简单点说就是单个线程/进程可监听多个文件描述符,通过减少运行的进程,有效的减少上下文切换的消耗。
为什么需要IO多路复用技术为实现高性能服务器。上篇文章我们介绍了网络IO模型,阻塞IO的recvfrom接口会阻塞直到有数据copy完成,如果是单线程的话会导致主线程被阻塞,即整个程序永远锁死。当然可以通过多线程解决,即一个连接分配一个线程来处理,但是如果是百万连接情况,总不能创建百万个线程,毕竟操作系统资源有限。因此就有了IO多路复用技术来解决单线程监听多个网络连接的情况。
IO多路复用技术有哪些?主要IO多路复用技术有:select,poll和epoll,注意这些系统调用本身都是阻塞的,其所监听的socket设置为non-blocking。select同poll原理差不多,因此,接下来会重点介绍select和epoll.
selectselect数据结构以及工作原理
//原型
intselect(intnumfds,fd_set*readfds,fd_set*writefds,fd_set*exceptfds,structtimeval*timeout);
/*
*参数含义如下
*numfds:需要监听的最大文件描述符 1
*readfds:需监听的读文件描述符(fd)集合
*writefds:需监听的写文件描述符(fd)集合
*exceptfds:需监听的异常文件描述符(fd)集合
*timeout:
*1.NULL则永远等待,直到信号或文件描述符准备好;
*2.0:从不等待,测试所有执行的fd立即返回
*3.>0:等待timeout时间,还没有fd准备好,立即返回
*
*return:返回三个fd集合(readfds,writefds,exceptfds)中fd总数;
*/
//fd处理函数
FD_ZERO(fd_set*set);//清除fd_set
FD_SET(intfd,fd_set*set);//将fd加入set,被监听
FD_CLR(intfd,fd_set*set);//将fd从set中移除
FD_ISSET(intfd,fd_set*set);//测试set中的fd是否准备好,测试某个位是否被置为。
select工作流程如下:
- 假设fd_set为一个1字节(== 8 bit),每一个bit对应一个文件描述符,通过FD_SET将readfds中3,4,5,7 文件描述符设为1,表示对这四个文件描述符的读事件感兴趣,如下图:select_readfds
- 调用select,将readfds copy到内核空间,并轮询感兴趣的fd,因为需要监听的最大文件描述符为7,因此select的第一个参数为8,内核只需要关心<8的文件描述符即可,此时文件描述符5,7有读事件到来(没有数据到来则select阻塞),内核将对应位置为1并将结果返回用户空间,这时用户的readfds变成了下图:select_readed
- 用户空间遍历readfds,通过FD_ISSET对应的fd是否置位,如果置位则调用read读取数据。
优点:可以监听多个文件描述符
缺点:
- 最大可监听文件描述符有上限,由fd_set决定(一般为1024)
- 需要将fd_set在用户态和内核态之间进行copy,开销大
- 无法精确知道哪些fd准备就绪,需要遍历fd_set并通过FD_ISSET来检测,事件复杂度为O(n)
//unistd.h系统调用编号
#define__NR_select82
select为系统调用,其系统调用的编号为 82,用户态执行系统调用会触发0x80中断,并将其编号,以及相关参数传入内核空间,内核态根据其系统调用编号在sys_call_table找到对应接口sys_select。
fd_set数据结构与用户态内核态之间的copy
typedefstruct{
unsignedlongfds_bits[__FDSET_LONGS];
}__kernel_fd_set;
typedef__kernel_fd_setfd_set;
/*内核态-->用户态
*__copy_to_user:copyablockofdataintouserspace,withlesschecking.
*@to:Destinationaddress,inuserspace.
*@from:Sourceaddress,inkernelspace.
*@n:Numberofbytestocopy
*/
staticinlineunsignedlong
__copy_to_user(void__user*to,constvoid*from,unsignedlongn){
return__copy_to_user_ll(to,from,n);
}
/*用户态-->内核态
*__copy_from_user:copyablockofdatafromuserspace,withlesschecking.
*@to:Destinationaddress,inkernlespace.
*@from:Sourceaddress,indataspace.
*@n:Numberofbytestocopy
*/
staticinlineunsignedlong
__copy_from_user(void*to,constvoid__user*from,unsignedlongn){
return__copy_from_user_ll(to,from,n);
}
//poll.h
typedefstruct{
unsignedlong*in,*out,*ex;//需要关注的fds
unsignedlong*res_in,*res_out,*res_ex;//保存结果
}fd_set_bits;
//select.c
asmlinkagelong
sys_select(intn,fd_set__user*inp,fd_set__user*outp,fd_set__user*exp,structtimeval__user*tvp){
fd_set_bitsfds;
//get_fd_set会调用__copy_from_user接口将用户态关心的fds(inp,outp,exp)copy到内核空间fds中
get_fd_set(n,inp,fds.in);
get_fd_set(n,outp,fds.out);
get_fd_set(n,exp,fds.ex);
//清空结果
zero_fd_set(n,fds.res_in);
zero_fd_set(n,fds.res_out);
zero_fd_set(n,fds.res_ex);
//真正select,会pollfds中需要关注的fd,如果有事件到达则保存至结果字段
ret=do_select(n,&fds,&timeout);
//set_fd_set会调用__copy_to_user接口将事件结果从内核空间fdscopy到用户空间
set_fd_set(n,inp,fds.res_in);
set_fd_set(n,outp,fds.res_out);
set_fd_set(n,exp,fds.res_ex);
}
intmain(){
//创建服务器绑定端口进行监听
intsockfd=socket(AF_INET,SOCK_STREAM,0);
bind(sockfd,...);
listen(sockfd,...);
fd_setrfds,rset;
FD_ZERO(&rfds);//清空rfds,rfds保存需要监听的fd
FD_SET(sockfd,&rfds);//将sockfd加入rfds集合中
intmax_fd=sockfd;//最新生成的sockfd为最大fd
while(1){
rset=rfds;//将需要监听的rfdscopy到rset中
//nready表示有事件触发的socketfd数量
intnready=select(max_fd 1,&rset,NULL,NULL,NULL);
if(FD_ISSET(sockfd,&rset)){//检测sockfd是否有事件到来,即是否有客户端连接
structsockaddr_inclient_addr;
memset(&client_addr,0,sizeof(structsockaddr_in));
socklen_tclient_len=sizeof(client_addr);
//accept客户端,连接成功后分配clientfd
intclientfd=accept(sockfd,(structsockaddr*)&client_addr,&client_len);
FD_SET(clientfd,&rfds);//将clientfd加入rfds集合中
//处理完一个fd,则更新nready值,直到为0则表示全部处理完,然后退出
if(--nready==0)continue;
}
//遍历所有的文件描述符,因此select时间复杂度为O(n)
for(i=sockfd 1;i<=max_fd;i ){
if(FD_ISSET(i,&rset)){
charbuffer[BUFFER_LENGTH]={0};
intret=recv(i,buffer,BUFFER_LENGTH,0);
...//进行出数据处理
//更新nready
if(--nready==0)break;
}
}
}
return0;
}
poll不做详细介绍,因为其跟select实现方式差不多,效率也差不多;区别在于
- 没有最大可监听fd限制,因为其底层通过链表实现;
- poll没有将可读可写错误三种状态分开,且通过revents来设置某些事件是否触发;
structpollfd{
intfd;
shortevents;//要求查询的事件掩码(关注的事件)
shortrevents;//返回的事件掩码可重用
};
intpoll(structpollfd*ufds,unsignedintnfds,inttimeout);
/*
*ufds:要监控的fd集合
*nfds:fd数量
*timeout:<0一直等待;==0立即返回;
*/
structpollfdfds[POLL_SIZE]={0};
fds[0].fd=sockfd;//设置监控fd
fds[0].events=POLLIN;//设置监控事件
intmax_fd=0,i=0;
for(i=1;i<POLL_SIZE;i ){
fds[i].fd=-1;
}
while(1){
//同select,返回准备就绪的fd数量
//不同于select的是,poll没有将可读可写错误三种状态分开,且通过revents来设置某些事件是否触发
intnready=poll(fds,max_fd 1,5);
if(nready<=0)continue;
if((fds[0].revents&POLLIN)==POLLIN){
intclientfd=accept(sockfd,...);
fds[clientfd].fd=clientfd;
fds[clientfd].events=POLLIN;
if(--nready==0)continue;
}
for(i=sockfd 1;i<=max_fd;i ){
if(fds[i].revents&(POLLIN|POLLERR)){
charbuffer[BUFFER_LENGTH]={0};
intret=recv(i,buffer,BUFFER_LENGTH,0);
if(--nready==0)break;
}
}
}
比select,poll更加高效的IO多路复用技术。
首先介绍内核中实现epoll的两个数据结构:
- 红黑树:也即interest list,用于存放所有监听的fd;(增删改时间复杂度都为logn)
- 双向链表:也即ready list,存放所有有IO事件到来的fd(其共用红黑树的节点)
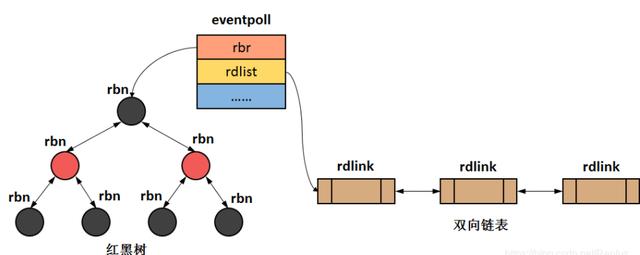
这两个数据结构都在eventpool中,如下
structeventpool{
//红黑树根节点,存储所有通过epoll_ctl添加进来的fd
structrb_rootrbr;
//双链表存放有事件触发的fd,通过epoll_wait返回给用户
structlist_headrdllist;
...
};
接下来会介绍epoll的三个重要接口:epoll_create, epoll_ctl, epoll_wait,并直接从linux内核实现中窥视其具体实现,进而彻底捋清楚epoll的工作原理和流程。
epoll_create首先思考一个问题,eventpool数据结构是何时被创建的呢?请带着问题看代码:
//unistd.h系统调用编号
#define__NR_epoll_create254
//eventpoll.c
//epoll_create为系统调用,最终会到这里
SYSCALL_DEFINE1(epoll_create,int,size)
{
//这就是为啥大家经常听到的,epoll_create的参数只有>0和<=0的区别
if(size<=0)
return-EINVAL;
returnsys_epoll_create1(0);//接着调用epoll_create1
}
/*
*Openaneventpollfiledescriptor.
*/
SYSCALL_DEFINE1(epoll_create1,int,flags)
{
interror,fd;
structeventpoll*ep=NULL;
structfile*file;
error=ep_alloc(&ep);
...
returnfd;
}
//创建eventpoll结构体,并初始化rdllist和rbr等数据结构
staticintep_alloc(structeventpoll**pep)
{
structeventpoll*ep;
ep=kzalloc(sizeof(*ep),GFP_KERNEL)
init_waitqueue_head(&ep->wq);
init_waitqueue_head(&ep->poll_wait);
INIT_LIST_HEAD(&ep->rdllist);
ep->rbr=RB_ROOT;
*pep=ep;
...
}
因此epoll_create的工作就是创建eventpoll结构体,并对其内部数据结构进行初始化,到这里我们可以理解为epoll的初始化工作结束,接下来介绍第二个重要接口epoll_ctl
epoll_ctl这里同样给大家抛出一个问题,fd是如何被添加到eventpoll中的红黑树里面的呢?以及如何更新和删除?依旧带着问题看代码,看完代码,我们再来下结论
//unistd.h系统调用编号同样epoll_ctl也是一个系统调用
#define__NR_ctl255
//eventpool.h
//以下是epoll_ctl的三个有效操作
/*Validopcodestoissuetosys_epoll_ctl()*/
#defineEPOLL_CTL_ADD1
#defineEPOLL_CTL_DEL2
#defineEPOLL_CTL_MOD3
//epoll_event数据结构
structepoll_event{
__u32events;
__u64data;
}EPOLL_PACKED
//每一个被添加到epoll中的fd,都会对应一个epitem
structepitem{
structrb_noderbn;//红黑树节点
structlist_headrdllink;//双向链表节点
structepoll_filefdffd;//事件句柄信息
structeventpoll*ep;//所属的eventpoll
structepoll_eventevent;//期待发生的事件类型
};
/*这是官方注释,也解答了epoll_ctl的主要功能
*Thefollowingfunctionimplementsthecontrollerinterfacefor
*theeventpollfilethatenablestheinsertion/removal/changeof
*filedescriptorsinsidetheinterestset.
*/
/*
*可以看出epoll_ctl需要传入4个参数
*@epfdint通过epoll_create创建的fd
*@opint操作类型
*@fdint需要操作的sockfd
*@eventstructepoll_event用于用户态内核态之间传递数据
*/
SYSCALL_DEFINE4(epoll_ctl,int,epfd,int,op,int,fd,
structepoll_event__user*,event)
{
//如果op不是EPOLL_CTL_DEL删除操作,就把event从用户空间copy到内核空间,保存在epds中
if(ep_op_has_event(op)&&
copy_from_user(&epds,event,sizeof(structepoll_event)))
gotoerror_return;
//需要进行一些加锁操作
switch(op){//根据不同的op进行相应的操作
caseEPOLL_CTL_ADD:
ep_insert(ep,&epds,tfile,fd);//插入,会构造一个epitem结构,并加入红黑树中
break;
caseEPOLL_CTL_DEL:
ep_remove(ep,epi);//删除
break;
caseEPOLL_CTL_MOD:
ep_modify(ep,epi,&epds);//修改
break;
}
...
}
epoll_ctl包含插入,删除和更新三个操作,其中插入是使用socket fd及其关注的事件构造epitem结构体,并插入到eventpoll中,同时会给内核中断处理程序注册一个回调函数,告诉内核,如果这个句柄的中断到了,就把它放到准备就绪list链表中。删除就是将socket fd对应的节点从eventpoll中删除,更新就是修改socket fd相关的信息,比如更改其所监听的事件等。
所有添加到epoll中的事件都会与设备(网卡)驱动程序建立回调关系,即,每当事件发生时,会调用对应的回调函数(内核中对应为ep_poll_callback),将发生的事件添加到rdlist双链表中
epoll_wait最后一个重要接口是epoll_wait, 既然sockfd以及其所关心的事件等信息已经添加到了eventpoll中,那么当socket对应的事件到来是,是如何通知eventpoll将socket fd对应的节点加入到就绪链表中,并如何通知用户态进行数据读取呢?
//epoll_wait系统调用
SYSCALL_DEFINE4(epoll_wait,int,epfd,structepoll_event__user*,events,
int,maxevents,int,timeout)
{
//调用ep_poll
ep_poll(ep,events,maxevents,timeout);
}
/**官方注释很清晰
*ep_poll-Retrievesreadyevents,anddeliversthemtothecallersupplied
*eventbuffer.获取准备好的事件,并将其copy到调用者提供的eventbuffer中
*
*@ep:Pointertotheeventpollcontext.指向eventpoll
*@events:Pointertotheuserspacebufferwherethereadyeventsshouldbe
*stored.指向用户空间中就绪事件存放的buffer中
*@maxevents:Size(intermsofnumberofevents)ofthecallereventbuffer.
*@timeout:Maximumtimeoutforthereadyeventsfetchoperation,in
*milliseconds.Ifthe@timeoutiszero,thefunctionwillnotblock,
*whileifthe@timeoutislessthanzero,thefunctionwillblock
*untilatleastoneeventhasbeenretrieved(oranerror
*occurred).
*
*Returns:Returnsthenumberofreadyeventswhichhavebeenfetched,oran
*errorcode,incaseoferror.
*/
staticintep_poll(structeventpoll*ep,structepoll_event__user*events,
intmaxevents,longtimeout)
{
ep_send_events(ep,events,maxevents);
}
epoll_wait为阻塞的接口,如果就绪列表中有事件到来,就会将就绪事件copy到用户空间(通过epoll_event结构体),并返回事件的数量。没有数据就sleep,等到timeout时间到了即使没有数据也返回。
总结下用户如何使用epoll的接口,以及对应参数含义
//成功则返回epoll实例的fd.失败返回-1
//epoll_create参数只有>0和<0的区别
intepoll_create(intsize);
//控制fd函数,epfd表示应用程序使用的epollfd;即epoll_create返回的
//op控制参数,有三种:EPOLL_CTL_ADD(添加)EPOLL_CTL_MOD(修改)EPOLL_CTL_DEL(删除)
//fd表示要被操作的fd,而epoll_event则表示与fd绑定的消息结构。
intepoll_ctl(intepfd,intop,intfd,structepoll_event*event);
//例如将fd1添加到epoll实例中
structepoll_eventev;
ev.events=EPOLLIN|EPOLLOUT;
ev.data.ptr=(void*)socket_data;
epoll_ctl(epfd,EPOLL_CTL_MOD,fd1,&ev);
//获取readylist
//timeout==0:
//不论readylist是否为空,epoll_wait都会被立即唤醒;
//timeout>0:
//1.有进程的signal信号到达2.最近一次epoll_wait被调用起,经过timeoutms3.readylist不为空
//timeout==-1:
//1.有进程的signal信号到达2.readylist不为空
//将内核中就绪的事件copy到events中
intepoll_wait(intepfd,structepoll_event*events,intmaxevents,inttimeout);
源码中epoll实现较为复杂,之后会单独用一个篇文章来介绍一个大佬手撸的一个简单epoll实现帮助大家理解。
epoll的LT和ET模式我们假定recvbuff中有数据为1,无数据为0
水平触发LT(Level Trigger):一直触发,recvbuff为1(有数据)则一直触发,直到recvbuff为0(无数据)
边缘触发ET(Edge Trigger): recvbuff从0到1时,就触发一次。每次有新的数据包到达时epoll wait才会唤醒,因此没有处理完的数据会残留在缓冲区;直到下一次客户端有新的数据包到达时,epoll_wait才会再次被唤醒。
epoll实例
intepoll_fd=epoll_create(EPOLL_SIZE);
structepoll_eventev,events[EPOLL_SIZE]={0};
ev.events=EPOLLIN;//默认LT
ev.data.fd=sockfd;
//把sockfd带着ev加入到epoll_fd中(红黑树)
//sockfd为key,ev为value
epoll_ctl(epoll_fd,EPOLL_CTL_ADD,sockfd,&ev);
while(1){
//nready就绪fd数量,就绪fd存储再events中
intnready=epoll_wait(epoll_fd,events,EPOLL_SIZE,-1);
inti=0;
//遍历就绪队列nready;
for(i=0;i<nready;i ){
if(events[i].data.fd==sockfd){//有客户端连接到来
intclientfd=accept(sockfd,(structsockaddr*)&client_addr,&client_len);
ev.events=EPOLLIN|EPOLLET;
ev.data.fd=clientfd;
//将clientfd加入到epoll_fd中
epoll_ctl(epoll_fd,EPOLL_CTL_ADD,clientfd,&ev);
}else{//客户端有数据到来
intclientfd=events[i].data.fd;
charbuffer[BUFFER_LENGTH]={0};
intret=recv(clientfd,buffer,BUFFER_LENGTH,0);
//数据处理
}
}
select:无差别轮询,当IO事件发生,将所有监听的fds传给内核,内核遍历所有fds,并将标记有事件的fd,遍历完将所有fd返回给应用程序,应用程序需要遍历整个数组才能知道哪些fd发生了事件,时间复杂度为O(n),还有fds从用户态copy到内核态的开销。基于数组,监听fd有大小限制。
poll:与select无本质区别,但没有最大连接数限制,因其基于链表存储。
epoll: 采用回调机制,当有事件到来时加入到就绪链表中,内核无序主动遍历所有监听的socket是否有事件到来,并且只需把有事件触发的fd copy到用户空间,无需copy所有fd,用户空间也只需遍历有事件到来的fd进行相关操作,且没有最大并发连接数限制。
Redis中采用单线程epoll,nginx采用多进程epoll
最后附一份poll,select,epoll的测试对比图,可见随着监听的文件描述符不断增大,epoll的效率远远超出一大截了。

epoll_time
,




