像和视频,或者帮助创作者在没有智能合约或web3.0体验的情况下创建NFT集合。

此外,还通过将现有的计算机图形技术与AI研究相结合,提供创作和编辑视觉内容,使客户能够为旧照片添加动画并将其艺术赋予生命。

Rosebud AI的产品套件包括Synth、Tokkingheads和Pixelvibe等,覆盖了图片生成,衍生加工以及素材平台。
Synth是一款拥有移动端和网页端的利用AI创作包括字符、风景、人像等的智能角色生成器,可以从文本中创建角色、头像、动画、风景和艺术品。
例如,描述你想要创造的东西(“动漫女孩”),指定一个模型和美术风格(超过20种风格:动漫,幻想,现实,卡通等),点击“创建”,Synth只需要几秒钟就可以根据你的原始描述制作出一幅AI生成的艺术品。

Tokkingheads是一款即时人像动画应用程序,用户可以通过输入音频、文本或者上传即时动态视频,生成任意一个给定目标(包括照片、合成图片、动画等)的动画。
PixelVibe是公司即将上线的以AI生成为基础的素材摄影平台。PixelVibe 中,用户无须使用文字标签,可以通过点击目标图像,或者描述想要得到的图片,进而获得数以千计的相关素材。目前,公司已推出了超过10万张图片,并计划在未来几个月增加数百万张。

平台主要采取订阅式付费模式。目前,公司的产品均采用订阅式付费模式。其中,Tokkingheads的订阅付费模式价格在12.99美元/月 - 49.99美元/月,主要权益包括去水印、图像清晰度、视频长度等;Synth的会员价格为12.99欧元/月,主要权益包括水印,以及是否可以商用等。

由于推广某种产品或服务通常需要创建独特但重复的内容,例如拍摄模特的照片图像,因此公司的技术和产品在广告业和营销业采用率最高。
2021年,公司提供了超过25,000张为不同的虚拟人建模图像,可以供客户根据需求自由调整包括微笑程度、年龄、五官等特征,并将模型衣服穿到虚拟真实模型上,还可以根据详细的受众人口统计数据制作无限变化的模型并使用各种视觉效果来定位客户。
根据公司声明,利用他们的人工智能生成模型的第一个活动显示点击率增加了22%。

3.2.巴比特:率先媒体 AI 配图,一站式区块链版权存证
以 AI 创作自有版权图片取代付费图片库版权图片。2011-2014 年,长铗、吴忌寒创建巴比特,以白皮书和专著形式做区块链技术的传播推广。2015-2017 年,先后上线了巴比特区块链数据产品区块元和区块链公链项目比原链。2018 年至今,巴比特获普华资本、泛城资本联合领投、启赋资本、比特大陆跟投的 1 亿元 A 轮融资,收购信链社。近期,巴比特郑重宣布规模化采用 AIGC,以 AI 创作自有版权图片。
此前,巴比特内容使用的是国内主流的付费版权库图片,以及无版权图片库图片。现在,巴比特 AI 配图主要应用于自家自媒体平台头条图片、文章配图,包括但不限于巴比特网站和 APP、微信公众号、百家号、网易号等,以及微博等社交媒体账号。其中头条图片全部由 AI 创作,自采自写、编译翻译与转载的相关文章可以实现大规模 AI 配图,而专栏作者与海盗号投稿文章的配图尊重作者不做修改。

巴比特的 AI 配图全部通过旗下无界版图的 AI 创作生成,AI 创作画面描述以短句或短语为主,3 种模型、6 种画面比例及其各 2 种像素、手绘背景图等 20 种画面类型可供选择,还有参考图、风格修饰、艺术家选择的高级设置,全方位满足用户需求。

AI 创作属于无界版图增值服务,提供积分与 AI 创作权益卡两种支付形式。
积分可通过:1)新用户注册、实名认证、绑定银行卡等任务免费获得;2)购买作品获得;3)充值积分获得。
权益卡依据不同权益划分为五种等级,购买开通。用户作图可同步建立 AI 创作图片库的图片版权,可以通过区块链进行版权存证。
巴比特目前已经积累了包括元宇宙、区块链、Web3 等涵盖近百个关键词的千余张图片,且图库规模迅速扩大。
当自有 AI 图片库形成一定规模,可向专栏作者开放免费使用;待未来条件进一步成熟,也可对其他媒体、自媒体,甚至企业、公众开放。
未来也可联合不同类型的媒体机构,通过采用无界版图 AI 绘图,创作更多风格多样、内容多维的图片,以联盟的形式共建公共的图片库,让 AI 的技术真正赋能媒体的图片创作,变革当前图片库商业模式。

3.3.Artbreeder:人工智能合成创意工具,与他人协同创作
Artbreeder 是由艺术家 Joel Simon 与 Studio Morphogen 共同创建,以生成式对抗网络为基础的人工智能创意合成工具。Artbreeder 主要由 Splicer(接 合画)与 Collage(拼接画)两个模块组成,其中 Splicer 是 Artbreeder 出名的主因。
在 Splicer 中,以角色形象为例,用户可以通过上传图片或者使用网站上其他用户创作的作品作为基础,使用控制面板调整图片的原有“基因”,在创造角色形象的情况下原有“基因”将会是角色的发色、瞳色、性别特征、年龄等。用户可以在基础上选择“ADD PARENT”,即添加一个或多个合成对象来“繁育”,生成新的角色。
新的角色将会保留原有合成对象基因特征,用户可以结合喜好调整两个原有角色的基因比重。在原有基因调整与“繁育”之外用户还可以点击“ GENES”,即添加其他用户的自制基因,其中可能包括嘴唇厚度、头发长短、脸颊大小等。
如果用户想要更多具有共同特征的角色,图片下方的 “Multiple”功能能够让 AI 在 PARENT 的基础上随机生成多个可供调整的新形象。
角色展示界面中,上方显示的树状图是该角色的“族谱”,显示了角色是由哪些角色一步步合成的,且每一个“PARENT”也可被自由编辑;下方则显示了使用该角色作为“PARENT”所创造的其他角色。

Artbreeder 目前的主要变现模式是功能付费制,主要分为初级、高级与冠军级,价格分别为 8.99、18.99 与 38.99 美元/月。
用户可以按月/年购买使用资格,年付相较月付享有 20%的价格优惠。
用户通过付费开启的权限中包括上传图片数量增加、高清晰度图片下载数量增加、生成视频帧率更高、谷歌驱动同步、作品私密化与自制基因等。

AIGC 是继 PGC、UGC 后的新内容生产形态,是元宇宙和 Web3.0 的重要基础设施,其技术正在加速成熟。
AIGC 生成正从“降本增效”向“创造价值”转变,尤其在图片和视频领域。我们认为底层技术明确并预计 1-2 年规模化应用的领域主要是创意图像生成(按照特定属性生成画作)、功能性图像生成(根据指定要求形成营销海报)、文字生成图像。
行业公司:汉仪股份,视觉中国、蓝色光标、万兴科技、中文在线。

4.1.视觉中国:成熟商业化场景加持,布局 AIGC 可期
视觉中国是国内最早将互联网技术应用于版权视觉内容服务的平台型文化科技企业。
公司的核心商业模式为:服务全球优秀内容创作者,整合海量优质全面的图片、视频、音乐等数字版权内容,通过“优质内容 技术创新”建设网络服务平台为 B 端客户提供数字版权交易服务。
截至 2022 年上半年,公司直接签约客户数超过 1.4 万家,同比增长 6%;其中年度销售额 10 万元以上的长协客户续约率继续保持在 80%以上;通过互联网平台触达长尾用户继续保持快速增长,数量超过 200 万,较 2021 年上半年同比增长超过 100%。

AIGC 无疑是未来公司发展的重要一步。海外图片库 Shutterstock 已接入 Open AI,并为客户提供 AI 相关工具和服务。
从必要性的角度来看:AI 在图片领域的应用将颠覆传统的图片消费模式——从资源消耗变为 SaaS 模式、版权确认模式——从清晰确认变为要素共建。视觉中国作为传统图片库行业龙头,随着技术的发展不断变革自身的商业模式也是应有之义。此外,AIGC 不仅应用在传统图片库领域,也可以满足部分定制摄影的需求,进一步扩大公司的市场版图。
从护城河的角度来看:随着 Diffusion 模型开源,技术并不是 AIGC 的最终壁垒。通过数据不断锻炼模型,率先推出产品获取用户并实现商业化,二者是重中之重。而视觉中国已经拥有海量的付费用户(1.4 万直客和 200 万长尾客户)和成熟的商业化场景(图片库、媒体配图等),解决现在大量 AIGC 初创公司难以商业化的难题,实现真正的 B 端变现。
4.2.蓝色光标:创意画廊平台上线,聚焦 AI 营销场景
蓝色光标是为企业智慧经营赋能的数据科技公司,业务涉及营销服务、数字广告以及国际业务。旗下销博特是基于云端聚焦 AI 营销场景的多人协作工具平台,拥有营销日历、国风文案、AI 易稿、创意灯泡等多个功能性产品,通过结合人工智能、统计算法和多维数据库,一键自动化生成消费者所需内容。11 月 10 日,蓝色光标销博特“创意画廊”平台正式上线,一键生成抽象画。
销博特结合自身特点,将 AIGC 能力定位于“康定斯基模型”,其生成画作的风格更偏向“康定斯基”的“热抽象”。当前作图界面包括印象主义、后印象主义、油画、水彩在内的 11 种风格可供选择,用户选定一种风格,输入一个文本或上传一张图片,“康定斯基模型”会自动对文本/图片进行元素处理,打好标签,再根据标签元素调取数据库素材,匹配相应图片,并对图片场景进行联想,通过后台算法对需要表现的情绪进行推算,从而依据元素、构图、画风进行“康定斯基”式的风格创作。

当前“创意画廊”AI 作画部分是免费的在线形式,不需要注册和登录,完成之后可以在页面等待或在广场浏览。“康定斯基模型”后续会和此前营销日历等四大 API 一样,生成可直接调用的 API 接口,支持虚拟人创作、NFT 藏品、装饰画等实物画、AI 营销、DTC 电商等各领域的用户使用。
4.3.万兴科技:AI 绘画小程序公测,深耕元宇宙生态
万兴科技旗下软件“万兴 AI 绘画”已在微信小程序开启公测。
小程序分为随机生成与关键词创作两部分,其中随机生成功能为免费生成图片,但图片内容、风格不可控;关键词创作中用户可以通过输入关键词,在选择图片比例与图片风格后生成自己独有的作品。单个微信用户拥有 5 次免费关键词创作机会,目前万兴 AI 绘画主要通过售卖额外创作次数进行变现。

公司积极布局创作者经济,并在数字创意领域已沉淀多年,旗下明星产品包括万兴喵影、万兴喵库、亿图图示、亿图脑图、墨刀等,业务已覆盖 200 余个国家、地区,月活跃用户过亿。
公司在数字创意领域的丰富经验与庞大用户群的基础上拥抱元宇宙概念,布局虚拟数字人、虚拟场景、3D/AR/VR 软件应用,并与优链时代达成战略合作共建视频元宇宙生态,本次 AIGC 绘画软件的推出也是公司在智能创作领域的全新尝试。
4.4.汉仪股份:AI 助力字库设计,自动化及生产效率显著提升
汉仪股份是国内领先的专业从事字体设计、字库产品开发、汉字信息技术研究、汉字应用解决方案且拥有核心自主知识产权的文化创意与高新技术企业。近年来,随着人工智能技术的不断成熟和计算机运算能力的提升,公司也逐步将科技元素注入字体设计。
在字体产品创作环节,公司利用自研的人工智能等技术来提高效率。
公司利用基于手写字体识别技术、内容和风格解耦的字体多风格生成技术以及字体变形/字形家族化技术等有效提升了字库产品设计的自动化水平和生产效率。
根据公司招股说明书,在 C 端字体方面,目前公司已能够实现将一套仅 300 字左右的手稿自动拓展至 GB2312 编码中的全部 6,763 个汉字;B 端字体方面,可实现将一套仅 300-800 字左右的手稿自动拓展至 GB2312 编码中的全部 6,763 个汉字的字形。
同时,以人工智能生成的汉字字形轮廓图像清晰,风格上具有高度一致性,辅以精修即可快速成型,大幅提升了产品创作效率。

2018 年,汉仪字库与阿里巴巴合作推出了“阿里汉仪智能黑体”,这是阿里与汉仪合作的第一款 AI 字体,字形由汉仪字库的字体设计师黄珍元主创设计,字库产品协同阿里人机自然交互实验室,即由设计师创造字形特征,结合人工智能 AI 完成整套字库的设计。


商业化进程不及预期;
技术发展不及预期。
——————————————————
报告属于原作者,仅供学习!如有侵权,请私信删除,谢谢!
报告来自【远瞻智库】报告中心-远瞻智库|为三亿人打造的有用知识平台
,




