之前有小伙伴私信我说看源码的时候感觉源码很难,不知道该怎么看,其实这有部分原因是因为没有弄懂一些源码实现的套路,也就是设计模式,所以本文我就总结了9种在源码中非常常见的设计模式,并列举了很多源码的实现例子,希望对你看源码和日常工作中有所帮助。
单例模式单例模式是指一个类在一个进程中只有一个实例对象(但也不一定,比如Spring中的Bean的单例是指在一个容器中是单例的)
单例模式创建分为饿汉式和懒汉式,总共大概有8种写法。但是在开源项目中使用最多的主要有两种写法:
1、静态常量静态常量方式属于饿汉式,以静态变量的方式声明对象。这种单例模式在Spring中使用的比较多,举个例子,在Spring中对于Bean的名称生成有个类AnnotationBeanNameGenerator就是单例的。

AnnotationBeanNameGenerator
2、双重检查机制除了上面一种,还有一种双重检查机制在开源项目中也使用得比较多,而且在面试中也比较喜欢问。双重检查机制方式属于懒汉式,代码如下:
public class Singleton {
private volatile static Singleton INSTANCE;
private Singleton() {
}
public static Singleton getInstance() {
if (INSTANCE == null) {
synchronized (Singleton.class) {
if (INSTANCE == null) {
INSTANCE = new Singleton();
}
}
}
return INSTANCE;
}
}
之所以这种方式叫双重检查机制,主要是在创建对象的时候进行了两次INSTANCE == null的判断。
疑问讲解这里解释一下双重检查机制的三个疑问:
- 外层判断null的作用
- 内层判断null的作用
- 变量使用volatile关键字修饰的作用
外层判断null的作用:其实就是为了减少进入同步代码块的次数,提高效率。你想一下,其实去了外层的判断其实是可以的,但是每次获取对象都需要进入同步代码块,实在是没有必要。
内层判断null的作用:防止多次创建对象。假设AB同时走到同步代码块,A先抢到锁,进入代码,创建了对象,释放锁,此时B进入代码块,如果没有判断null,那么就会直接再次创建对象,那么就不是单例的了,所以需要进行判断null,防止重复创建单例对象。
volatile关键字的作用:防止重排序。因为创建对象的过程不是原子,大概会分为三个步骤
- 第一步:分配内存空间给Singleton这个对象
- 第二步:初始化对象
- 第三步:将INSTANCE变量指向Singleton这个对象内存地址
假设没有使用volatile关键字发生了重排序,第二步和第三步执行过程被调换了,也就是先将INSTANCE变量指向Singleton这个对象内存地址,再初始化对象。这样在发生并发的情况下,另一个线程经过第一个if非空判断时,发现已经为不为空,就直接返回了这个对象,但是此时这个对象还未初始化,内部的属性可能都是空值,一旦被使用的话,就很有可能出现空指针这些问题。
双重检查机制在dubbo中的应用在dubbo的spi机制中获取对象的时候有这样一段代码:

虽然这段代码跟上面的单例的写法有点不同,但是不难看出其实是使用了双重检查机制来创建对象,保证对象单例。
建造者模式将一个复杂对象的构造与它的表示分离,使同样的构建过程可以创建不同的表示,这样的设计模式被称为建造者模式。它是将一个复杂的对象分解为多个简单的对象,然后一步一步构建而成。
上面的意思看起来很绕,其实在实际开发中,其实建造者模式使用的还是比较多的,比如有时在创建一个pojo对象时,就可以使用建造者模式来创建:
PersonDTO personDTO = PersonDTO.builder()
.name("三友的Java日记")
.age(18)
.sex(1)
.phone("188****9527")
.build();
上面这段代码就是通过建造者模式构建了一个PersonDTO对象,所以建造者模式又被称为Budiler模式。
这种模式在创建对象的时候看起来比较优雅,当构造参数比较多的时候,适合使用建造者模式。
接下来就来看看建造者模式在开源项目中是如何运用的
1、在Spring中的运用我们都知道,Spring在创建Bean之前,会将每个Bean的声明封装成对应的一个BeanDefinition,而BeanDefinition会封装很多属性,所以Spring为了更加优雅地创建BeanDefinition,就提供了BeanDefinitionBuilder这个建造者类。

BeanDefinitionBuilder
2、在Guava中的运用在项目中,如果我们需要使用本地缓存,会使用本地缓存的实现的框架来创建一个,比如在使用Guava来创建本地缓存时,就会这么写
Cache<String, String> cache = CacheBuilder.newBuilder()
.expireAfterAccess(1, TimeUnit.MINUTES)
.maximumSize(200)
.build();
这其实也就是建造者模式。
建造者模式不仅在开源项目中有所使用,在JDK源码中也有使用到,比如StringBuilder类。
最后上面说的建造者模式其实算是在Java中一种简化的方式,如果想了解一下传统的建造者模式,可以看一下这篇文章
https://m.runoob.com/design-pattern/builder-pattern.html?ivk_sa=1024320u
工厂模式工厂模式在开源项目中也使用得非常多,具体的实现大概可以细分为三种:
简单工厂模式
- 简单工厂模式
- 工厂方法模式
- 抽象工厂模式
简单工厂模式,就跟名字一样,的确很简单。比如说,现在有个动物接口Animal,具体的实现有猫Cat、狗Dog等等,而每个具体的动物对象创建过程很复杂,有各种各样地步骤,此时就可以使用简单工厂来封装对象的创建过程,调用者不需要关心对象是如何具体创建的。
public class SimpleAnimalFactory { public Animal createAnimal(String animalType) { if ("cat".equals(animalType)) { Cat cat = new Cat(); //一系列复杂操作 return cat; } else if ("dog".equals(animalType)) { Dog dog = new Dog(); //一系列复杂操作 return dog; } else { throw new RuntimeException("animalType=" animalType "无法创建对应对象"); } } }当需要使用这些对象,调用者就可以直接通过简单工厂创建就行。
SimpleAnimalFactory animalFactory = new SimpleAnimalFactory(); Animal cat = animalFactory.createAnimal("cat");需要注意的是,一般来说如果每个动物对象的创建只需要简单地new一下就行了,那么其实就无需使用工厂模式,工厂模式适合对象创建过程复杂的场景。
工厂方法模式上面说的简单工厂模式看起来没啥问题,但是还是违反了七大设计原则的OCP原则,也就是开闭原则。所谓的开闭原则就是对修改关闭,对扩展开放。
什么叫对修改关闭?就是尽可能不修改的意思。就拿上面的例子来说,如果现在新增了一种动物兔子,那么createAnimal方法就得修改,增加一种类型的判断,那么就此时就出现了修改代码的行为,也就违反了对修改关闭的原则。
所以解决简单工厂模式违反开闭原则的问题,就可以使用工厂方法模式来解决。
/** * 工厂接口 */ public interface AnimalFactory { Animal createAnimal(); } /** * 小猫实现 */ public class CatFactory implements AnimalFactory { @Override public Animal createAnimal() { Cat cat = new Cat(); //一系列复杂操作 return cat; } } /** * 小狗实现 */ public class DogFactory implements AnimalFactory { @Override public Animal createAnimal() { Dog dog = new Dog(); //一系列复杂操作 return dog; } }这种方式就是工厂方法模式。他将动物工厂提取成一个接口AnimalFactory,具体每个动物都各自实现这个接口,每种动物都有各自的创建工厂,如果调用者需要创建动物,就可以通过各自的工厂来实现。
AnimalFactory animalFactory = new CatFactory(); Animal cat = animalFactory.createAnimal();此时假设需要新增一个动物兔子,那么只需要实现AnimalFactory接口就行,对于原来的猫和狗的实现,其实代码是不需要修改的,遵守了对修改关闭的原则,同时由于是对扩展开放,实现接口就是扩展的意思,那么也就符合扩展开放的原则。
抽象工厂模式工厂方法模式其实是创建一个产品的工厂,比如上面的例子中,AnimalFactory其实只创建动物这一个产品。而抽象工厂模式特点就是创建一系列产品,比如说,不同的动物吃的东西是不一样的,那么就可以加入食物这个产品,通过抽象工厂模式来实现。
public interface AnimalFactory { Animal createAnimal(); Food createFood(); }在动物工厂中,新增了创建食物的接口,小狗小猫的工厂去实现这个接口,创建狗粮和猫粮,这里就不去写了。
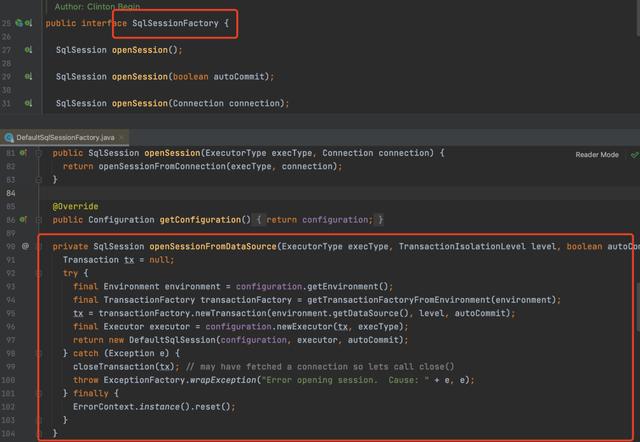
1、工厂模式在Mybatis的运用在Mybatis中,当需要调用Mapper接口执行sql的时候,需要先获取到SqlSession,通过SqlSession再获取到Mapper接口的动态代理对象,而SqlSession的构造过程比较复杂,所以就提供了SqlSessionFactory工厂类来封装SqlSession的创建过程。
SqlSessionFactory及默认实现DefaultSqlSessionFactory
对于使用者来说,只需要通过SqlSessionFactory来获取到SqlSession,而无需关心SqlSession是如何创建的。
2、工厂模式在Spring中的运用我们知道Spring中的Bean是通过BeanFactory创建的。
BeanFactory就是Bean生成的工厂。一个Spring Bean在生成过程中会经历复杂的一个生命周期,而这些生命周期对于使用者来说是无需关心的,所以就可以将Bean创建过程的逻辑给封装起来,提取出一个Bean的工厂。
策略模式策略模式也比较常见,就比如说在Spring源码中就有很多地方都使用到了策略模式。
在讲策略模式是什么之前先来举个例子,这个例子我在之前的《写出漂亮代码的45个小技巧》文章提到过。
假设现在有一个需求,需要将消息推送到不同的平台。
最简单的做法其实就是使用if else来做判断就行了。
public void notifyMessage(User user, String content, int notifyType) { if (notifyType == 0) { //调用短信通知的api发送短信 } else if (notifyType == 1) { //调用app通知的api发送消息 } }根据不同的平台类型进行判断,调用对应的api发送消息。
虽然这样能实现功能,但是跟上面的提到的简单工厂的问题是一样的,同样违反了开闭原则。当需要增加一种平台类型,比如邮件通知,那么就得修改notifyMessage的方法,再次进行else if的判断,然后调用发送邮件的邮件发送消息。
此时就可以使用策略模式来优化了。
首先设计一个策略接口:
public interface MessageNotifier { /** * 是否支持改类型的通知的方式 * * @param notifyType 0:短信 1:app * @return */ boolean support(int notifyType); /** * 通知 * * @param user * @param content */ void notify(User user, String content); }短信通知实现:
@Component public class SMSMessageNotifier implements MessageNotifier { @Override public boolean support(int notifyType) { return notifyType == 0; } @Override public void notify(User user, String content) { //调用短信通知的api发送短信 } }app通知实现:
public class AppMessageNotifier implements MessageNotifier { @Override public boolean support(int notifyType) { return notifyType == 1; } @Override public void notify(User user, String content) { //调用通知app通知的api } }最后notifyMessage的实现只需要要循环调用所有的MessageNotifier的support方法,一旦support方法返回true,说明当前MessageNotifier支持该类的消息发送,最后再调用notify发送消息就可以了。
@Resource private List<MessageNotifier> messageNotifiers; public void notifyMessage(User user, String content, int notifyType) { for (MessageNotifier messageNotifier : messageNotifiers) { if (messageNotifier.support(notifyType)) { messageNotifier.notify(user, content); } } }那么如果现在需要支持通过邮件通知,只需要实现MessageNotifier接口,注入到Spring容器就行,其余的代码根本不需要有任何变动。
到这其实可以更好的理解策略模式了。就拿上面举的例子来说,短信通知,app通知等其实都是发送消息一种策略,而策略模式就是需要将这些策略进行封装,抽取共性,使这些策略之间相互替换。
策略模式在SpringMVC中的运用1、对接口方法参数的处理比如说,我们经常在写接口的时候,会使用到了@PathVariable、@RequestParam、@RequestBody等注解,一旦我们使用了注解,SpringMVC会处理注解,从请求中获取到参数,然后再调用接口传递过来,而这个过程,就使用到了策略模式。
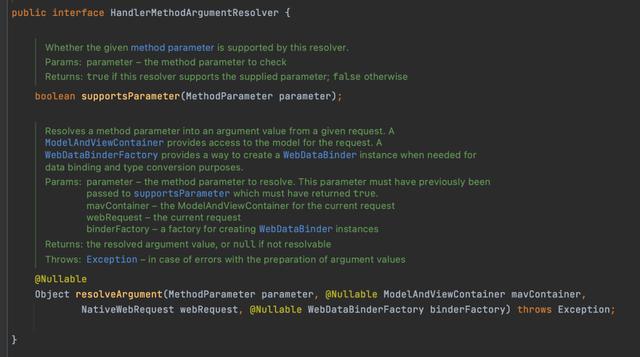
对于这类参数的解析,SpringMVC提供了一个策略接口HandlerMethodArgumentResolver
HandlerMethodArgumentResolver
这个接口的定义就跟我们上面定义的差不多,不同的参数处理只需要实现这个解决就行,比如上面提到的几个注解,都有对应的实现。
比如处理@RequestParam注解的RequestParamMethodArgumentResolver的实现。
RequestParamMethodArgumentResolver
当然还有其它很多的实现,如果想知道各种注解处理的过程,只需要找到对应的实现类就行了。
2、对接口返回值的处理同样,SpringMVC对于返回值的处理也是基于策略模式来实现的。
HandlerMethodReturnValueHandler
HandlerMethodReturnValueHandler接口定义跟上面都是同一种套路。
比如说,常见的对于@ResponseBody注解处理的实现RequestResponseBodyMethodProcessor。
ResponseBody注解处理的实现RequestResponseBodyMethodProcessor
同样,HandlerMethodReturnValueHandler的实现也有很多,这里就不再举例了。
策略模式在Spring的运用远不止这两处,就比如我在《三万字盘点Spring/Boot的那些常用扩展点》文章提到过对于配置文件的加载PropertySourceLoader也是策略模式的运用。
模板方法模式模板方法模式是指,在父类中定义一个操作中的框架,而操作步骤的具体实现交由子类做。其核心思想就是,对于功能实现的顺序步骤是一定的,但是具体每一步如何实现交由子类决定。
比如说,对于旅游来说,一般有以下几个步骤:
- 做攻略,选择目的地
- 收拾行李
- 乘坐交通工具去目的地
- 玩耍、拍照
- 乘坐交通工具去返回
但是对于去哪,收拾什么东西都,乘坐什么交通工具,都是由具体某个旅行来决定。
那么对于旅游这个过程使用模板方法模式翻译成代码如下:
public abstract class Travel { public void travel() { //做攻略 makePlan(); //收拾行李 packUp(); //去目的地 toDestination(); //玩耍、拍照 play(); //乘坐交通工具去返回 backHome(); } protected abstract void makePlan(); protected abstract void packUp(); protected abstract void toDestination(); protected abstract void play(); protected abstract void backHome(); }对于某次旅行来说,只需要重写每个步骤该做的事就行,比如说这次可以选择去杭州西湖,下次可以去长城,但是对于旅行过程来说是不变了,对于调用者来说,只需要调用暴露的travel方法就行。
可能这说的还是比较抽象,我再举两个模板方法模式在源码中实现的例子。
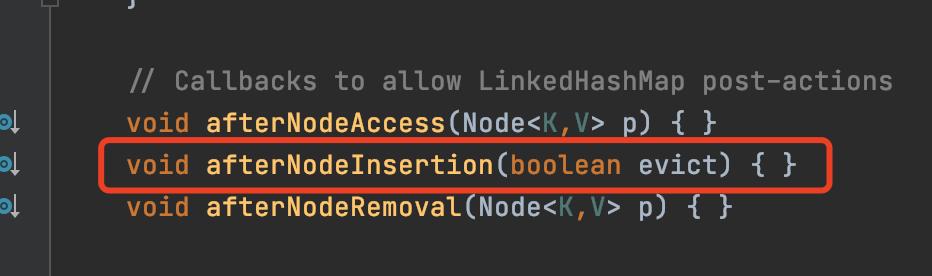
模板方法模式在源码中的使用1、模板方法模式在HashMap中的使用HashMap我们都很熟悉,可以通过put方法存元素,并且在元素添加成功之后,会调用一下afterNodeInsertion方法。
而afterNodeInsertion其实是在HashMap中是空实现,什么事都没干。
afterNodeInsertion
这其实就是模板方法模式。HashMap定义了一个流程,那就是当元素成功添加之后会调用afterNodeInsertion,子类如果需要在元素添加之后做什么事,那么重写afterNodeInsertion就行。
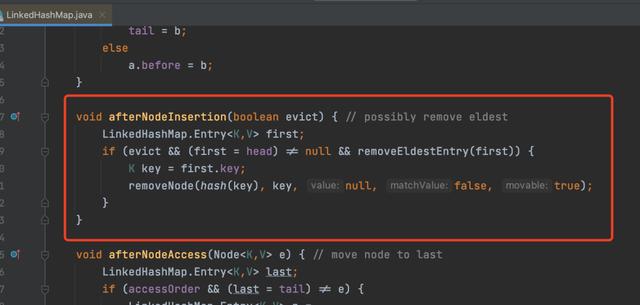
正巧,JDK中的LinkedHashMap重写了这个方法。
而这段代码主要干的一件事就是可能会移除最老的元素,至于到底会不会移除,得看if是否成立。
添加元素移除最老的元素,基于这种特性其实可以实现LRU算法,比如Mybatis的LruCache就是基于LinkedHashMap实现的,有兴趣的可以扒扒源码,这里就不再展开讲了。
2、模板方法模式在Spring中的运用我们都知道,在Spring中,ApplicationContext在使用之前需要调用一下refresh方法,而refresh方法就定义了整个容器刷新的执行流程代码。
refresh方法部分截图
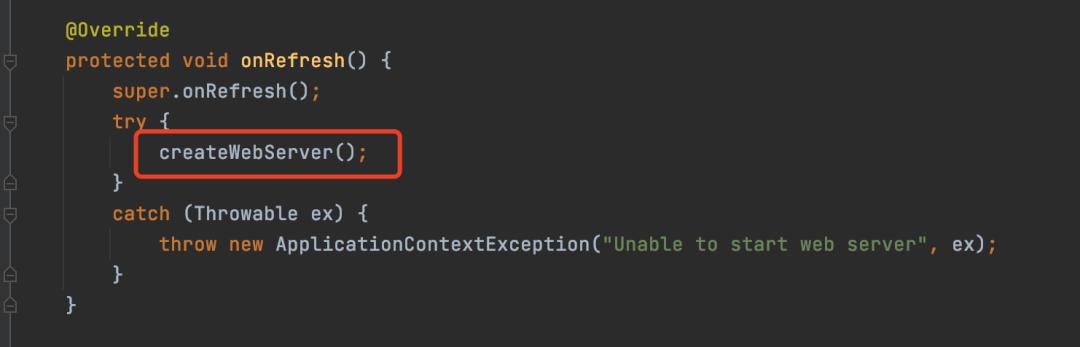
在整个刷新过程有一个onRefresh方法
onRefresh方法
而onRefresh方法默认是没有做任何事,并且在注释上有清楚两个单词Template method,翻译过来就是模板方法的意思,所以onRefresh就是一个模板方法,并且方法内部的注释也表明了,这个方法是为了子类提供的。
在Web环境下,子类会重写这个方法,然后创建一个Web服务器。
3、模板方法模式在Mybatis中的使用
在Mybatis中,是使用Executor执行Sql的。
Executor
而Mybatis一级缓存就在Executor的抽象实现中BaseExecutor实现的。如图所示,红圈就是一级缓存
BaseExecutor
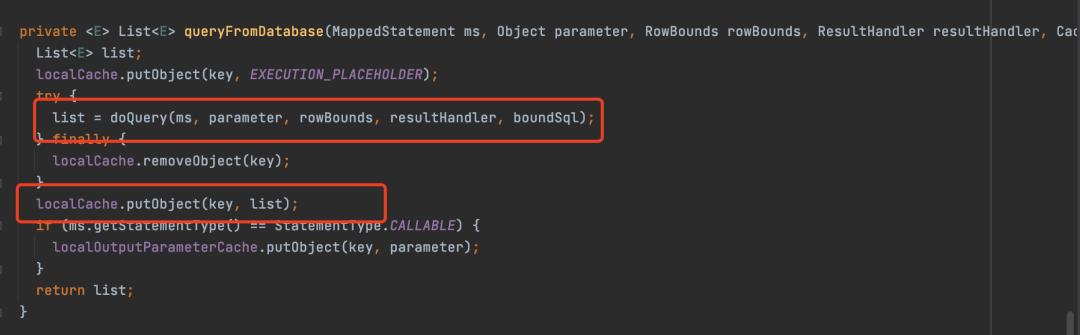
比如在查询的时候,如果一级缓存有,那么就处理缓存的数据,没有的话就调用queryFromDatabase从数据库查
queryFromDatabase会调用doQuery方法从数据库查数据,然后放入一级缓存中。
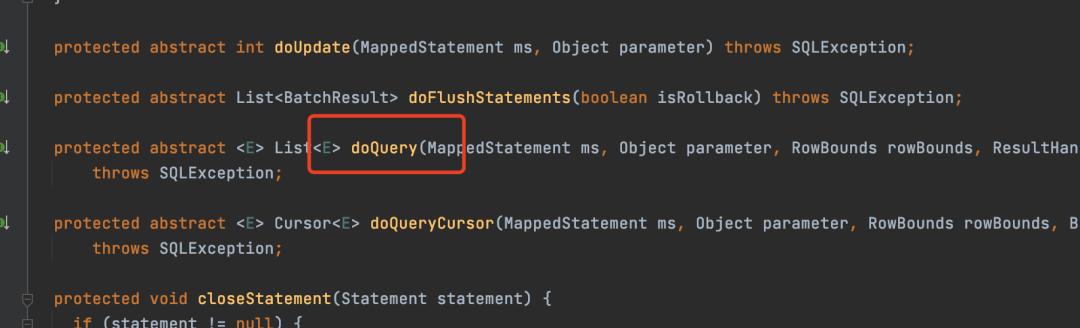
而doQuery是个抽象方法
所以doQuery其实就是一个模板方法,需要子类真正实现从数据库中查询数据,所以这里就使用了模板方法模式。
责任链模式在责任链模式里,很多对象由每一个对象对其下家的引用而连接起来形成一条链。请求在这个链上传递,由该链上的某一个对象或者某几个对象决定处理此请求,每个对象在整个处理过程中值扮演一个小小的角色。
举个例子,现在有个请假的审批流程,根据请假的人的级别审批到的领导不同,比如有有组长、主管、HR、分管经理等等。
先需要定义一个处理抽象类,抽象类有个下一个处理对象的引用,提供了抽象处理方法,还有一个对下一个处理对象的调用方法。
public abstract class ApprovalHandler { /** * 责任链中的下一个处理对象 */ protected ApprovalHandler next; /** * 设置下一个处理对象 * * @param approvalHandler */ public void nextHandler(ApprovalHandler approvalHandler) { this.next = approvalHandler; } /** * 处理 * * @param approvalContext */ public abstract void approval(ApprovalContext approvalContext); /** * 调用下一个处理对象 * * @param approvalContext */ protected void invokeNext(ApprovalContext approvalContext) { if (next != null) { next.approval(approvalContext); } } }几种审批人的实现
//组长审批实现 public class GroupLeaderApprovalHandler extends ApprovalHandler { @Override public void approval(ApprovalContext approvalContext) { System.out.println("组长审批"); //调用下一个处理对象进行处理 invokeNext(approvalContext); } } //主管审批实现 public class DirectorApprovalHandler extends ApprovalHandler { @Override public void approval(ApprovalContext approvalContext) { System.out.println("主管审批"); //调用下一个处理对象进行处理 invokeNext(approvalContext); } } //hr审批实现 public class HrApprovalHandler extends ApprovalHandler { @Override public void approval(ApprovalContext approvalContext) { System.out.println("hr审批"); //调用下一个处理对象进行处理 invokeNext(approvalContext); } }有了这几个实现之后,接下来就需要对对象进行组装,组成一个链条,比如在Spring中就可以这么玩。
@Component public class ApprovalHandlerChain { @Autowired private GroupLeaderApprovalHandler groupLeaderApprovalHandler; @Autowired private DirectorApprovalHandler directorApprovalHandler; @Autowired private HrApprovalHandler hrApprovalHandler; public ApprovalHandler getChain() { //组长处理完下一个处理对象是主管 groupLeaderApprovalHandler.nextHandler(directorApprovalHandler); //主管处理完下一个处理对象是hr directorApprovalHandler.nextHandler(hrApprovalHandler); //返回组长,这样就从组长开始审批,一条链就完成了 return groupLeaderApprovalHandler; } }之后对于调用方而言,只需要获取到链条,开始处理就行。
一旦后面出现需要增加或者减少审批人,只需要调整链条中的节点就行,对于调用者来说是无感知的。
责任链模式在开源项目中的使用1、在SpringMVC中的使用在SpringMVC中,可以通过使用HandlerInterceptor对每个请求进行拦截。
HandlerInterceptor
而HandlerInterceptor其实就使用到了责任链模式,但是这种责任链模式的写法跟上面举的例子写法不太一样。
对于HandlerInterceptor的调用是在HandlerExecutionChain中完成的。
HandlerExecutionChain
比如说,对于请求处理前的拦截,就在是这样调用的。
其实就是循环遍历每个HandlerInterceptor,调用preHandle方法。
2、在Sentinel中的使用Sentinel是阿里开源的一个流量治理组件,而Sentinel核心逻辑的执行其实就是一条责任链。
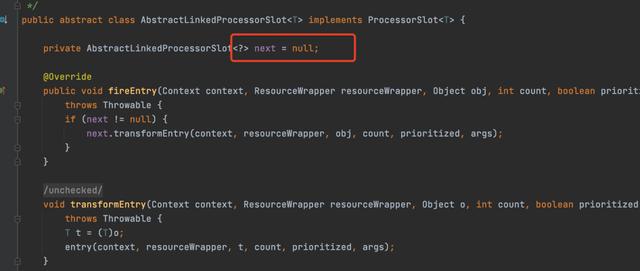
在Sentinel中,有个核心抽象类AbstractLinkedProcessorSlot
AbstractLinkedProcessorSlot
这个组件内部也维护了下一个节点对象,这个类扮演的角色跟例子中的ApprovalHandler类是一样的,写法也比较相似。这个组件有很多实现
比如有比较核心的几个实现
- DegradeSlot:熔断降级的实现
- FlowSlot:流量控制的实现
- StatisticSlot:统计的实现,比如统计请求成功的次数、异常次数,为限流提供数据来源
- SystemSlot:根据系统规则来进行流量控制
整个链条的组装的实现是由DefaultSlotChainBuilder实现的
DefaultSlotChainBuilder
并且内部是使用了SPI机制来加载每个处理节点
所以,如果你想自定一些处理逻辑,就可以基于SPI机制来扩展。
除了上面的例子,比如Gateway网关、Dubbo、MyBatis等等框架中都有责任链模式的身影,所以责任链模式使用的还是比较多的。
代理模式代理模式也是开源项目中很常见的使用的一种设计模式,这种模式可以在不改变原有代码的情况下增加功能。
举个例子,比如现在有个PersonService接口和它的实现类PersonServiceImpl
//接口 public interface PersonService { void savePerson(PersonDTO person); } //实现 public class PersonServiceImpl implements PersonService{ @Override public void savePerson(PersonDTO person) { //保存人员信息 } }这个类刚开始运行的好好的,但是突然之前不知道咋回事了,有报错,需要追寻入参,所以此时就可以这么写。
public class PersonServiceImpl implements PersonService { @Override public void savePerson(PersonDTO person) { log.info("savePerson接口入参:{}", JSON.toJSONString(person)); //保存人员信息 } }这么写,就修改了代码,万一以后不需要打印日志了呢,岂不是又要修改代码,不符和之前说的开闭原则,那么怎么写呢?可以这么玩。
public class PersonServiceProxy implements PersonService { private final PersonService personService = new PersonServiceImpl(); @Override public void savePerson(PersonDTO person) { log.info("savePerson接口入参:{}", JSON.toJSONString(person)); personService.savePerson(person); } }可以实现一个代理类PersonServiceProxy,对PersonServiceImpl进行代理,这个代理类干的事就是打印日志,最后调用PersonServiceImpl进行人员信息的保存,这就是代理模式。
当需要打印日志就使用PersonServiceProxy,不需要打印日志就使用PersonServiceImpl,这样就行了,不需要改原有代码的实现。
讲到了代理模式,就不得不提一下Spring AOP,Spring AOP其实跟静态代理很像,最终其实也是调用目标对象的方法,只不过是动态生成的,这里就不展开讲解了。
代理模式在Mybtais中的使用前面在说模板方法模式的时候,举了一个BaseExecutor使用到了模板方法模式的例子,并且在BaseExecutor这里面还完成了一级缓存的操作。
其实不光是一级缓存是通过Executor实现的,二级缓存其实也是,只不过不在BaseExecutor里面实现,而是在CachingExecutor中实现的。
CachingExecutor
CachingExecutor中内部有一个Executor类型的属性delegate,delegate单词的意思就是代理的意思,所以CachingExecutor显然就是一个代理类,这里就使用到了代理模式。
CachingExecutor的实现原理其实很简单,先从二级缓存查,查不到就通过被代理的对象查找数据,而被代理的Executor在Mybatis中默认使用的是SimpleExecutor实现,SimpleExecutor继承自BaseExecutor。
这里思考一下二级缓存为什么不像一级缓存一样直接写到BaseExecutor中?
这里我猜测一下是为了减少耦合。
我们知道Mybatis的一级缓存默认是开启的,一级缓存写在BaseExecutor中的话,那么只要是继承了BaseExecutor,就拥有了一级缓存的能力。
但二级缓存默认是不开启的,如果写在BaseExecutor中,讲道理也是可以的,但不符和单一职责的原则,类的功能过多,同时会耦合很多判断代码,比如开启二级缓存走什么逻辑,不开启二级缓存走什么逻辑。而使用代理模式很好的解决了这一问题,只需要在创建的Executor的时候判断是否开启二级缓存,开启的话就用CachingExecutor代理一下,不开启的话老老实实返回未被代理的对象就行,默认是SimpleExecutor。
如图所示,是构建Executor对象的源码,一旦开启了二级缓存,就会将前面创建的Executor进行代理,构建一个CachingExecutor返回。
适配器模式
适配器模式使得原本由于接口不兼容而不能一起工作的哪些类可以一起工作,将一个类的接口转换成客户希望的另一个接口。
举个生活中的例子,比如手机充电器接口类型有USB TypeC接口和Micro USB接口等。现在需要给一个Micro USB接口的手机充电,但是现在只有USB TypeC接口的充电器,这怎么办呢?
其实一般可以弄个一个USB TypeC转Micro USB接口的转接头,这样就可以给Micro USB接口手机充电了,代码如下
USBTypeC接口充电
public class USBTypeC { public void chargeTypeC() { System.out.println("开启充电了"); } }MicroUSB接口
public interface MicroUSB { void charge(); }适配实现,最后是调用USBTypeC接口来充电
public class MicroUSBAdapter implements MicroUSB { private final USBTypeC usbTypeC = new USBTypeC(); @Override public void charge() { //使用usb来充电 usbTypeC.chargeTypeC(); } }方然除了上面这种写法,还有一种继承的写法。
public class MicroUSBAdapter extends USBTypeC implements MicroUSB { @Override public void charge() { //使用usb来充电 this.chargeTypeC(); } }这两种写法主要是继承和组合(聚合)的区别。
这样就可以通过适配器(转接头)就可以实现USBTypeC给MicroUSB接口充电。
适配器模式在日志中的使用在日常开发中,日志是必不可少的,可以帮助我们快速快速定位问题,但是日志框架比较多,比如Slf4j、Log4j等等,一般同一系统都使用一种日志框架。
但是像Mybatis这种框架来说,它本身在运行的过程中也需要产生日志,但是Mybatis框架在设计的时候,无法知道项目中具体使用的是什么日志框架,所以只能适配各种日志框架,项目中使用什么框架,Mybatis就使用什么框架。
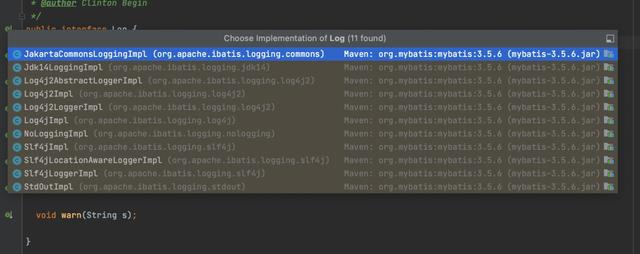
为此Mybatis提供一个Log接口
而不同的日志框架,只需要适配这个接口就可以了
Slf4jLoggerImpl
就拿Slf4j的实现来看,内部依赖了一个Slf4j框架中的Logger对象,最后所有日志的打印都是通过Slf4j框架中的Logger对象来实现的。
此外,Mybatis还提供了如下的一些实现
这样,Mybatis在需要打印日志的时候,只需要从Mybatis自己的LogFactory中获取到Log对象就行,至于最终获取到的是什么Log实现,由最终项目中使用日志框架来决定。
观察者模式
当对象间存在一对多关系时,则使用观察者模式(Observer Pattern)。比如,当一个对象被修改时,则会自动通知依赖它的对象。
这是什么意思呢,举个例子来说,假设发生了火灾,可能需要打119、救人,那么就可以基于观察者模式来实现,打119、救人的操作只需要观察火灾的发生,一旦发生,就触发相应的逻辑。
观察者的核心优点就是观察者和被观察者是解耦合的。就拿上面的例子来说,火灾事件(被观察者)根本不关系有几个监听器(观察者),当以后需要有变动,只需要扩展监听器就行,对于事件的发布者和其它监听器是无需做任何改变的。
观察者模式实现起来比较复杂,这里我举一下Spring事件的例子来说明一下。
观察者模式在Spring事件中的运用Spring事件,就是Spring基于观察者模式实现的一套API,如果有不知道不知道Spring事件的小伙伴,可以看看《三万字盘点Spring/Boot的那些常用扩展点》这篇文章,里面有对Spring事件的详细介绍,这里就不对使用进行介绍了。
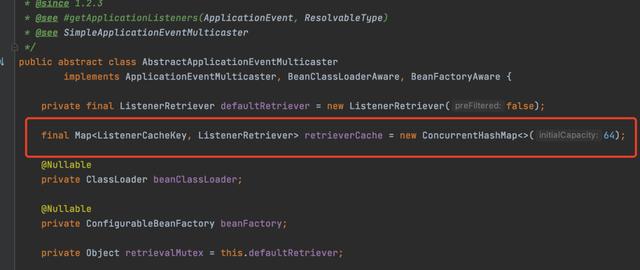
Spring事件的实现比较简单,其实就是当Bean在生成完成之后,会将所有的ApplicationListener接口实现(监听器)添加到ApplicationEventMulticaster中。
ApplicationEventMulticaster可以理解为一个调度中心的作用,可以将事件通知给监听器,触发监听器的执行。
ApplicationEventMulticaster可以理解为一个总线
retrieverCache中存储了事件类型和对应监听器的缓存。当发布事件的时候,会通过事件的类型找到对应的监听器,然后循环调用监听器。
所以,Spring的观察者模式实现的其实也不复杂。
总结本文通过对设计模式的讲解加源码举例的方式介绍了9种在代码设计中常用的设计模式:
- 单例模式
- 建造者模式
- 工厂模式
- 策略模式
- 模板方法模式
- 责任链模式
- 代理模式
- 适配器模式
- 观察者模式
其实这些设计模式不仅在源码中常见在平时工作中也是可以经常使用到的。
设计模式其实还是一种思想,或者是套路性的东西,至于设计模式具体怎么用、如何用、代码如何写还得依靠具体的场景来进行灵活的判断。
最后,本文又是前前后后花了一周多的时间完成,如果对你有点帮助,还请帮忙点赞、在看、转发、非常感谢。
原文链接:https://mp.weixin.qq.com/s/N-Q1rLzpZeNNNjQYq_AY4w
,