
文章来源:林骥微信公众号
作者:林骥
01你好,我是林骥。
散点图的用途有很多,我认为它的核心价值,在于应用相关思维,发现变量之间的关系。
散点图就像一扇窗,打开它,并仔细观察,能让我们看见更多有价值的信息。
比如说,假设表格中有 10000 个客户年龄和消费金额的数据:

我们可以计算每一个年龄对应的人均消费金额,比如说,所有 20 岁客户的平均消费金额约为 1383.69 元,然后我们可以画出一张散点图:
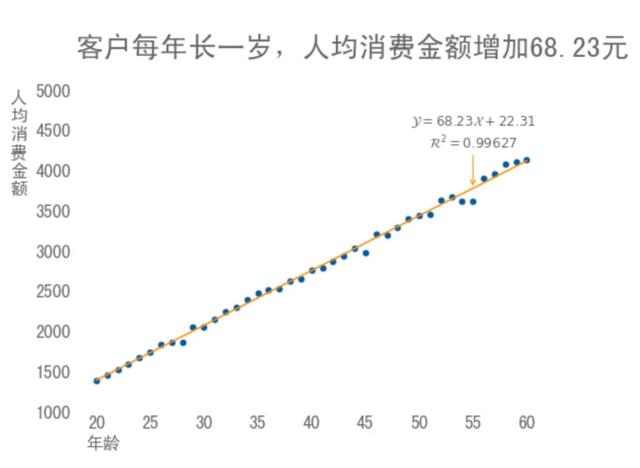
从图中可以看出,客户的年龄与人均消费金额有很强的相关性,其中应用了线性回归算法,得到一条拟合的直线,并用公式表示出来, 接近于 1 ,代表算法拟合的效果很好。
02接下来,我们看看具体实现的步骤。
首先,导入所需的库,并设置中文字体和定义颜色等。
#导入所需的库
importnumpyasnp
importpandasaspd
importmatplotlibasmpl
importmatplotlib.pyplotasplt
fromsklearn.linear_modelimportLinearRegression
fromsklearn.preprocessingimportPolynomialFeatures
fromsklearn.pipelineimportPipeline
#正常显示中文标签
mpl.rcParams['font.sans-serif']=['SimHei']
#自动适应布局
mpl.rcParams.update({'figure.autolayout':True})
#正常显示负号
mpl.rcParams['axes.unicode_minus']=False
#禁用科学计数法
pd.set_option('display.float_format',lambdax:'%.2f'%x)
#定义颜色,主色:蓝色,辅助色:灰色,互补色:橙色
c={'蓝色':'#00589F','深蓝色':'#003867','浅蓝色':'#5D9BCF',
'灰色':'#999999','深灰色':'#666666','浅灰色':'#CCCCCC',
'橙色':'#F68F00','深橙色':'#A05D00','浅橙色':'#FBC171'}
其次,从 Excel 文件中读取数据,并调用 sklearn 中的算法,得到拟合的直线和评分结果。
#数据源路径
filepath='./data/客户年龄和消费金额.xlsx'
#读取Excel文件
df=pd.read_excel(filepath,index_col='客户编号')
#定义画图用的数据:年龄和人均消费金额
df_group=df.groupby('年龄').mean()
x=np.array(df_group.index).reshape(-1,1)
y=np.array(df_group.values)
#用管道的方式调用算法,以便把线性回归扩展为多项式回归
poly_reg=Pipeline([
('ploy',PolynomialFeatures(degree=1)),
('lin_reg',LinearRegression())
])
#拟合
poly_reg.fit(x,y)
#斜率
coef=poly_reg.steps[1][1].coef_
#截距
intercept=poly_reg.steps[1][1].intercept_
#评分
score=poly_reg.score(x,y)
接下来,开始用「面向对象」的方法进行画图。
#使用「面向对象」的方法画图,定义图片的大小
fig,ax=plt.subplots(figsize=(8,6))
#设置标题
ax.set_title('\n客户每年长一岁,人均消费金额增加' '%.2f'%coef[0][1] '元\n',loc='left',size=26,color=c['深灰色'])
#画气泡图
ax.scatter(x,y,color=c['蓝色'],marker='.',s=100,zorder=1)
##绘制预测线
y2=poly_reg.predict(x)
ax.plot(x,y2,'-',c=c['橙色'],zorder=2)
#隐藏边框
ax.spines['top'].set_visible(False)
ax.spines['right'].set_visible(False)
ax.spines['bottom'].set_visible(False)
ax.spines['left'].set_visible(False)
#隐藏刻度线
ax.tick_params(axis='x',which='major',length=0)
ax.tick_params(axis='y',which='major',length=0)
ax.set_ylim(15,65)
ax.set_ylim(1000,5000)
#设置坐标标签字体大小和颜色
ax.tick_params(labelsize=16,colors=c['深灰色'])
ax.text(ax.get_xlim()[0]-6,ax.get_ylim()[1],'人\n均\n消\n费\n金\n额',va='top',fontsize=16,color=c['深灰色'])
#设置坐标轴的标题
ax.text(ax.get_xlim()[0] 1,ax.get_ylim()[0]-300,'年龄',ha='left',va='top',fontsize=16,color=c['深灰色'])
#预测55岁的人均消费金额
predict=poly_reg.predict([[55]])
#标注公式
formula=r'$\mathcal{Y}=' '%.2f'%coef[0][1] '\mathcal{X}' '% .2f$'%intercept[0] '\n' r'$\mathcal{R}^2=' '%.5f$'%score
ax.annotate(formula,xy=(55,predict),xytext=(55,predict 500),ha='center',fontsize=12,color=c['深灰色'],arrowprops=dict(arrowstyle='->',color=c['橙色']))
plt.show()
你可以前往 https://github.com/linjiwx/mp 下载数据文件和完整代码。
03当业务指标很多的时候,应该挑选什么指标来进行分析,这件事很考验分析者的功力,往往需要对业务有比较深刻的理解。
为什么很多人精通各种工具技术,手上也有很多各种各样的数据,却没有做出让领导满意的图表?
好的图表,就像是给近视的人戴了一副眼镜,让读者以更清楚的方式去理解数据。
好的图表,就像是神奇的催化剂,加快了从数据到决策的过程,让决策者更加快速地掌握有助于做出决策的信息。
好的图表,能把复杂的问题简单化,帮我们更精准地理解业务的现状,甚至预测未来。
我们应该记住,无论多么漂亮的图表,如果不能从中获取有价值的信息,那么也是一张没有「灵魂」的图表。
很多时候,我们面对的问题,并不是没有数据,而是数据太多,却不知道怎么用。
熟悉数据分析的思维,能帮我们找到更重要的数据,排除过多杂乱数据的干扰。
如果把数据分析比作医生看病的过程,那么可以分为以下 4 个阶段:
(1)描述:检查身体,描述指标值是否正常。
(2)诊断:询问病情,找到疾病的产生原因。
(3)预测:分析病情,预测病情的发展趋势。
(4)指导:开出药方,提出有效的治疗建议。
我们要尽可能地理解业务并提供价值,从数据的加工者,转变成故事的讲述者,甚至是问题的解决者。
,




