近日,清华AMiner发布了最新的人工智能发展月报,3 月份 AI 业内的重大科研事件数量有所下降,本月共计发生 507 篇新闻、180 个事件,热度趋势如下图所示。最受关注的事件是 2022 世界移动通信大会,由于大会聚焦 5G、云网络、人工智能、万物互联以及“元宇宙”技术等主题,成为舆论焦点;此外,《2022 年人工智能指数》与《2021-2022 全球计算力指数评估》两份重磅报告的发布引发了 AI 业内人士较多关注;英伟达在 GTC 2022上推出 Omniverse 平台新功能,热度也较高。
本期的智能内参,我们推荐清华AMiner的报告《人工智能发展月报》,跟踪最新的人工智能发展动态。
来源 AMiner
原标题:
《人工智能发展月报》
作者:未注明
一、AI顶会与奖项1、 2022 世界移动通信大会在西班牙召开
2 月 28 日至 3 月 3 日,2022 世界移动通信大会在西班牙巴塞罗那召开。来自全球近 200 个国家的超过 6.1 万人参会,超过 1000 人在大会上发表演讲。本届大会聚焦 5G、云网络、人工智能、金融科技、万物互联和新兴科技 6 大主题,旨在“连接释放无限可能”。首次大规模亮相的“元宇宙”备受瞩目,除了对技术本身的讨论外,元宇宙的盈利模式、相关伦理问题等也成为人们关注焦点。
中国移动、中国联通、中国电信中国三大运营商负责人集体以线上方式亮相大会主旨演讲,中国移动表示计划到今年底累计开通 5G 基站超百万个,推动 5G 网络客户规模超 3.3 亿户,打造 5G 商用案例超万个;中国电信表示,率先实现了云、网络、IT(信息技术)的统一运营,不断推进云网融合,已经取得初步成效;中国联通助力北京打造了“第一届真正意义上的 5G 冬奥会”。
2、 CVPR 2022 论文接收量比去年上升 24%
计算机视觉三大顶会之一 CVPR2022 接收结果已经公布,共有 2067 篇论文被接收,相较于 2021 年的 1663 篇论文,接收率上升了 24%;有效投稿量数据还没有放出。截至 3 月 24 日,官网已公布 350 篇论文,涉及方向包括:检测、分割、视频处理、估计、图像处理、人脸、目标跟踪、图像&视频检索/视频理解、医学影像、文本检测/识别/理解、遥感图像、GAN/生成式/对抗式、图像生成/图像合成、三维视觉、模型压缩、神经网络结构设计等。
3、图灵奖授予高性能计算领域先驱 Jack Dongarra
3 月 30 日,美国计算机协会(ACM)将 2021 年的图灵奖授予美国田纳西大学电气工程和计算机科学系特聘教授、现年 71 岁的 Jack J.Dongarra,表彰他在数值算法和工具库方面的开创性贡献,使高性能计算软件能够跟上四十多年来的指数级硬件改进。据 ACM 介绍,Dongarra 的算法和软件推动了高性能计算发展,并对从人工智能到计算机图形学的多个计算科学领域产生了重大影响。

4、全美计算机研究生院排名:MIT、CMU 分别称霸总榜和 AI 分榜
3 月 29 日,2023 U.S.News 全美研究生院排名正式发布。最佳计算机科学研究生院排名 5 名分别为,第 1 名麻省理工学院(MIT)、并列第 2 的卡内基·梅隆大学(CMU)、斯坦福大学和加利福尼亚大学伯克利分校(UCB),以及第 5名伊利诺伊大学厄巴纳-香槟分校(UIUC)。
在人工智能专业上,排名第一是卡内基·梅隆大学(CMU)。

全美人工智能专业排名
5、智谱榜单:人工智能全球女性学者美国占比超 6 成,中国 23 人入围
近日,2022 年“人工智能相关领域全球女性学者”名单公布,入围人数共262 人,分布在全球 19 个国家。从国别分布看,美国共入围 161 人,占比 61.5%;其次是中国(含港澳台地区),共有 23 人,占 8.8%;第三是英国,共有 14 人;从机构分布看,全球前十强机构中,美国占 8 家,谷歌排名全球第一,中国和法国各占 1 家,清华大学是我国唯一一家进入前十强的机构;从研究领域分布看,排名依次是人机交互(51 人次)、可视化(24 人次)、知识工程(22 人次)、机器学习(6 人次)、机器人(6 人次)和计算机系统(7 人次);在 262 人中,共有 71 位华人,占比达 27.1%,而 71 位华人中,23 位工作单位在中国,48 位工作单位在外国。
6、华人博士获 ACM SIGSOFT 杰出博士论文奖
2022 ACM SIGSOFT Outstanding Doctoral Dissertation Award(杰出博士论文奖)已公布,唯一的名额授予了美国 UIUC 大学的华人博士生 Wing Lam(林永政),以表彰他在软件工程方面所做出的杰出贡献。

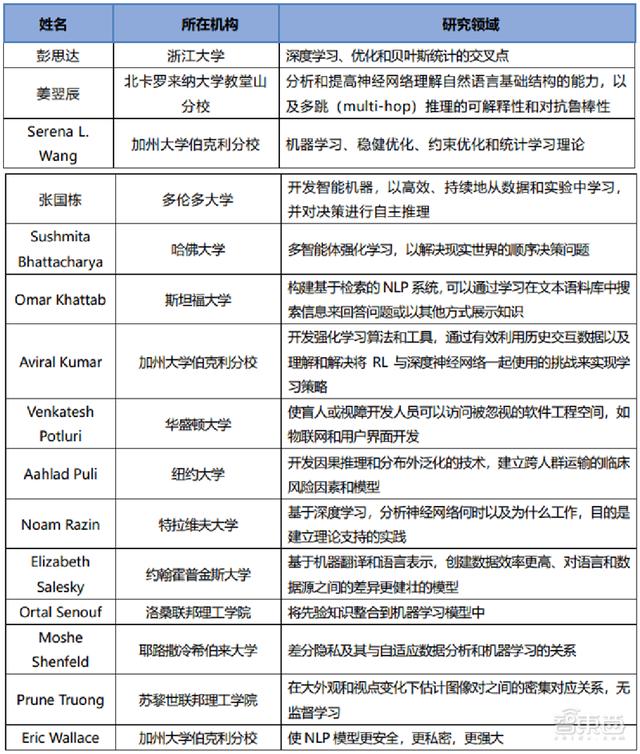
7、2022 苹果博士奖学金名单:浙大一博士生入选
近日,苹果宣布了 2022 年人工智能/机器学习领域的博士生奖学金名单,共有 15 位学生入选,包括 4 位华人博士生,其中一位是来自浙江大学计算机科学专业的彭思达,师从周晓巍教授。
1、 寒武纪副总经理兼首席技术官梁军已离职
3 月 14 日,寒武纪公告称:原副总经理、首席技术官梁军因与公司存在分歧,已于 2 月 10 日通知公司解除劳动合同,目前已办理完离职手续,此后将不再担任公司的任何职务。梁军自 2017 年加入公司,任职期间曾参与研究并申请发明专利 138 项、PCT 10 项,均为非单一发明人。其中 14 项发明专利已授权,其余仍处于审查阶段。
2、 英特尔图形部门顶级专家 Mike Burrows 跳槽 AMD
曾担任英特尔专注游戏和图形技术的 Advanced Technologies Group 的负责人、首席技术官和总监 Mike Burrows,近日宣布以公司副总裁的身份加入AMD 团队,领导其高级图形项目。在 AMD,Burrows 将专注于实时光线追踪和机器学习领域的研究。此外,他还将涉及包括与图形和计算解决方案的缩放相关的技术,以及数据压缩类技术。
3、 滴滴实验室(洛杉矶)首席科学家 Kevin Knight 离职
近日,原任滴滴实验室(洛杉矶)自然语言处理组首席科学家的 NLP 大神Kevin Knight 宣布将从滴滴实验室离职。此外,Kevin Knight 还是南加州大学(USC)计算机科学系院长教授以及 ACL 2011 的大会主席,2014 年同年入选ACL Fellow、AAAI Fellow,他的学术成果颇多,研究方向涵盖人工智能、自然语言处理、机器翻译、对话处理等。
4、前百度 Apollo 平台研发总经理王京傲加盟自动驾驶初创公司
前百度副总裁、Apollo 平台研发总经理王京傲,加盟自动驾驶初创公司云骥智行,担任联合创始人及 CTO。王京傲本科毕业于北京大学,于美国辛辛那提大学获得计算机工程硕士学位后,又在加州大学伯克利分校取得 MBA 学位,目前拥有 60 多项中美专利。他曾负责百度的自动驾驶 Apollo 开放平台的整体研发、规划和运营,并主导 Apollo 平台 1.0 到 7.0 所有版本的开发和迭代;之前,曾任职谷歌,是安卓 1.0 初创团队成员之一。云骥智行成立于 2021 年 11 月。在今年的 GTC 2022 大会上,云骥智行宣布将与英伟达合作,在自动驾驶芯片(DRIVE Orin SoC)上搭载云骥智行最新的 L4 级自动驾驶计算平台。
三、各 AI 子领域重要科研进展1、机器学习
牛津大学:研究者提出了受物理启发的持续学习模型,从微分几何、代数拓扑和微分方程等领域出发开启了一系列新工具的研究,可以克服传统 GNN 的局限性。
微软、斯坦福大学:就过度参数化(overparameterization)现象,研究者认为比预期规模更大的神经网络是必要的,通过提出平滑性,来指出需要多少个参数才能用一条具有等同于鲁棒性的数学特性的曲线来拟合数据点。论文标题:A Universal Law of Robustness viaIsoperimetry 论文链接:https://www.aminer.cn/pub/60b18ba891e011537459563f
上海交通大学、Mila 魁北克人工智能研究所、字节跳动:提出了一种基于层级语义结构的选择性对比学习框架(Hiearchical Contrastive Selective Coding,HCSC),通过将图像表征进行层级聚类,构造具有层级结构的原型向量(hierarchical prototypes),并通过这些原型向量选择更加符合语义结构的负样本进行对比学习,由此将层级化的语义信息融入到图像表征中,在多个下游任务中达到卷积神经网络自监督预训练方法的 SOTA 性能。
论文标题:HCSC: Hierarchical Contrastive SelectiveCoding 论文链接:https://www.aminer.cn/pub/61f9f64a5aee126c0f41f3fb
斯坦福大学:研究了在预训练文本具有远程连贯性的数学设置下,预训练分布对上下文学习的实现所起的作用,证明了当预训练分布是混合隐马尔可夫模型时,上下文学习是通过对潜在概念进行贝叶斯推理隐式地产生的,生成了一系列小规模合成数据集(GINC),在这个过程中,Transformer 和LSTM 语言模型都使用了上下文学习。论文标题:An Explanation of In-Context Learning asImplicit Bayesian Inference
论文链接:https://www.aminer.cn/pub/61834f695244ab9dcb55ccf8
阿里巴巴:提出了一个叫做猎豹(Cheetah)的新型框架,用于深度神经网络的两方计算网络推理系统,并重新设计了基于同态加密的协议,可在不需要任何轮调操作(RotationOperation)的情况下评估线性层(即卷积、批量归一化和完全连接);设计了几个用于非线性函数(如 ReLU 和Truncation)的更加精简,通信效率更高的基元。
德国希尔德斯海姆大学:评估了特征工程多输出 GBRT 模型,该研究将一个简单的机器学习方法 GBRT 提升了竞品 DNN 时间序列预测模型的标准;实证了为什么基于窗口的 GBRT 输入设置可以在时间序列预测领域提高 ARIMA 和原版 GBRT 等精心配置的模型所产生的预测性能;比较了 GBRT 与各种SOTA 深度学习时间序列预测模型的性能,并验证了它在单变量和双变量时间序列预测任务中的竞争力。
论文标题:Do We Really Need Deep Learning Modelsfor Time Series Forecasting? 论文链接:https://www.aminer.cn/pub/5ff6e10891e011b497e290a0
中国科学技术大学:针对移动为中心的模型推理场景,提出端到端可学的输入过滤框架 InFi (INput FIlter),对输入过滤问题进行了形式化建模,并基于推理模型和输入过滤器的函数族复杂性对比,在理论层面上对推理任务的可过滤性进行分析,InFi框架涵盖了现有的 SOTA 方法所使用的推理跳过和推理重用机制。
论文标题:InFi: End-to-end Learnable Input Filter forResource-efficient Mobilecentric Inference
清华大学:针对无监督时序异常检测问题,提出了基于关联差异的异常检测模型 Anomaly transformer,并通过一个极小极大(Minimax)关联学习策略大幅提高了模型的异常检测能力。该模型在服务器监测、地空探索、水流观测等应用中均展现出优秀的异常检测结果,应用落地价值强。论文标题:Anomaly Transformer: Time SeriesAnomaly Detection with Association Discrepancy
论文链接:https://www.aminer.cn/pub/615e657b5244ab9dcbf21edf
清华大学:模仿海马体的神经元权重更新机制,在 Nature Communications 上提出了一种结合全局与局部权重更新规则的混合模型,并验证了该模型在高噪声、小数据量、持续学习三种任务场景下的优越性,为神经形态算法及其硬件实现的协同开发开辟了一条新的路径。论文标题:Brain-inspired global-local learningincorporated with neuromorphic computing
论文链接:https://www.aminer.cn/pub/6100beb26750f816c6958070
瑞士托埃尔特公司:TOELT LLC 联合创始人兼首席 AI 科学家 Umberto Michelucci 全面介绍了自编码器的由来、定义、由编码器、潜在特征表示和解码器三部分组成,并详细介绍了编码器和解编码器。
论文标题:An Introduction to Autoencoders 论文链接:https://www.aminer.cn/pub/61de47035244ab9dcb3057c2
清华大学、旷视科技等:通过一系列探索实验,总结了在现代 CNN 中应用超大卷积核的五条准则,并基于以上准则,借鉴 Swin Transformer 宏观架构,提出了一种 RepLKNet 架构。
论文标题:Scaling Up Your Kernels to 31×31:Revisiting Large Kernel Design in CNNs 论文链接:https://www.aminer.cn/pub/623004305aee126c0f9b3828
布朗大学:该论文提出了强化学习中蕴含的抽象理论,指出执行抽象过程的函数所必备的三要素:维护近似最优行为的表示、它们应该被有效地学习和构建;计划或学习时间不应该太长。然后提出了一套新的算法和分析方案,阐明智能体如何根据这些要素学会抽象。论文标题:A Theory of Abstraction in ReinforcementLearning 论文链接:https://www.aminer.cn/pub/621ee1895aee126c0f26ae12
微软、OpenAI:首次提出了基础研究如何调优大型神经网络(这些神经网络过于庞大而无法多次训练),通过展示特定参数化保留不同模型大小的最佳超参数来实现,利用 µP 将 HP 从小型模型迁移到大型模型。并在 Transformer 和 ResNet上验证 µTransfer。结果表明,1)该研究优于 BERTlarge (350M 参数),总调优成本相当于一次预训练BERT-large;2)通过从 40M 参数迁移,该研究的性能优于已公开的 6.7B GPT-3 模型,调优成本仅为总预训练成本的 7%。
论文标题:Tensor Programs V: Tuning Large NeuralNetworks via Zero-Shot Hyperparameter Transfer 论文链接:https://www.aminer.cn/pub/6226c93d5aee126c0fd57c5f
北京大学、清华大学:下游任务可以从预训练模型中继承容易受攻击的权重。研究者提出一个名叫 ReMoS 的方法,有选择性地筛选出那些对下游任务有用且不易受攻击的权重,在最多损失 3%精度的前提下,使得微调后的模型受攻击率大大减小:CV(ResNet)任务上受攻击率减小了 63%到 86%,NLP(BERT、RoBERTa)任务上则减小了 40%到 61%。
谷歌:提出了一种在有偏见的数据上使用 GNN 的解决方案Shift-Robust GNN(SR-GNN)。这个方法的目的就是要让问题域发生变化和迁移时,模型依然保持高稳健性,降低性能下降。实验表明,SR-GNN 在准确性上优于其他GNN 基准,将有偏见的训练数据的负面影响减少了 30-40%。
论文标题:Shift-Robust GNNs: Overcoming theLimitations of Localized Graph Training data 论文链接:https://www.aminer.cn/pub/610a271c5244ab9dcba8a3de
港科大、星云Clustar:香港科大智能网络与系统实验室 iSING Lab 和国内隐私计算算力提供商星云 Clustar 合作,提出了一种隐私保护在线机器学习场景下的新框架 Sphinx。Sphinx 结合同态加密、差分隐私和秘密共享多种隐私保护技术,根据训练和推理的具体任务特点提出了定制且兼容的训练和推理混合协议,从而实现快速的训练和推理计算。速度提升达 4-6个数量级。该论文已被 IEEE 安全与隐私研讨会(IEEES&P “Oakland”)收录。论文题目:Sphinx: Enabling Privacy-Preserving Online Learning over the Cloud
2、计算机视觉
谷歌研究院、哈佛大学:提出了 mip-NeRF 的扩展模型,它使用非线性场景参数化、在线蒸馏和新颖的基于失真的正则化器来克服无界场景带来的挑战,该模型被称为「mip-NeRF 360」,因为该研究针对的是相机围绕一个点旋转 360 度的场景,与mip-NeRF 相比,均方误差降低了 54%,并且能够生成逼真的合成视图和详细的深度用于高度复杂、无界的现实世界场景的地图。
论文标题:Mip-NeRF 360: Unbounded Anti-AliasedNeural Radiance Fields 论文链接:https://www.aminer.cn/pub/619dad545244ab9dcb27bcd4
新加坡国立大学、清华大学、阿里巴巴:对比学习已经在视觉领域引起了极大的关注和广泛的研究。研究者指出了传统使用的 RandomCrop 在对比学习中的缺陷,并进一步为对比学习设计了新的裁剪策略,命名为“对比裁剪(ContrastiveCrop)”,可以确保大部分正样本对语义一致的前提下,加大样本之间的差异性,从而通过最小化对比损失学习到更泛化的特征并且理论上适用于任何孪生网络架构。
论文标题:Crafting Better Contrastive Views forSiamese Representation Learning 论文链接:https://www.aminer.cn/pub/6201df4d5aee126c0f64e34b
Adobe、中佛罗里达大学:开发了在 StyleGAN 生成的图像中,用于保护身份的多重面部属性编辑的学习映射器。该研究使用一个神经网络来执行潜意识到潜意识的转换,找到与属性改变的图像相对应的潜编码,通过在整个生成 pipeline 上端对端训练网络,该系统可以适应现有的生成器架构的潜空间,并能够保护属性(Conservation properties),一旦 latent-to-latent网络训练完,就可以用于任意的图像输入,而不需要微调。论文标题:Latent to Latent – A Learned Mapper for Identity Preserving Editing of Multiple Face Attributes in StyleGAN-generated Images
论文链接:https://www.aminer.cn/pub/621635c791e011b46d7ce6d3
字节跳动AML 团队:基于 PyTorch 框架,以 Megatron 和 DeepSpeed 为基础,该研究团队开发了火山引擎大模型训练框架veGiantModel。现已在 GitHub 上开源,地址如下:https://github.com/volcengine/veGiantModel
复旦大学:复旦大学数据智能与社会计算实验室提出了一种基于多层次语义对齐的多阶段视觉 – 语言预训练模型 MVPTR。MVPTR 通过显式地学习表示不同层级的,来自图片和文本信息的语义,并且在不同的阶段对齐不同层次的语义,在大规模图片 – 文本对语料库上预训练的 MVPTR 模型在下游视觉 – 语言任务上取得了明显的进展,包括图片-文本检索、视觉语言问答、视觉推断、短语指代表示。
论文标题:MVPTR: Multi-Stage Vision-Language PreTraining via Multi-Level Semantic Alignment
中国人民大学:中国人民大学 GeWu 实验室以判别性声源定位为基础实现了构建物体类别认知的目标,并将其应用在其他经典视觉任务中。该研究提出了判别性多声源定位任务,以及两阶段的学习框架。还通过解决判别性声源定位任务构建对不同类别物体视觉表征的认知,并将其迁移到其他经典视觉任务中,如物体检测等。
论文标题:Class-aware Sounding Objects Localizationvia Audiovisual Correspondence
论文链接:https://www.aminer.cn/pub/61c3e8e85244ab9dcba2123c
Meta AI:宣传其自监督模型 SEER(SElf-supERvised)突破至 100亿参数,并取得更优秀、更公平的性能表现。该模型不仅在ImageNet 上取得了高达 85.8% 的准确率(排名第一),与原先只有 10 亿参数量的 SEER (84.2%)相比性能提升了 1.6%。此外,在性别、肤色、年龄等三个公平基准上获得了更出色的识别效果,明显优于监督模型。
论文标题:Vision Models Are More Robust And FairWhen Pretrained On Uncurated Images WithoutSupervision
论文链接:https://www.aminer.cn/pub/620f0e725aee126c0fec4580
苏黎世联邦理工学院:开发了名为 Pix2NeRF 的 AI,可以在没有 3D 数据、多视角或相机参数的情况下学会生成新视角。Pix2NeRF 包含生成网络 G、判别网络 D 和编码器 E 三种类型的网络架构。
康奈尔大学、谷歌大脑:提出了一个新模型 FLASH(Fast Linear Attention with a Single Head ) , 首次不仅在质量上与完全增强的Transformer 相当,而且在现代加速器的上下文大小上真正享有线性可扩展性,并且训练成本只有原来的 1/2。
论文标题:Transformer Quality in Linear Time 论文链接:https://www.aminer.cn/pub/621454565aee126c0f20af7b
清华大学、南开大学:研 究 者 提 出 了 一 种 新 型 大 核 注 意 力 ( large kernel attention,LKA)模块,克服现存问题的同时实现了自注意力中的自适应和长距离相关性,还进一步提出了一种基于 LKA 的新型神经网络,命名为视觉注意力网络(VAN)。在图像分类、目标检测、语义分割、实例分割等广泛的实验中,VAN 的性能优于 SOTA 视觉 transformer 和卷积神经网络。
论文标题:Visual Attention Network
论文链接:https://www.aminer.cn/pub/621454535aee126c0f200ef5
华为诺亚方舟实验室、北京大学、悉尼大学:提 出 了 一 种 受 量 子 力 学 启 发 的 视 觉 MLP 架 构 , 在 ImageNet 分类、COCO 检测、ADE20K 分割等多个任务上取得了 SOTA 性能。论文标题: An Image Patch is a Wave: Quantum Inspired Vision MLP 论文链接:https://arxiv.org/abs/2111.12294
加州大学圣圣地亚哥分校、英伟达:通过对具有对比损失的大规模配对图文数据进行训练,可以让模型不需要任何进一步的注释或微调的情况下,能够零样本迁移学习得到未知图像的语义分割词汇。
论文标题:GroupViT: Semantic Segmentation Emergesfrom Text Supervision
论文链接:https://www.aminer.cn/pub/6215a5fd5aee126c0f33a97f
北大、字节跳动:利用域自适应思想,提出新框架显著增强基于图像级标签的弱监督图像定位性能。
论文标题:Weakly Supervised Object Localization asDomain Adaption
论文链接:https://www.aminer.cn/pub/6221834e5aee126c0f23c358
谷歌、MIT、DeepMind、MILA 和剑桥大学等:基于跨平台开源物理引擎 PyBullet 和 3D 图像渲染软件Blender 打造了一个名叫 Kubric 的数据集生成器,能一键生成各种图像数据包括语义分割、深度图或光流图这种“特殊数据”,还能控制渲染的真实度,达到以假乱真的效果。
华东师范大学:该大学田博博研究员、彭晖教授和段纯刚教授团队实现了基于光生伏特效应的自供电光电传感器的传感内储备池计算。在基于该自供电传感器阵列的传感内储备池计算视觉系统中成功演示了静态人脸图像分类和动态车流方向判别的视觉信息处理任务,分别达到 99.97%和 100%识别率。
论文标题:Ultralow-Power Machine Vision with SelfPowered Sensor Reservoir
论文链接:https://www.aminer.cn/pub/62306f1b5aee126c0fdd0e0a
微软亚研院:利用 BERT 中 MLM(Masked Language Modeling)的思路,把一个图像转换成 token 序列,对图像 token 进行mask,然后预测被 mask 掉的图像 token,实现图像领域的无监督预训练。
论文标题: BEIT: BERT Pre-Training of Image Transformers
论文链接:https://www.aminer.cn/pub/5ede0553e06a4c1b26a841d6
美图影像研究院、北京航空航天大学:提出分布感知式单阶段模型,用于解决极具挑战性的多人3D 人体姿态估计问题。该方法通过一次网络前向推理同时获取 3D 空间中人体位置信息以及相对应的关键点信息,从而简化了预测流程,提高了效率。此外,还有效地学习了人体关键点的真实分布,进而提升了基于回归框架的精度。
论文标题:Distribution-Aware Single-Stage Models forMulti-Person 3D Pose Estimation论文链接:https://arxiv.org/abs/2203.07697
Adobe研究院、阿卜杜拉国王科技大学:提出了一种结合多个预训练的 GAN 进行图像生成的新方法——InsetGAN,共分为两类:1)全身 GAN (Full-Body GAN),基于中等质量的数据进行训练并生成一个人体;2)部分 GAN,其中包含了多个针对脸部、手、脚等特定部位进行训练的 GAN。
论文标题:InsetGAN for Full-Body Image Generation
论文链接:https://www.aminer.cn/pub/623004385aee126c0f9b5550
北大、字节跳动:利用域自适应思想,北大、字节跳动提出新型弱监督物体定位框架。将基于 CAM 的弱监督物体定位过程看作是一个特殊的域自适应任务,使得仅依据图像标签训练的模型可以更为精准的定位目标物体。
论文标题:Weakly Supervised Object Localization as Domain Adaption
论文链接:https://www.aminer.cn/pub/6221834e5aee126c0f23c358
加州大学圣圣地亚哥分校、英伟达:利用视觉 Transformer(ViT)中加入新的视觉分组模块GroupViT(分组视觉 Transformer)的思想,研究者提出将分组机制加入深度网络。只要通过文本监督学习,分组机
制就可以自动生成语义片段,通过对具有对比损失的大规模配对图文数据进行训练,可以让模型不需要任何进一步的注释或微调的情况下,能够零样本迁移学习得到未知图像的语义分割词汇。
论文标题:GroupViT: Semantic Segmentation Emergesfrom Text Supervision
论文链接:https://www.aminer.cn/pub/6215a5fd5aee126c0f33a97f
韩东国际大学:研究者提出了 单样本(one-shot)超高分辨率(UHR)图像合成框架 OUR-GAN,能够从单个训练图像生成具有 4K甚至更高分辨率的非重复图像。
论文标题:OUR-GAN: One-shot Ultra-high-ResolutionGenerative Adversarial Networks
论文链接:https://www.aminer.cn/pub/621d8ece5aee126c0f73b4ac
华南理工:提出了一种即插即用融合模块:双跨视角空间注意力机制(VISTA),以产生融合良好的多视角特征,以提高 3D 目标检测器的性能,使用 VISTA 卷积算子代替了 MLP,能够更好地处理注意力建模的局部线索。将 VISTA 中的回归和分类任务解耦,以利用单独的注意力建模来平衡这两个任务的学习。可用于各种先进的目标分配策略。
论文标题:VISTA: Boosting 3D Object Detection viaDual Cross-VIew SpaTial Attention
论文链接:https://www.aminer.cn/pub/6237ecc25aee126c0f3befa5
字节跳动:开发了最新的 text2image 模型,并且效果比 VQGANCLIP 要真实,尤其是泛化能力还比不少用大量文本-图像数据对训练出来的模型要好很多。
论文标题:CLIP-GEN: Language-Free Training of a Textto-Image Generator with CLIP
论文链接:https://www.aminer.cn/pub/621ee1845aee126c0f26aa9b
谷歌、MetaAI:提出了一种称为“模型汤”(Model Soup)的概念,通过在大型预训练模型下使用不同的超参数配置进行微调,然后再把权重取平均。实验结果证明这种方法能够提升模型的准确率和稳健性。
论文标题:Model soups: averaging weights of multiple fine-tuned models improves accuracy without increasing inference time
论文链接:https://www.aminer.cn/pub/622abdd15aee126c0f56bc65
康奈尔大学、Meta AI:通过 Prompt 来调整基于 Transformer 的视觉模型,结果发现:比起全面微调,Prompt 性能提升显著。无论模型的规模和训练数据怎么变,24 种情况中有 20 种都完全胜出。
论文标题:Visual Prompt Tuning
论文链接:https://www.aminer.cn/pub/623be1965aee126c0f37aafc
英伟达:NVIDIA 在自家 GTC 2022 上发布 Omniverse 平台新功能,让开发者能够更轻松地开展协作、在全新游戏开发流程中部署 AI、为角色制作面部表情的动画。
Unity:3D 制作和运营平台 Unity 震撼首发新一代超现实人类,以4K 分辨率实时渲染,让数字人的眼睛、头发、皮肤等细节看起来与真人无异。
3、自然语言处理
清华大学、达摩研究院,浙江实验室,北京人工智能研究院:提出了首个基于国产超算的百万亿参数超大预训练模型训练系统 BaGuaLu。该系统拥有可以以超过 1 EFLOPS 的混合精度性能训练十万亿参数的模型,并且支持训练高达百万亿规模参数量模型的训练(174 T),并且在并行策略、参数存储、数据精度、负载均衡四个方面进行了创新。
论文标题:BaGuaLu: Targeting Brain Scale PretrainedModels with over 37 Million Cores
论文链接:https://www.aminer.cn/pub/6228239b6750f804ca0b65f9
哈工大、腾讯 AI Lab:开发了一个预训练模型 WordBERT。它包含两个组件:词向量(word embedding)和 Transformer 层,WordBERT 采用多层双向 Transformer 来学习语境表示,通过不同的词汇表规模、初始化配置和不同语言,研究人员一共训练出四个版本的 WordBERT。
论文标题:Pretraining without Wordpieces: LearningOver a Vocabulary of Millions of Words
论文链接:https://www.aminer.cn/pub/621849025aee126c0f5520b2
以色列理工学院:研究者提出了新架构 MTTR (Multimodal Tracking Transformer),将 RVOS 任务建模为序列(sequence)预测问题,相关论文已被 CVPR 2022 接收。首先,输入的文本和视频帧被传递给特征编码器进行特征提取,然后将两者连接成多模态序列(每帧一个)。接着,通过多模态 Transformer 对两者之间的特征关系进行编码,并将实例级(instance-level )特征解码为一组预测序列。最后,将预测序列与基准(ground truth,在有监督学习中通常指代样本集中的标签)序列进行匹配,以供训练过程中的监督或用于在推理过程中生成最终预测。
论文标题:End-to-End Referring Video ObjectSegmentation with Multimodal Transformers
论文链接:https://www.aminer.cn/pub/61a596655244ab9dcbdfe60b
微软亚洲研究院:研究者将 Transformer 扩展至 1000 层的同时还保证其稳定性。开发者残差连接处引入了一个新的归一化函数DeepNorm,将 Post-LN 的良好性能和 Pre-LN 的稳定训练高效结合了起来,最终将 Transformer 扩展到 2500 个注意力和前馈网络子层(即 1000 层)比以前的模型深度高出一个数量级,将 DeepNorm 方法应用到Transformer 的每一个子层中,就得到了一个全新的DeepNet 模型。
论文标题:DeepNet: Scaling Transformers to 1,000Layers
论文链接:https://www.aminer.cn/pub/621ee1895aee126c0f26aeef
DeepMind:发布了新的模型 GopherCite,使用根据人类偏好的强化学习(RLHP, reinforcement learning from humanpreferences)训练了一个可以用于开放式问答的模型。解决了语言模型幻觉的问题,通过利用网络上的证据来支持其所有的事实描述。训练结果显示,该模型在自然问题数据集、ELI5 数据集上的正确率分别可以达到 90%、80%,接近人类水平。
谷歌:为了解决模型在理解表格时总是通过行列顺序的线索作弊的问题,提出了 TableFormer,一种对表格行列顺序扰动严格鲁棒的架构,引入了 13 种可学习的注意力偏置标量。TableFormer 还能够更好地编码表格结构,以及对齐表格和相应的文本描述(例如自动问答中的问题)。
论文标题:TableFormer: Robust TransformerModeling for Table-Text Encoding
论文链接:https://www.aminer.cn/pub/621ee1845aee126c0f26aa0e
卡内基梅隆大学:研究团队对 PolyCoder、开源模型和 Codex 的训练和测试设置进行对比研究。使用 HumanEval 基准研究各种模型大小、训练步骤,以及不同的温度对模型生成代码质量的影响。还创建了一个 12 种语言的测试数据集,用来评估各种模型的性能。
论文标题:A Systematic Evaluation of LargeLanguage Models of Code
论文链接:https://www.aminer.cn/pub/621d8ec95aee126c0f73b0b0
香港大学、华为诺亚方舟实验室:针对现有大规模生成式预训练语言模型的压缩需求,提出了新的量化压缩解决方案,分别在 GPT-2 与 BART 上实现了 14.4 倍与 13.4 倍的压缩率,并将量化的 GPT模型与 BART 模型分别命名为「QuantGPT」与「QuantBART」。
论文标题:Compression of Generative Pre-trainedLanguage Models via Quantization
论文链接:https://www.aminer.cn/pub/62393e7f5aee126c0f125f59
4、智能芯片
清华大学:提出了一种基于金属-绝缘体-半导体结构的二维半导体电致发光器件结构。该研究是通过电场去加速材料中的已有载流子,加速载流子获得足够动能后,会和半导体价带的电子发生碰撞,这种碰撞带来的能量转移,会产生出发光所需要的激子。
论文标题:Injection-free multiwavelengthelectroluminescence devices based on monolayersemiconductors driven by an alternating field
论文链接:https://www.aminer.cn/pub/61fd039a5aee126c0fe8965a
西南交通大学、电子科技大学、中国海洋大学、北京基础医学研究所:中国科学家研发柔性脑机接口,在 10Hz 左右找到 α 波!实现刚性微电路和柔软脑组织的无缝联接。研究团队通过分子设计,制备出一款可导电的多功能水凝胶,借此实现了与脑组织接近的力学性能和生物学性能,刚性电子元件和柔软脑组织之间的机械和生物学不匹配的难题得以解决。
论文标题:Bioadhesive and conductive hydrogelintegrated brain-machine interfaces for conformal and immune-evasive contact with brain tissue
新加坡国立大学:研究报告了一种基于当前高速通信基础设施的生物识别保护技术。该系统包含一个协同摩擦电/光子接口,在接口中,柔性摩擦电器件提供生物识别扫描仪功能,氮化铝光芯片提供生物识别信息-光信息多路复用功能;在用户交互时,接口将生物特征信息加载到光域中,并通过摩擦电和纳米光子学之间的协同效应,以自我可持续的方式复用生物特征信息和数字信息;在云端,可以使用快速傅里叶变换滤波器分离高频数字信息和低频生物特征信息。
论文标题:Biometrics-protected optical communication enabled by deep learning–enhanced triboelectric/photonic synergistic interface
格芯、博通、CiscoSystems、Marvell、英伟达等:合作提出了硅光平台 GF Fotonix。该平台将差异化300mm 光子功能和 300GHz 级别 RF-CMOS 结合在单个硅晶圆上,通过在单个硅芯片上组合光子系统、射频RF 元件、CMOS 逻辑电路,将以前分布在多个芯片上的复杂工艺整合到单个芯片上,实现了光子集成电路(PIC)上的更高集成度,让客户能够集成更多的产品功能,从而简化物料清单 BOM。
英伟达:开发了全新 GPU——H100,采用全新 Hopper 架构,集成了 800 亿个晶体管,比上一代 A100 多了 260 亿个,内核数量达到了前所未有的 16896 个,达到上一代A100 卡的 2.5 倍,浮点计算和张量核心运算能力也随之翻了至少 3 倍,面向 AI 计算,针对 Transformer 搭载了优化引擎,让大模型训练速度直接×6,20 张即可承载全球互联网流量。
苹果:发布搭载 M1 自研芯片的高端台式机,新产品名为 Mac Studio,起售价为 1999 美元,类似于专业版 MacMini,可以与外部显示器相连。跟它匹配的,则是内置一颗 A13 新品的 Studio Display 显示器:苹果 27 寸显示器。
5、智能机器人
华为:华为天才少年稚晖君推出了桌面迷你机器人ElectronBot,通过尝试用 T-Spline 曲面建模,并且机器人双臂可动,机器人的底座则使用铝 CNC 进行加工,使用了 Cortex-M4 内核 MCU,STM32F4,用于驱动屏幕和控制舵机以及 USB 通信。此外,利用机器人机身搭载的摄像头和红外手持传感器,还开发了通过 AI 算法识别手势的程序。
微软:微软旗下 Mixed Reality & AI Lab 研究团队基于头显捕获的头部和手部追踪数据开发了“FLAG:Flowbased Avatar Generation from SparseObservations”解决方案,通过 VR 头显获得的头部和手部追踪数据,可生成佩戴者的全身 3D 化身。它不仅能学习 3D 人体的条件分布,还能从观测数据中学习潜在空间的概率映射,并由此进行关节的不确定性估计,生成合理的姿势。
国网上海浦东供电公司:该公司在新片区开展全自主的双曲臂带电作业机器人作业。该机器人全自主作业成功率可达 98%,配合了多传感器融合的定位系统,实现对导线毫米级识别定位。它采用双臂配合,能像人一样深度学习算法,运用人工智能技术,像人的大脑一样主动规划作业路径,高效完成工作任务。
北京术锐技术有限公司、上海交通大学医学院:国产单孔手术机器人共含 68 个高精度伺服电机,用于术前辅助摆位、术中操作和主从控制,创造性地设计了面向全状态安全监控的双环路独立控制硬件拓扑,全链路主从操作延时小于 50 毫秒,每秒钟可实现 1000 次的亚毫米级手术精准控制。
川崎重工:打造了世界首款四足机器羊 Bex,可以降低机身,将下肢四腿膝部的轮毂接地,以四驱机车的方式前进,在有人模式下,羊骑士可以用 Bex 身上的手柄操纵行进方向与速度;在无人模式下,Bex 可以被遥控、可以与其他川崎生产的无人自动送货机器人联网获取行动信息。
UC 伯克利分校:将以前开发的机器人 BADGR 演变成 ViKiNG,并将学习和规划集成起来,利用诸如示意路线图、卫星地图和 GPS 坐标等辅助信息作为规划启发式,利用基于图像的学习控制器和目标导向启发式(goaldirected heuristic),在以前没见过的环境中导航到最远 3 公里以外的目标。
论文标题:ViKiNG: Vision-Based Kilometer-ScaleNavigation with Geographic Hints
论文链接:https://www.aminer.cn/pub/6216f7625aee126c0fc60302
中国人民大学 、 GeWu实验室:提出听音识物 AI 框架。AI 先要在单一声源场景中学习物体的视觉-音频表征;然后再将这一框架迁移到多声源场景下,通过训练来辨别更多的声源。研究人员让这个框架先能从视觉方面定位出画面中存在的不同物体,然后再根据声音信息过滤掉不发声物体。这种方法还能迁移到物体检测任务中去。
麻省理工学院(MIT):开发了一种全新的“声感织物”(预制件的分层材料块,由压电层和响应声波振动的增强材料成分制成)。这种织物材料,不仅能够“听到”声音,还能“发出”声音。
论文标题:Single fibre enables acoustic fabrics viananometre-scale vibrations
论文链接:https://www.aminer.cn/pub/6234658c5aee126c0feefef5
7、知识图谱
魁北克人工智能研究院、加拿大蒙特利尔学习算法研究所:研究者在 AAAI-2022 会议论文中全面介绍知识图谱推理的不同方法,包括传统的基于符号逻辑规则的方法、基于神经的方法、神经符号方法、逻辑规则归纳方法和不同的应用。
论文标题:Reasoning on Knowledge Graphs: Symbolicor Neural?
地址:https://aaai2022kgreasoning.github.io/
北京大学数据管理实验室:被 TKDE 2022 接收的这篇论文对知识图谱质量控制问题展开了综述,不仅包括质量控制的基本概念如问题、维度和指标,也涵盖了质量控制从评估、问题发现到质量提升的全流程,对不同工作中提出的方法,按照多个维度进行分类,最后对现有工作进行讨论和总结,并提出了若干有潜力的未来发展方向。
论文标题:Knowledge Graph Quality Management: a Comprehensive Survey
8、信息检索与推荐
谷歌研究院:引入了可微搜索索引(Differentiable Search Index,DSI)。这是一种学习文本到文本新范式,DSI 模型将字符串查询直接映射到相关文档。此外,还研究了如何表示文档及其标识符的变化、训练过程的变化以及模型和语料库大小之间的相互作用。
论文标题:Transformer Memory as a Differentiable Search Index
论文链接:https://www.aminer.cn/pub/620c6b645aee126c0fe28e8d
上海交通大学:卢策吾团队提出了一种知识驱动的人类行为知识引擎HAKE(Human Activity Knowledge Engine)。它将像素映射到由原子活动基元跨越的中间空间;用一个推理引擎将检测到的基元编程为具有明确逻辑规则的语义,并在推理过程中更新规则。
论文标题:HAKE: A Knowledge Engine Foundation forHuman Activity Understanding
论文链接:https://www.aminer.cn/pub/620b19c85aee126c0f7e6da3
9、可视化
CMU 、NUS、复旦、耶鲁大学:联合发布了面向文本数据的统一数据分析、处理、诊断和可视化平台 DataLab。具有覆盖广、可理解性、统一性、可交互性、启发性几个特性。
论文标题:DataLab: A Platform for Data Analysis andIntervention 论文链接:https://www.aminer.cn/pub/621c3d245aee126c0fe7e43e
马里兰大学、莱斯大学、纽约大学:研究者对双下降(Double Descent)现象进行了可视化,从 CIFAR-10 训练集中选择了三幅随机图像,然后使用三次不同的随机初始化配置在 7 种不同架构上训练,绘制出各自的决策区域,并设计了一种更直观的度量方法来衡量各架构的可复现性得分,发现更宽的 CNN 模型似乎在其决策区域具有更高的可复现性。此外,优化器的选择也会带来影响。
论文标题:Can Neural Nets Learn the Same Model Twice? Investigating Reproducibility and Double Descent from the Decision Boundary Perspective
论文链接:https://www.aminer.cn/pub/623155bb5aee126c0f2bac44
陈·扎克伯格生物中心、莫纳什大学:开发了一个免费、开源并且可扩展的图像查看器 napari,适用于任意复杂(“n 维”)数据,与 Python 生态系统紧密结合,napari 有类似于 Adobe Photoshop 的图层,允许用户叠加点、矢量、轨迹、表面、多边形、注释或其他图像。
论文标题:Python power-up: new image tool visualizes complex data
论文链接:https://www.aminer.cn/pub/61d576f65244ab9dcb3be8ca
10、计算机系统
美国 AI 芯片公司Luminous Computing:宣布已在 A 轮融资中筹集了 1.05 亿美元,用于建造世界上最强大的 AI 超级计算机,并将使用专有的硅光子学技术来消除各种规模的数据移动瓶颈。
美国国家标准与技术研究院:美国国家标准与技术研究院(NIST)的研究人员开发出新的可以在细胞内持续存在的长寿生物计算机。选择使用RNA 来构建生物计算机。结果表明,RNA 电路与其基于 DNA 的电路一样可靠和通用。更重要的是,活细胞能够连续创建这些 RNA 电路元件。
摩尔线程:张建中 2020 年 9 月离开英伟达,并于次月创办的摩尔线程发布国产第一代全功能 GPU 芯片苏堤,以及下一代多平台 GPU 物理仿真系统 AlphaCore。该芯片耗时仅 18个月、量产上市。采用了统一系统架构 MUSA(MT Unified System Architecture)。
11、AI 应用
清华大学、华深智药:清华大学和华深智药生物科技有限公司结合深度学习模型,完成了从抗体 AI 优化设计、抗体合成、功能评估和再优化的闭环程序,基于大量抗体-抗原复合物结构及结合亲和力数据,开发了一种基于注意力的几何神经网络架构,该模型可有效地提取残基间相互作用特征并预测由于抗体单个或多个氨基酸变化所引起的结合亲和力变化。
论文标题: Deep learning guided optimization ofhuman antibody against SARS-CoV-2 variants with broad neutralization
德国 ALS Voice gGmbH:德国 ALS Voice gGmbH 展示了一种使用计算机从脑信号解码字母的方法,可以使完全闭锁患者借助脑机接口(BCI)进行语言交流。目前已经可以和一名 34 岁、完全闭锁状态的男性 ALS 患者(已无法控制随意肌),以每分钟一个词的速度形成单词和词组进行交流。
论文标题:Spelling interface using intracortical signals in a completely locked-in patient enabled via auditory neurofeedback training
中国科学院:中国科学院微生物研究所结合 LSTM、Attention 和BERT 等多种自然语言处理神经网络模型,建立了一个用于从人类肠道微生物组数据中识别候选腺苷-磷酸(AMP)的统一管道,利用现已公开的大量宏基因组数据,进行多肽的挖掘及逻辑推导,研究合成多肽的机理、安全性与动物实验等,并得出对真核细胞没有明显毒性的肽能够在动物体内降低感染菌的载量,并有效治疗肺炎克雷伯菌所导致的感染。
论文标题: Identification of antimicrobial peptides from the human gut microbiome using deep learning
瑞士 Wyss生物和神经工程中心、德国蒂宾根大学:瑞士 Wyss 生物和神经工程中心与德国蒂宾根大学科研团队共同合作,通过侵入式 BCI 系统“植入式电极 神经反馈”的方式获取患者的意图,将 3.2mm2 大小的两个微电极阵列在该患者的大脑皮层表面植入,每个电极阵列有 64 个针状电极,用来记录神经信号。一位渐冻症患者通过 BCI 系统,实现了其大脑信号的读取,并通过机器上字母的选择组合完成了句子的完整表达。
3 月 22 日,相关论文以《在通过听觉神经反馈训练启用的完全锁定患者中使用皮质内信号的拼写界面》(Spelling interface using intracortical signals in a completely locked-in patient enabled via auditory neurofeedback training)为题发表在 Nature Communications 上。
Google Research:Google Research 提出了一个机器学习模型 ProtENN,能够可靠地预测蛋白质的功能,并且为 Pfam 新增了大约680 万条蛋白质功能注释,大约相当于过去十年进展的总和。
论文标题: Using Deep Learning to Annotate theProtein Universe
论文链接:https://www.aminer.cn/pub/5ce3af25ced107d4c65f15d4
清华大学、伊利诺伊大学厄巴纳-香槟分校、麻省理工学院:清华大学、伊利诺伊大学厄巴纳-香槟分校和麻省理工学院利用 DeepMind 开发的第二代深度学习神经网络AlphaFold 2 增强新冠抗体,可以使抗体宽度以及 sarscov-2 变体 (包括 Delta) 的效力提高 10 到 600 倍」,甚至发现了该方法可以对抗奥密克戎(Omicron)变体迹象的希冀。
论文标题: Deep learning guided optimization of human antibody against SARS-CoV-2 variants with broad neutralization
论文链接:https://www.aminer.cn/pub/6221ee375aee126c0f7bb180
厦门大学、新加坡国立大学:张鹏和陈宇综等学者的团队正在研究如何借助计算机算法从蛋白质中创作古典音乐。一条蛋白质链可以表示为一个由字母组成的字符串,像一个以字母表示的音符串。因此,一种合适的“蛋白质到音乐”的算法,就可以将一串氨基酸的结构和物理化学特征映射到一段音符的音乐特征上。
论文标题:Protein music of enhanced musicality bymusic style guided exploration of diverse amino acid properties
论文链接:https://www.aminer.cn/pub/616566875244ab9dcb892cd4
潞晨科技、上海交大:潞晨科技和上海交大提出了一种蛋白质结构预测模型的高效实现 FastFold , FastFold 包 括 一 系 列 基 于 对AlphaFold 性能全面分析的 GPU 优化,同时,通过动态轴并行和对偶异步算子,FastFold 提高了模型并行扩展的效率,超越了现有的模型并行方法。
论文标题:FastFold: Reducing AlphaFold Training Time from 11 Days to 67 Hours
论文链接:https://www.aminer.cn/pub/622032395aee126c0fe2f5d5
谷歌 AI:谷歌 AI 发布了用于蛋白质解析的机器学习模型ProtENN,可以帮助在 Pfam 的蛋白质功能注释集中添加大约 680 万个条目,大约相当于过去十年的新增条目总和,将 Pfam 的覆盖范围扩大了 9.5%以上。
论文标题: Using Deep Learning to Annotate theProtein Universe
论文链接:https://www.aminer.cn/pub/5ce3af25ced107d4c65f15d4
麻省理工学院、哈佛大学:麻省理工学院、哈佛大学博德研究所开发了一种新框架来研究调控 DNA 的适应度地形,该研究利用在数亿次实验测量结果上进行训练的神经网络模型,预测酵母菌 DNA中非编码序列的变化及其对基因表达的影响。
论文标题:The evolution, evolvability and engineering of gene regulatory DNA
论文链接:https://www.aminer.cn/pub/622b2bd75aee126c0fb97555
美国德州农工大学:德州农工大学基于机器学习的培养设计和合成生物学的平台,突破了藻类生产中“相互遮荫” 和 “高收获成本” 的限制,实现 43.3 克 / 平方米 / 天的生物质产量,使最低生物质销售价格降至每吨约 281 美元。
论文标题:Machine learning-informed and syntheticbiology-enabled semi-continuous algal cultivation tounleash renewable fuel productivity
论文链接:https://www.aminer.cn/pub/61f51ab25aee126c0f14ad6e
哥本哈根大学、米兰大学等:丹麦、瑞士、法国、德国、挪威和捷克共和国的 16 名研究人员,首次开发了一款人工智能,可以把猪在各种场景中发出的声音“翻译”出来,读出猪的真实情绪,通过记录 411头家猪的 7000 多次猪叫,使用训练算法来识别这些声音,可以以 92%的正确率翻译出猪叫声中的情绪。
论文标题:Classification of pig calls produced frombirth to slaughter according to their emotional valence and context of production
论文链接:https://www.aminer.cn/pub/622887315aee126c0feab0e0
DeepMind、哈佛大学、谷歌:DeepMind、哈佛大学和谷歌等联合开发了一种基于Transformer 架构的方法,单独修复受损文本时,准确率能达到 62%,破译古希腊石碑的准确率达到 72%,此外,这一方法在地理归属的任务上也有 71%的准确率,还能将古文字的书写日期精确到 30 年以内。
西安电子大学、悉尼科技大学等:中国和澳大利亚学者开发了一款名为 Nos.e 的电子鼻,里面有一小瓶威士忌样品,威士忌的气味被注入到一个气体传感器室中,气体传感器检测各种气味并将数据发送给计算机进行分析。然后,通过机器学习算法提取和分析最重要的气味特征,以识别威士忌的品牌、地区和风格。
央视:两会期间,“央视频”平台以总台财经评论员王冠为原型,1:1 复刻打造推出总台首个拥有超自然语音、超自然表情的超仿真主播“AI 王冠”,同时推出全新 AI 节目《“冠”察两会》,结合两会热点话题,以科技感和新鲜感,为总台两会报道内容提供更多维度和视角。
科大讯飞:科大讯飞为两会打造了“讯飞听见智慧简报系统”。通过智能语音转写、自然语言处理等多项核心技术,该系统实现了在全程离线环境下将会议发言实时转写成文字,一方面辅助记录人员进行简报材料整理,既保证简报记录原汁原味,又保证内容准确详实,另一方面所有算法均在设备本机离线运行,确保会议信息安全。
卡内基梅隆大学:卡内基梅隆大学开发了一个名为 MolCLR(Molecular Contrastive Learning of Representations with GNN)的自我监督学习框架,通过利用大约 1000 万个未标记的分子数据,显著提高了 ML 模型的性能,继而进行化学研究。
论文标题:Molecular contrastive learning of representations via graph neural networks
论文链接:https://www.aminer.cn/pub/60338c9891e011e54d039c5a
布朗大学、MIT 、南洋理工大学:布朗大学、MIT 和南洋理工大学提出了一种基于 PINN的方法,用于解决连续体固体力学中的几何识别问题,该方法将固体力学中重要的已知偏微分方程(PDE)与 NN相结合,构成了一个统一的计算框架,包括正向求解器和逆向算法,通过使用神经网络的工作流程,该方法可以通过深度学习过程自动更新几何估计。
论文标题:Analyses of internal structures and defects in materials using physics-informed neural networks
论文链接:https://www.aminer.cn/pub/620f7b895aee126c0f30d328
斯坦福大学、天津大学:斯坦福大学、天津大学设计了一种极富弹性的可穿戴显示器——可拉伸全聚合物发光二极管(APLED),APLED具有很好的明亮度和耐用性,这一设计或标志着高性能可拉伸显示器的重要进展,为电子皮肤和人-电子应用奠定基础。
论文标题:High-brightness all-polymer stretchable LED with charge-trapping dilution
论文链接:https://www.nature.com/articles/s41586-022-04400-1
清华 AIR、计算机系与腾讯 AI Lab:清华 AIR、计算机系与腾讯 AI Lab 共同提出了图力学网络(Graph Mechanics Network, GMN)。借助广义坐标,GMN 能有效刻画几何约束;借助等变神经网络,GMN 能满足物理对称性。在多刚体仿真系统Constrained N-body、人体骨架预测 CMU Motion Capture、分子动力学模拟 MD-17 等任务上都验证了GMN 的有效性。
论文标题:Equivariant Graph Mechanics Networks with Constraints
论文链接:https://www.aminer.cn/pub/623004305aee126c0f9b358b
RIKEN 、东京大学:RIKEN 高级智能项目研究中心和东京大学使用从头分子生成器(DNMG)与量子化学计算(QC)相结合来开发荧光分子,使用大规模并行计算(1024 核,5 天),DNMG产生了 3643 个候选分子。光致发光光谱测量表明,DNMG 可以以 75% 的准确度(n = 6/8)成功设计荧光分子,并产生一种未报告的分子,该分子发出肉眼可检测到的荧光。
论文标题:De novo creation of a naked eye–detectable fluorescent molecule based on quantum chemical computation and machine learning
论文链接:https://www.aminer.cn/pub/622b2bd35aee126c0fb94f0e
萨塞克斯大学、伦敦大学学院:萨塞克斯大学、伦敦大学学院的研究着提出了一种采用机器学习方法,通过观察自动发现实际物理系统的控制方程和隐藏属性。该研究分为两个阶段:第一阶段的学习模拟器基于图网络 (GN),图网络是一种深度神经网络,可以通过训练来逼近图上的复杂函数;第二阶段,该研究分离边函数(edge function),并应用符号回归拟合边函数的解析公式,其最好的拟合是对牛顿万有引力定律的拟
合。
论文标题:Rediscovering orbital mechanics with machine learning
论文链接:https://www.aminer.cn/pub/62008da15aee126c0fbd19ea
巴西 ABC 联邦大学:巴西 ABC 联邦大学提出了一种数据驱动策略来探索二维材料中的磁性。使用创建的二维磁性材料数据库训练 ML算法,从而获得能够将材料分类为非磁性、FM 或 AFM的描述符。该策略分为两个主要步骤,即(i)开发一个随机森林模型,根据晶体结构和原子组成趋势将磁性与非磁性化合物分开,以及(ii)基于确定的独立性通过筛选和稀疏算子(SISSO)方法寻找一个数学模型(即原子特征的函数),该模型为 AFM 和 FM 二维材料提供具有定义区域的材料图。
论文标题:Machine Learning Study of the Magnetic Ordering in 2D Materials
论文链接:https://www.aminer.cn/pub/61f8a4c35aee126c0fee028e
苏黎世联邦理工学院:苏黎世联邦理工学院提出可使用自学习的人工神经网络,解决动力系统的控制问题。利用数值和分析方法的结合,AI Pontryagin 可通过自动学习,找出工程上可行的控制系统的方式。该方法可应用于智能电网的调控、供应链优化以及金融系统的稳定等众多场景。
论文标题: AI Pontryagin or how artificial neural networks learn to control dynamical systems
论文链接:https://www.aminer.cn/pub/604b3bad91e0110eed64c382
AI 自动驾驶:清华大学、麻省理工学院提出了一种基于自监督学习的方法,让自动驾驶模型从已有的轨迹预测数据集中学会正确判断冲突中的礼让关系。该研究将预测的关系在充满复杂交互的 Waymo Interactive Motion Prediction 数据集上进行了测试,并提出了 M2I 框架来使用预测出的关系进行场景级别的交互轨迹预测。
论文标题:M2I: From Factored Marginal Trajectory Prediction to Interactive Prediction
论文链接:https://www.aminer.cn/pub/621849025aee126c0f551ec8
麻省理工学院的 Derq 分支机构,开发了一个人工智能应用程序,可以融合来自多个传感器的数据,包括安装在车辆和道路两侧的摄像头,以监测并最终协助管理道路,提高安全性。
AI 气候能源:康奈尔大学开发了一个基于机器学习的多时间尺度的电力系统脱碳过渡优化模型,旨在帮助政府规划电力部门向碳中和过渡的路径,以及考量气候或能源目标的可行性。
论文标题: Toward Carbon-Neutral Electric Power Systems in the New York State: a Novel Multi-Scale Bottom-Up Optimization Framework Coupled with Machine Learning for Capacity Planning at HourlyResolution
英伟达、劳伦斯伯克利国家实验室、密歇根大学安娜堡分校、莱斯大学等机构开发了一种基于傅里叶的神经网络预测模型 FourCastNet,它能以 0.25° 的分辨率生成关键天气变量的全球数据驱动预测,相当于赤道附近大约 30×30 km 的空间分辨率和 720×1440 像素的全球网格大小。这使得首次能够与欧洲中期天气预报中心(ECMWF)的高分辨率综合预测系统(IFS)模型进行直接比较。
论文标题:FourCastNet: A Global Data-driven Highresolution Weather Model using Adaptive Fourier Neural Operators
论文链接:https://www.aminer.cn/pub/6216f7625aee126c0fc60248
智东西认为,三月的AI领域重大新闻数量有所下降,但质量上一点也没缩水。最重磅的,当属NVIDIA Omniverse全新功能,用AI技术提升游戏画面,让人物表情变得栩栩如生。另外,中国相关的AI领域的表现也十分亮眼,浙大博士入选苹果奖学金,十一大AI细分领域中都有中国相关高校、公司的身影。