本文只讲一下流程,基础向,有兴趣的小伙伴可以试一下,代码自己去全球最大的同性交友网站github上找。这几年OCR技术趋于稳定,换句话说就是进步不大,几年前的框架CTPN至今依旧流行。
OCR(optical character recognition)通俗的来讲就是用电脑来识别图片中的文字,并显示出来。本次介绍的是一种比较传统的方法。对于一张图片,单一网络模型很难准确的识别出其中的每一个文字(有单模型ocr),通常都是用两个神经网络模型组合来完成ocr项目:用目标检测网络模型在复制环境中识别并裁剪出包含文本的文本框-->将文本框送入文字识别网络模型进行识别。
文本框检测现在的神经网络,很多预处理步骤是不需要我们做的(比如二值,降噪等),我们直接丢图片进去就好。
对于比较规范的文字,就是那种文本排版方方正正的(倾角<15°),如身份证,头条截图,比较常用的文本框检测模型就是CTPN,性能稳定。

规则的文本
然而生活中拍摄的照片,比如街景,基本上图片文本框倾角都是在15~30°之间,或者是不规则的文本框,这就涉及到另一个研究领域:倾斜文本检测,目前有PSENet,PixelLink等。得到倾斜的文本框,将其校准便可以的到类似CTPN的方框。

不规则的文本
文本框检测中得到的返回结果是一个坐标,表示的是该文本框在图上的位置。通过定位文本框,即可知道文本的所在。
文本识别一般可以用CRNN(注意不是rcnn,这是两种完全不同的模型),这个框架也有些年头了,但是因为很好用,至今仍在广泛使用(其实还是因为开源)。神经网络兴起之前还有模板匹配等方法,现在一般不常用了。
CRNN一般来讲分成三部分:CNN RNN CTC,CNN卷积网络基于VGG,用于特征提取,RNN是循环神经网络,用于序列预测,CTC为翻译层。
结构如图:
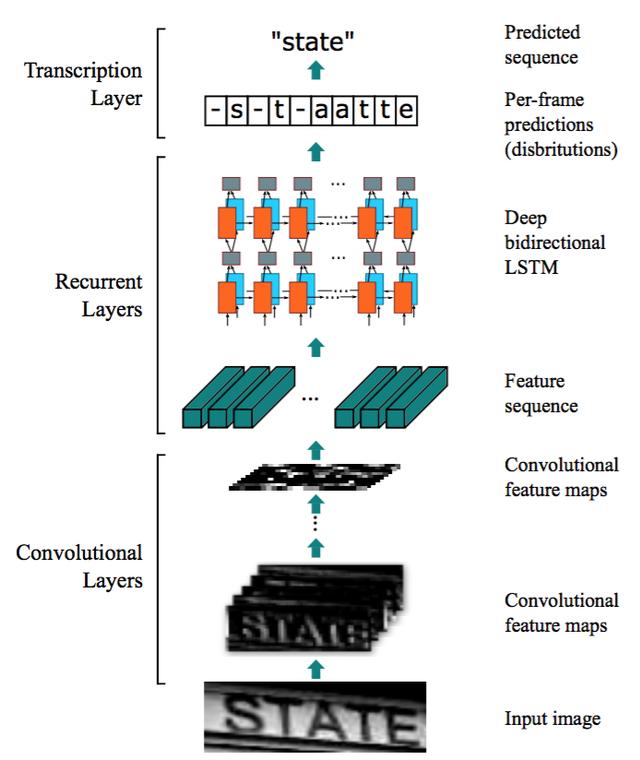
基本使用方法是将文本框检测中检测到的文本框裁剪出来,一张一张的送入crnn,每送入一张,运行一次crnn(文本框多的话比较费时),得到对应的字符,将字符组合,最终的到文字检测结果(为了照顾手机把图片截成两段了)

英文字符1
英文字符2

中文字符1

中文字符2
,




