点击上方关注,All in AI中国通过试验Tensorflow v2.0 Alpha,逐步生成钢琴音乐“♪♪♪”
大家好,在这篇文章中,我会分享给大家一些关于人工智能的实验,教大家如何使用深度学习生成音符,与我之前关于生成歌词的文章不同,这次我们将生成音乐笔记并生成文件(MIDI格式)。
音乐的主角是钢琴。本文将在自我注意的帮助下,使用递归神经网络(RNN),门控递归单元(GRU)的变体生成钢琴音符。本文不仅将介绍如何生成笔记,还将介绍如何将其生成为正确的MIDI文件,可以在计算机中播放。
本文针对的是对AI感兴趣的人,尤其是那些想要练习深度学习的人。我希望通过发表这篇文章来增加我的写作技巧,并也对你的文章内容产生帮助。
如果您想了解完整的源代码,那么本文末尾有一个Github链接。现在,我将在存储库中提供python笔记本和Colaboratory链接。
这是开场音乐
声音1:打开钢琴
(该音乐是由我们将在本文中创建的模型生成的)
大纲
- 介绍
- 技术与数据
- 管道
- 预处理MIDI文件
- 训练模型
- 推理和生成MIDI文件
- 结果
- 结论
- 后记
介绍
人工智能当前的热门话题之一是如何仅使用数据(无监督)来生成某些东西。在计算机视觉领域,有许多研究人员正在研究使用生成Advesarial网络(GAN)生成图像的一些先进技术。例如,NVIDIA使用GAN创建逼真的面部生成器。还有一些关于使用GAN生成音乐的研究。
如果我们谈论音乐发生器的价值,它可以用来帮助音乐家创作他们的音乐。它可以增强人们的创造力。我想在未来,如果在这个领域有很多高度关注,大多数音乐家都会创作出由AI辅助的产生音乐。
本文将重点介绍如何通过在音乐中生成连续的音符来生成音乐。我们将知道如何预处理数据并将其转换为神经网络的输入以生成音乐。
该实验还将使用Tensorflow v2.0(仍处于alpha阶段)作为深度学习框架。我想要展示的是通过遵循他们的一些最佳实践来测试和使用Tensorflow v2.0。我在Tensorflow v2.0中喜欢的一个功能是它通过使用AutoGraph来加速模型的训练。它可以通过使用@tf.function定义我们的函数来使用。而且,再也没有“tf.session”,也没有全局初始化。这些特征是我从Tensorflow转移到PyTorch的原因之一。 Tensorflow可用性可能对于我来说不太好。尽管如此,在我看来,Tensorflow v2.0改变了这一切并增加了它们的可用性,使得做一些实验变得舒适。
该实验还使用自我注意层。自我注意层将告诉我们,给定一个顺序实例(例如在音乐笔记“C D E F G”中),每个标记将了解对该标记的其他标记的影响程度。这是一些例子(对于NLP任务):
图1:注意力的可视化
有关自我注意的更多信息,特别是有关transformer的信息,您可以阅读这篇很棒的文章。
没有任何进一步的问题,让我们继续生成音乐
技术与数据
这个实验将使用:
- Tensorflow v2.0:深度学习框架、Tensorflow的新版本,仍处于alpha阶段的开发阶段。
- Python 3.7
- Colaboratory:免费的Jupyter笔记本环境,无需设置即可完全在云中运行。拥有GPU Tesla K80甚至TPU!可悲的是,Tensorflow v2.0 alpha在撰写本文时仍然不支持TPU。
- Python库pretty_midi:一个用于操作和创建MIDI文件的库
对于数据,我们使用来自Magenta的MAESTRO(MIDI和音频编辑用于同步TRacks和组织)作为数据集。此数据集仅包含钢琴乐器。我们将从大约1000个音乐中随机抽取100个音乐,以加快我们的训练时间。
管道
以下是关于我们的音乐生成器如何工作的管道:
图2:管道
我们将看到每个过程。为简化起见,我们将每个流程划分如下:
- 预处理MIDI文件作为神经网络的输入
- 训练过程
- 生成MIDI文件
预处理MIDI文件
在讨论如何预处理midi文件之前,我们需要知道midi格式文件是什么。
从pcmag中,MIDI的定义为:
(乐器数字接口)乐器、合成器和计算机之间音乐信息交换的标准协议。MIDI的开发使一台合成器的键盘可以播放另一台合成器产生的音符。它为音符以及按钮、拨盘和踏板的调整定义了代码,MIDI控制消息可以编排一系列合成器,每个合成器都扮演乐谱的一部分。MIDI 1.0版于1983年引入。
总之,MIDI文件包含了一系列包含注释的工具。例如钢琴和吉他的组合,每种乐器通常有不同的音符。
对于预处理MIDI文件,有一些库可以在Python中使用。其中一个是pretty_midi。它可以操作MIDI文件,还可以创建一个新文件。在本文中,我们将使用这个库。
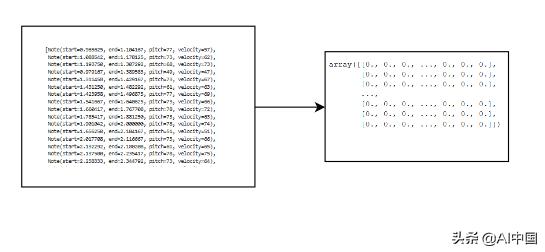
pretty_midi文件格式如下:
图3:PrettyMidi格式
开始是第二个音符的开始。结束是一秒钟内演奏的音符的结束。一次可以有多个音符重叠。音高是演奏音符的MIDI数字。速度是发出音符的力。
MIDI数字与注名的关系参考如下图:
图4:Midi数字和注释名称
阅读Midi文件
我们将批量读取midi文件,这是我们使用pretty_midi读取它的方式:
midi_pretty_format = pretty_midi.PrettyMIDI (“song.mid”)
我们将得到PrettyMidi对象。
对钢琴卷轴阵列进行预处理
图5:从pretty tymidi到Piano Roll Array
在本文中,我们需要从乐器中提取所有的音符。许多MIDI文件的音乐中有多种乐器。在我们的数据集中,MIDI文件只包含一种乐器,那就是钢琴。我们将从钢琴乐器中提取音符。为了更简单,我们将提取所需帧每秒的音符。pretty_midi有一个方便的函数get_piano_roll来获取二进制2D numpy中的音符。数组在(注释、时间)维度数组中,音符长度为128,时间按照音乐的时长除以FPS。
我们怎么做的源代码:
预处理到字典的时间和笔记
图6:钢琴卷轴数组到字典
在得到钢琴卷轴的数组之后,我们将它们转换成字典。字典将从音符播放的时间开始。例如,在上面的图中,我们从28开始(如果我们转换到秒,假设我们转换到piano_roll的速度是5 fps,音乐开始播放的速度是5.6 s,我们可以用28除以5)。
创建字典之后,我们将把字典的值转换为字符串。例如:
array([49,68]) => '49,68'
要做到这一点,我们应该循环字典的所有键并改变它的值:
for key in dict_note: dict_note[key] = ','.join(dict_note[key])
预处理要输入的音符列表和神经网络的目标
图7:字典来列出序列
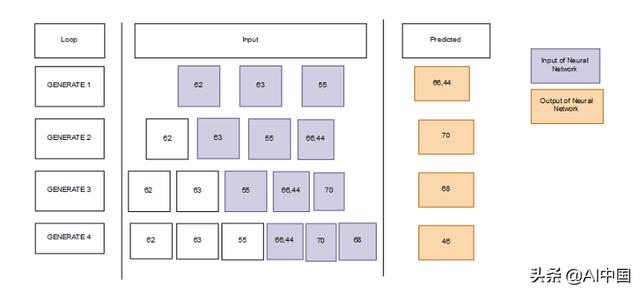
当我们得到字典后,将它转换成连续的笔记,这些笔记将被用来作为神经网络的输入。然后我们得到下一个时间步长作为神经网络输入的目标。
图8:滑动窗口
在本文中,序列列表的长度为50。这意味着如果我们的fps是5,将得到一个包含10秒(50 / 5)游戏时间的序列。
列表中的“e”表示在这段时间内没有演奏音符。因为有时候每个音符之间会有一个跳跃或者没有音符。在图7中的示例中,我们可以看到从43跳到46。如果我们转换这个序列,序列的列表将是:
[…'61,77', '61,77', 'e', 'e', '73',…]
我们怎么做呢?我们将用一批音乐来处理这个音符。
我们使用一个50长度的滑动窗口。对于音乐中的第一个音符,我们将在列表中添加“e”49次。然后将开始时间设置为字典中的第一个timestep。在图7中的例子中,它是28。然后我们在音乐中添加第一个音符(在示例‘77’中)。
然后对于下一个实例,我们将窗口滑动1次,并向列表中添加48次“e”,并将timestep 28中播放的音符添加到列表中,将timestep 29中播放的音符添加到列表中,并重复操作,直到音乐结束。
在下一段音乐中,我们重复上面的过程。
这是源代码:
创建注意分词器
在我们深入研究神经网络之前,我们必须创建标记器以将顺序音符更改为音符的顺序索引。首先,我们应该将音符映射到表示音符id的索引。
例如:
{ '61,77' : 1, # 61,77 will be identified as 1 'e' : 2, '73' : 3, . . }
如果我们之前的输入如下:
[...,'61,77','61,77','e','e','73',......]
我们将其转换为:
[... 1,1,2,2,3 ......]
这是我们的做法。
总结我们的预处理功能,以下是我们将使用的功能:
训练模型
在我们了解如何使用Tensorflow v2.0的新功能进行训练之前,我们将看到如下架构:
神经网络架构
图9:我们的神经网络架构
因此,深度学习架构将使用3层门控循环单元(GRU,一种回归神经网络的变体)和一些自注意层。使用丢失使得神经网络不会过快地过度拟合。
对于Self Attention Layers,我们将使用此存储库并对其进行一些编辑,以便我们可以在Tensorflow v2.0上使用它。
因此,深度学习架构将使用3层门控递归单元(GRU,递归神经网络的一种变体)和一些自我注意层。该方法采用了跳脱法,使神经网络不会快速过拟合。
对于Self - Attention层,我们将使用这个存储库并稍微编辑一下,以便在Tensorflow v2.0上使用它。
代码:
训练
我们将通过迭代数据集中的多个音乐来更新模型的权重,并如上所述预处理数据。然后,以一批待输入的实例和神经网络的目标为例。
我们将使用GradientTape来更新神经网络的权重。首先,我们使用apply_gradients计算损失并应用反向传播。如果您熟悉使用PyTorch,这就是Pytorch在训练其神经网络模型方面的工作方式。
务必在函数上使用@ tf.function。这会将功能转换为签名并使我们的训练更快。 tf.function的一个缺点是不能使用不同大小的批量作为神经网络的输入。例如,我们的批量大小为64。如果数据集的大小为70,则最后一批将包含6个实例。这将使程序抛出异常,因为图形将具有与初始图形不同大小的输入。也许它的工作原理是通过在使用函数时查看第一个输入来创建占位符。
在本文中,我们将使用16 BATCH_SONG和96 BATCH_NNET_SIZE。这意味着我们将从所有音乐列表中获取16个音乐,然后提取其序列。然后,对于神经网络中的每一步,我们从提取的序列实例中获取96个序列作为神经网络的输入和目标。
代码如下:
推理和生成MIDI文件
图10:推理和生成MIDI文件
使用我们训练的神经网络模型生成MIDI文件有两种方法:
我们需要在开始时选择:
- 我们生成随机50个音符作为音乐的开头。
- 我们使用49个空音符('e'),然后是我们选择的开始音符(例如'72',确保音符在NoteTokenizer中)。
图11:关于生成器如何工作的可视化
在我们选择音乐生成器的种子之后,使用我们训练的模型基于50个随机音符预测下一个音符。我们使用预测值作为如何随机选择音符的概率分布,这样做直到我们想要的指定的最大序列长度。然后我们放下前50个音符。
在我们生成音符列表序列之后,将其再次转换为钢琴卷轴阵列。然后将其转换为PrettyMidi对象。
之后,我们调整音乐的速度和节奏,最后我们生成MIDI文件。
代码 :
这是如何从生成的注释中编写midi文件:
结果
当我这样做时,训练耗时1小时,持续1个 epoch。当我这样做时,我决定进行4个 epoch(4个小时)的训练。
已经训练了4个 epoch的模型,结果如下:
由于头条号限制,只能发送一条音频,故详细资料请私信小编,回复“音乐”即可免费获取。
(请注意,这些是从MIDI文件转换而来的mp3文件。我使用在线转换器来执行此操作,这些注释似乎有点遗漏。如果您想听到,我会将原始MIDI上传到存储库中。)
这些生成的笔记之间存在明显差异。如果我们用一个音符生成它,它将在播放音符时节奏缓慢。它与我们从50个随机音符生成它时不同。它没有缓慢的开始。
这是在选择以随机50个音符开始的音乐的最后序列上的自我注意块的可视化:
首先注意
图12:第一次自我注意
第二个注意
图13:第二次自我注意
正如您所看到的,第一个自我注意块会学习在序列实例中为每个音符聚焦的音符。然而,在第二个关注区块中没有关注什么结果。我们还可以判断,如果其他音符的位置离当前音符很远,则它不会聚焦于它(图像12和图像13中的黑色)。
结论
我们使用包含钢琴音乐的MAESTRO数据集构建了一个生成音乐的工具。我们预处理它,训练我们的神经网络模型,然后用它生成音乐。音乐是MIDI格式。我们使用Tensorflow v2.0来完成它。我认为Tensorflow v2.0用户体验(UX)比以前的版本更好。
我们的模型产生的音乐也很连贯,很好听。它可以调整播放音符的方式。例如:当发生器从音符(意味着它是音乐的开头)时,它以慢节奏开始。
我们可以尝试一些音乐生成器。在本文中,我们已经尝试生成单个仪器。如果音乐有多种乐器怎么办?需要有一个更好的架构来做到这一点。我们可以尝试多种方法来试验音乐数据。
后记
这就是关于生成钢琴音乐笔记的文章。实际上,通过查看我的第一篇关于深度学习的文章,我得到了启发,这就是生成音乐的抒情效果。 “如何生成音符?”我做了一个试验它很有效。
对我来说,试验这个有一些困难。首先,我需要搜索易于预处理和输入神经网络的文件格式。我发现MIDI很简单,文件很小。然后,我需要知道是否有任何库可以在Python中预处理文件。我找到了两个,有music21和pretty_midi,他们的存储库没有过时,我选择pretty_midi。最后,我需要考虑如何预处理笔记。值得庆幸的是,pretty_midi有一个方便的函数get_piano_roll来使它更容易。
我还没有读过很多关于音乐的研究论文。也许有一些研究论文可以在Colaboratory中复制和显示。
自我注意层缺乏可视化效果。
存储库:https://github.com/haryoa/note_music_generator
,