3.1.6 Hive事务操作
Hive开始支持事务,是在Hive0.14之后。HDFS的文件,只能允许新建,删除,对文件中的内容进行更新,不允许单条修改。Hive的文件存储是基于HDFS文件存在的,所以原则上不会直接对HDFS做文件内容的事务更新,只能是采取另外的手段来完成。即用HDFS文件作为原始数据,用delta文件作为操作日志的记录。当访问Hive数据时,根据HDFS文件和delta文件做合并,查询最新的数据。
综上,Hive支持事务的前提是初始化数据和增量操作,分开存储。这种存储方案导致的最终结果是Hive存储的delta文件日益增多,增加NameNode的管理难度,NameNode是设计来管理大容量小数量文件,每一个HDFS的文件目录以及文件都会增大NameNode的内存消耗。
Hive支持事务所需要的前提配置:(1)配置6个属性。(2)在Hive元数据中增加对事务支持所需的表(这一点不知道有没有改善,理论上太复杂)。(3)重新启动Hive服务。(4)建表需要使用ORC存储。(5)该数据库必须具有ACID[1]特性,否则在事务过程当中无法保证数据的正确性,交易过程及极可能达不到交易方的要求。
打开事务属性支持有如下几个配置:
SET hive.support.concurrency = true;
SET hive.enforce.bucketing = true;
SET hive.exec.dynamic.partition.mode = nonstrict;
SET hive.txn.manager = org.apache.hadoop.hive.ql.lockmgr.DbTxnManager;
SET hive.compactor.initiator.on = true;
SET hive.compactor.worker.threads = 1;
配置好了事务属性之后,可以了解一下关于事务表的操作。首先创建桶表(事务表,优化的列模式文件),在创建好桶表之后,使用desc命令来查看创建的表结构,具体代码以及结果如下所示,
hive> desc formatted tx;
OK
# col_name data_type comment
id int
name string
# Detailed Table Information
Database: default
Owner: laura
CreateTime: Wed Aug 02 18:31:52 PDT 2017
LastAccessTime: UNKNOWN
Retention: 0
Location: hdfs://hadoop0:8020/user/hive/warehouse/tx
Table Type: MANAGED_TABLE
Table Parameters:
COLUMN_STATS_ACCURATE {\"BASIC_STATS\":\"true\"}
numFiles 0
numRows 0
rawDataSize 0
totalSize 0
transactional true
transient_lastDdlTime 1501723912
# Storage Information
SerDe Library: org.apache.Hadoop.hive.ql.io.orc.OrcSerde
InputFormat: org.apache.hadoop.hive.ql.io.orc.OrcInputFormat
OutputFormat: org.apache.hadoop.hive.ql.io.orc.OrcOutputFormat
Compressed: No
Num Buckets: 2
Bucket Columns: [id]
Sort Columns: []
Storage Desc Params:
field.delim \t
line.delim \n
serialization.format \t
Time taken: 0.418 seconds, Fetched: 34 row(s)
将数据插入事务表之前必须打开之前介绍的事务属性的所有配置才可以。然后就可以向表中插入一些数据,
hive> insert into tx(id,name) values(1,'tom');
WARNING: Hive-on-MR is deprecated in Hive 2 and may not be available in the future versions. Consider using a different execution engine (i.e. spark, tez) or using Hive 1.X releases.
Query ID = laura_20170802183559_92c64423-63aa-4a82-abbd-6d24039f1ceb
Total jobs = 1
Launching Job 1 out of 1
number of reduce tasks determined at compile time: 2
In order to change the average load for a reducer (in bytes):
set hive.exec.reducers.bytes.per.reducer=<number>
In order to limit the maximum number of reducers:
set hive.exec.reducers.max=<number>
In order to set a constant number of reducers:
set mapreduce.job.reduces=<number>
Starting Job = job_1501679648039_0003, Tracking URL = http://hadoop0:8888/ proxy/application_1501679648039_0003/
Kill Command = /home/laura/hadoop-2.7.3/bin/hadoop job -kill job_1501679648039_ 0003
Hadoop job information for Stage-1: number of mappers: 1; number of reducers: 2
2017-08-02 18:36:37,024 Stage-1 map = 0%, reduce = 0%
2017-08-02 18:36:59,492 Stage-1 map = 100%, reduce = 0%, Cumulative CPU 4.5 sec
2017-08-02 18:37:15,802 Stage-1 map = 100%, reduce = 50%, Cumulative CPU 8.94 sec
2017-08-02 18:37:23,286 Stage-1 map = 100%, reduce = 100%, Cumulative CPU 13.26 sec
MapReduce Total cumulative CPU time: 13 seconds 260 msec
Ended Job = job_1501679648039_0003
Loading data to table default.tx
MapReduce Jobs Launched:
Stage-Stage-1: Map: 1 Reduce: 2 Cumulative CPU: 13.26 sec HDFS Read: 11762
HDFS Write: 931 SUCCESS
Total MapReduce CPU Time Spent: 13 seconds 260 msec
OK
Time taken: 88.482 seconds
hive> insert into tx(id,name) values(2,'tomlee');
WARNING: Hive-on-MR is deprecated in Hive 2 and may not be available in the future versions. Consider using a different execution engine (i.e. spark, tez) or using Hive 1.X releases.
Query ID = laura_20170802183855_89b897ca-a3d8-4be3-aa7e-50da1ae39ce3
Total jobs = 1
Launching Job 1 out of 1
Number of reduce tasks determined at compile time: 2
In order to change the average load for a reducer (in bytes):
set hive.exec.reducers.bytes.per.reducer=<number>
In order to limit the maximum number of reducers:
set hive.exec.reducers.max=<number>
In order to set a constant number of reducers:
set mapreduce.job.reduces=<number>
Starting Job = job_1501679648039_0004, Tracking URL = http://hadoop0:8888/ proxy/application_1501679648039_0004/
Kill Command = /home/laura/hadoop-2.7.3/bin/hadoop job -kill job_1501679648039_ 0004
Hadoop job information for Stage-1: number of mappers: 1; number of reducers: 2
2017-08-02 18:39:13,830 Stage-1 map = 0%, reduce = 0%
2017-08-02 18:39:24,580 Stage-1 map = 100%, reduce = 0%, Cumulative CPU 2.52 sec
2017-08-02 18:39:38,346 Stage-1 map = 100%, reduce = 50%, Cumulative CPU 6.93 sec
2017-08-02 18:39:46,007 Stage-1 map = 100%, reduce = 100%, Cumulative CPU 11.02 sec
MapReduce Total cumulative CPU time: 11 seconds 20 msec
Ended Job = job_1501679648039_0004
Loading data to table default.tx
MapReduce Jobs Launched:
Stage-Stage-1: Map: 1 Reduce: 2 Cumulative CPU: 11.02 sec HDFS Read: 11667 HDFS Write: 945 SUCCESS
Total MapReduce CPU Time Spent: 11 seconds 20 msec
OK
Time taken: 52.174 seconds
hive> insert into tx(id,name) values(3,'tomaslee');
WARNING: Hive-on-MR is deprecated in Hive 2 and may not be available in the future versions. Consider using a different execution engine (i.e. spark, tez) or using Hive 1.X releases.
Query ID = laura_20170802184117_d8d75ebf-37b6-4623-b464-e6348eddae36
Total jobs = 1
Launching Job 1 out of 1
Number of reduce tasks determined at compile time: 2
In order to change the average load for a reducer (in bytes):
set hive.exec.reducers.bytes.per.reducer=<number>
In order to limit the maximum number of reducers:
set hive.exec.reducers.max=<number>
In order to set a constant number of reducers:
set mapreduce.job.reduces=<number>
Starting Job = job_1501679648039_0005, Tracking URL = http://hadoop0:8888/ proxy/application_1501679648039_0005/
Kill Command = /home/laura/hadoop-2.7.3/bin/hadoop job -kill job_1501679648039_ 0005
Hadoop job information for Stage-1: number of mappers: 1; number of reducers: 2
2017-08-02 18:41:33,517 Stage-1 map = 0%, reduce = 0%
2017-08-02 18:41:55,639 Stage-1 map = 100%, reduce = 0%, Cumulative CPU 8.0 sec
2017-08-02 18:42:08,404 Stage-1 map = 100%, reduce = 50%, Cumulative CPU 11.91 sec
2017-08-02 18:42:10,490 Stage-1 map = 100%, reduce = 100%, Cumulative CPU 15.66 sec
MapReduce Total cumulative CPU time: 15 seconds 660 msec
Ended Job = job_1501679648039_0005
Loading data to table default.tx
MapReduce Jobs Launched:
Stage-Stage-1: Map: 1 Reduce: 2 Cumulative CPU: 15.66 sec HDFS Read: 11677 HDFS Write: 961 SUCCESS
Total MapReduce CPU Time Spent: 15 seconds 660 msec
OK
Time taken: 54.029 seconds
3.1.7 Hive优化
在Hive中,有很多因素会影响到Hive本身的性能,而在Hive性能优化时,把HiveQL当做MapReduce程序来读,即从M/R的运行角度来考虑优化性能,从更底层思考如何优化运算性能,而不仅仅局限于逻辑代码的替换层面。
RAC(Real Application Cluster)真正应用集群就像一辆机动灵活的小货车,响应快;Hadoop就像吞吐量巨大的轮船,启动开销大,如果每次只做小数量的输入输出,利用率将会很低。所以用好Hadoop的首要任务是增大每次任务所搭建的数据量。
Hadoop的核心能力是partition和sort,因而这也是优化的根本。
观察Hadoop处理数据的过程,有几个显著的特征:
(1) 数据的大规模并不是负载重点,造成运行压力过大是因为运行数据的倾斜。
(2) jobs数比较多的作业运行效率相对比较低,比如即使有几百行的表,如果多次关联对此汇总,产生几十个jobs,将会需要30分钟以上的时间且大部分时间将用于作业分配,初始化和数据输出。M/R作业初始化的时间是比较耗时间资源的一个部分。
(3) 在使用SUM,COUNT,MAX,MIN等UDAF函数时,不怕数据倾斜问题,Hadoop在Map端的汇总合并优化过,使数据倾斜不成问题。
(4) COUNT(DISTINCT)在数据量大的情况下,效率较低,如果多COUNT(DISTINCT)效率更低,因为COUNT(DISTINCT)是按GROUP BY字段分组,按DISTINCT字段排序,一般这种分布式方式是很倾斜的;比如:男UV,女UV,淘宝一天30亿的PV,如果按性别分组,分配2个reduce,每个reduce处理15亿数据。
(5) 数据倾斜是导致效率大幅降低的主要原因,可以采用多一次Map/Reduce的方法,避免倾斜。
最后得出的结论是:避实就虚,用job数的增加,输入量的增加,占用更多存储空间,充分利用空闲CPU等各种方法,分解数据倾斜造成的负担。KPTI和PTI补丁会对Linux的性能造成很大的影响。据报告显示,CPU性能下降的范围是5%~35%。
接下来是对Hive表中的一些优化方法的实验,
首先需要知道Hive支持的一些文件格式,
(1)sequencefile(序列文件,面向行,key value对,二进制格式的,可切割)。
(2)rcfile(面向列,record columnar file,记录列式文件)。
(3)orc(optimized record columnar file,替代了rc file,优化的rcfile)。
(4)parquet(google dremel格式)。
了解到Hive的文件格式之后,可以通过配置文件来设置文件的默认格式,
hive.default.fileformat(hive-site.xml)
然后创建一个序列表(sequencefile),
create table seqtset1(id int,name string,age int) stored as sequencefile;
序列文件不能直接插入文本文档,需要将文本文档上传到test4上,然后再插入到seqtest1上。
insert into seqtest1 select * from test4;
hive> insert into seqtest1 select * from test4;
WARNING: Hive-on-MR is deprecated in Hive 2 and may not be available in the future versions. Consider using a different execution engine (i.e. tez, spark) or using Hive 1.X releases.
Query ID = lvqianqian_20181121121532_1b8dee3a-eef0-4172-89c4-b15171a19cc5
Total jobs = 3
Launching Job 1 out of 3
Number of reduce tasks is set to 0 since there's no reduce operator
Starting Job = job_1479756136352_0001, Tracking URL = http://hadoop0:8888/ proxy/application_1479756136352_0001/
Kill Command = /home/hadoop/software/hadoop-2.7.3/bin/hadoop job -kill job_1479756136352_0001
Hadoop job information for Stage-1: number of mappers: 1; number of reducers: 0
2018-11-21 12:31:03,232 Stage-1 map = 0%, reduce = 0%
2018-11-21 12:31:12,598 Stage-1 map = 100%, reduce = 0%, Cumulative CPU 1.17 sec
MapReduce Total cumulative CPU time: 1 seconds 170 msec
Ended Job = job_1479756136352_0001
Stage-4 is selected by condition resolver.
Stage-3 is filtered out by condition resolver.
Stage-5 is filtered out by condition resolver.
Moving data to: hdfs://hadoop0:8020/user/hive/warehouse/myhive.db/seqtest1/. hive-staging_hive_2018-11-21_12-23-21_534_6082095967638849700-1/-ext-10000
Loading data to table myhive.seqtest1
MapReduce Jobs Launched:
Stage-Stage-1: Map: 1 Cumulative CPU: 1.32 sec HDFS Read: 4039 HDFS Write: 378110 SUCCESS
Total MapReduce CPU Time Spent: 1 seconds 320 msec
OK
Time taken: 481.128 seconds
除了可以限制Hive的输入文件以外,还有一个比较好用的优化方法,就是对其进行压缩,在Hive中对中间数据或最终数据做压缩,是提高数据吞吐量和性能(减小载入内存的数据量)的一种手段。对数据做压缩,可以大量减少磁盘的存储空间,比如基于文本的数据文件,可以将文件压缩40%或更多。同时压缩后的文件在磁盘间传输和I/O也会大大减少;当然压缩和解压缩也会带来额外的CPU开销,但是却可以节省更多的I/O和使用更少的内存开销。常见的压缩算法是lz4、LZO、snappy三种,三种压缩算法的效率比较如下,
lz4 < LZO < snappy
关于是否需要进行压缩的配置,也可以在上述的配置文件中进行配置,
hive.exec.compress.output=false //输出文件是否压缩,默认为false
hive.exec.compress.intermediate=false //启用中间文件是否压缩,默认为false
hive.intermediate.compression.codec=org.apache.hadoop.io.compress.SnappyCodec //设置压缩编解码器,默认为空
hive.intermediate.compression.type //压缩类型
压缩命令:
set hive.intermediate.compression.codec=org.apache.hadoop.io.compress.SnappyCodec;
以上命令可以对数据进行压缩来提高性能,除此之外,还可以在Hive存储数据的时候,对存储进行优化,对于存储优化,思路就是设置更多的副本数,增加热门数据,更好地利用本地化优势,
hdfs dfs -setrep -R -w 4 /user/hive/warehouse/employee;
以上几种优化的方式,都可以在Hive创建表和插入数据的时候,对其进行优化,但是在数据成功存储在Hive之后,也可以对其进行优化,就是对job和查询的优化,
(1) local mode(文件自动转成本地模式下),有三个需要设置:0.7.0之后,Hive支持本地模式(local)(hadoop standalone)运行。本地模式中,可以通过修改几个配置信息来进行Hive的优化,即将自动执行模式设置为本地模式,设置本地模式的输入最大字节数,设置本地模式的最大输入文件个数。具体配置信息如下,
hive.exec.mode.local.auto=true
hive.exec.mode.local.auto.inputbytes.max=134217728
hive.exec.mode.local.auto.input.files.max=4
(2)set hive.exec.mode.local.auto=true //将模式设置为本地模式。
(3)set hive.map.aggr=true; //在map中会做部分聚集操作,效率更高但需要更多的内存。
将所有优化方式都掌握之后,接下来向一个表中插入一组数据测试一下:insert into table test4 values(1,'kk',13);(下列命令行中存在local hadoop)。
第一步插入数据,
hive> insert into table test4 values(1,'kk',13);
Automatically selecting local only mode for query
WARNING: Hive-on-MR is deprecated in Hive 2 and may not be available in the future versions. Consider using a different execution engine (i.e. tez, spark) or using Hive 1.X releases.
Query ID = lvqianqian_20181121121532_1b8dee3a-eef0-4172-89c4-b15171a19cc5
Total jobs = 3
Launching Job 1 out of 3
Number of reduce tasks is set to 0 since there's no reduce operator
Job running in-process (local Hadoop)
2018-11-21 13:29:20,133 Stage-1 map = 0%, reduce = 0%
2018-11-21 13:29:52,869 Stage-1 map = 100%, reduce = 0%
Ended Job = job_local1269969100_0001
Stage-4 is selected by condition resolver.
Stage-3 is filtered out by condition resolver.
Stage-5 is filtered out by condition resolver.
Moving data to: hdfs://hadoop0:8020/user/hive/warehouse/myhive.db/test4/. hive-staging_hive_2018-11-21_13-24-49_487_3825075573599201360-1/-ext-10000
Loading data to table myhive.test4
MapReduce Jobs Launched:
Stage-Stage-1: HDFS Read: 79 HDFS Write: 181371729 SUCCESS
Total MapReduce CPU Time Spent: 0 msec
OK
Time taken: 304.094 seconds
第二步设置字节数和最大输入文件个数,
set hive.exec.mode.local.auto.inputbytes.max=50000000;
set hive.exec.mode.local.auto.input.files.max=5;
第三步启用本地模式,
set hive.exec.mode.local.auto=true;//默认为false;
除了这种方法之外,还可以对limit进行优化。关于limit优化,可以修改以下几个配置:
(1) 是否启用limit优化。当使用limit语句时,对源数据进行抽样。
(2) 在使用limit做数据的子集查询时保证的最小行数据量。
(3) 在使用limit做数据子集查询时,采样的最大文件数。
(4) 使用简单limit数据抽样时,允许的最大行数。
Hive的配置信息如下所示。
<property>
<name>hive.limit.optimize.enable</name>
<value>false</value>
<description>Whether to enable to optimization to trying a smaller subset of data for simple LIMIT first.</description>
</property>
<property>
<name>hive.limit.row.max.size</name>
<value>100000</value>
<description>When trying a smaller subset of data for simple LIMIT, how much size we need to guarantee each row to have at least.</description>
</property>
<property>
<name>hive.limit.optimize.limit.file</name>
<value>10</value>
<description>When trying a smaller subset of data for simple LIMIT, maximum number of files we can sample.</description>
</property>
除了可以修改以上配置来优化Hive之外,还可以修改几个配置:
(1) 是否开启自动使用索引。
(2) 每个分区表可以扫描多少分区。默认值“-1”表示无限制。
关于Hive的优化配置如下所示。
<property>
<name>hive.limit.optimize.fetch.max</name>
<value>50000</value>
<description>
Maximum number of rows allowed for a smaller subset of data for simple LIMIT, if it is a fetch query.
Insert queries are not restricted by this limit.
</description>
</property>
<property>
<name>hive.limit.pushdown.memory.usage</name>
<value>0.1</value>
<description>
Expects value between 0.0f and 1.0f.
The fraction of available memory to be used for buffering rows in Reducesink operator for limit pushdown optimization.
</description>
</property>
<property>
<name>hive.limit.query.max.table.partition</name>
<value>-1</value>
<description>
This controls how many partitions can be scanned for each partitioned table.
The default value "-1" means no limit.
</description>
</property>
以上几个方法都可以对Hive进行优化操作。
关于java虚拟机的重用部分(JVM重用是Hadoop调优参数的内容,对Hive的性能具有非常大的影响,特别是对于很难避免小文件的场景或者task特别多的场景,这类场景大多数执行时间都很短。)其实也可以对整个的Hive的数据操作部分进行一定的优化,并行转换成串行,同一个job的task才涉及重用,不同job的task运行在单独的JVM中set mapred.job.reuse.jvm.num.tasks=5;(本地环境下,就一个java虚拟机,数值如果小于5,就设置一个java虚拟机,如果超过5,就设置两个虚拟机,如果是-1的话,表示所有任务都在一个虚拟机中,就设置一个虚拟机,-1表示所有task都运行在一个JVM中)。explain解释执行计划,对于没有固定依赖关系的task,可以进行并发执行。当java虚拟机重用时,对于没有固定依赖关系的,就不能采用按序执行,这个时候就可以采用并发执行。因此以下配置可以将整个job进行并行处理,
set hive.exec.parallel=true;(启用并行执行) //启用mr的并发执行,默认为false
set hive.exec.parallel.thread.number=16;(定义了最大的并行运行的数量)//设置并发执行的job数,默认为8
Hadoop默认配置是使用派生JVM来执行Map和Reduce任务的,这是JVM的启动过程可能会造成相当大的开销,尤其是执行的job包含有成千上万个task任务的情况。关于JVM重用的配置如下所示,
[不推荐]
SET mapred.job.reuse.jvm.num.tasks=5; //在mapreduce-1使用,yarn不适用
com.it18zhang.myhadoop273_1211.join.reduce.App
[yarn]
//mapred-site.xml
mapreduce.job.ubertask.enable=false //启用单个jvm一系列task,默认为false
mapreduce.job.ubertask.maxmaps=9 //最大map数>=9,只能调低
mapreduce.job.ubertask.maxreduces=1 //目前只支持1个reduce
mapreduce.job.ubertask.maxbytes=128m
Hive中还有一个经常会出现的问题,也是比较严重的一个问题,会严重影响到Hive job 的运行效率,那就是Hive中的数据倾斜问题。通俗地说,就是我们在处理的时候数据分布的不均,导致了数据大量集中在某一点。造成了数据的热点。其实在MapReduce分析的时候最怕的就是数据倾斜,在做数据运算的时候会涉及count、distinct、group by、join等操作,这些都会触发shuffle操作。一旦触发,所有相同key的值就会拉到一个或几个节点上,就容易发生单点问题。通常会出现下面的情况:
Map阶段处理比较快,Reduce阶段处理比较慢。其实Reduce阶段不应该很慢,如果很慢,很大可能就是出现了数据倾斜。
(1) 有的Reduce很快,有的Reduce很慢。
(2) Hive的执行是分阶段的,Map处理数据量的差异取决于上一个stage的Reduce输出,如果在Map端,有的job运行很快,这其实也出现了数据倾斜。
关于数据倾斜的问题,可以修改一些配置来进行优化,如下所示,
SET hive.optimize.skewjoin=true; //开启倾斜优化
SET hive.skewjoin.key=100000; //key量超过该值,新的key发送给未使用的reduce
SET hive.groupby.skewindata=true;//在groupby中使用应用数据倾斜优化,默认为false
3.1.8 Hive的解释计划及分析
我们都知道,Hive在执行的时候会把所对应的SQL语句都会转换成MapReduce代码执行,但是具体的MR执行信息我们怎样才能看出来呢?这里就用到了explain的关键字,它可以详细的表示出在执行所对应的语句所对应的MR代码。语法格式如下。extended关键字可更加详细的列举出代码的执行过程。
$beeline>explain [extended] select sum(id) from customers ;
0: jdbc:hive2://localhost:10000/myhive> explain select sum(id) from users;


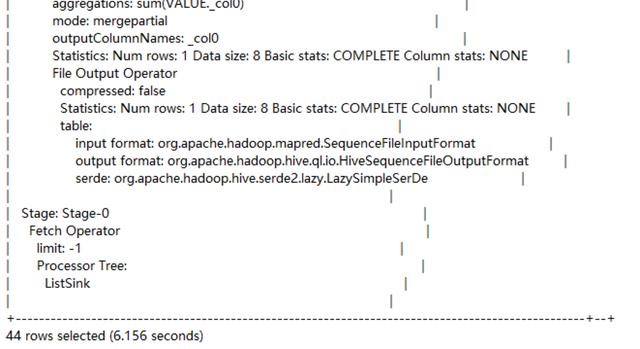



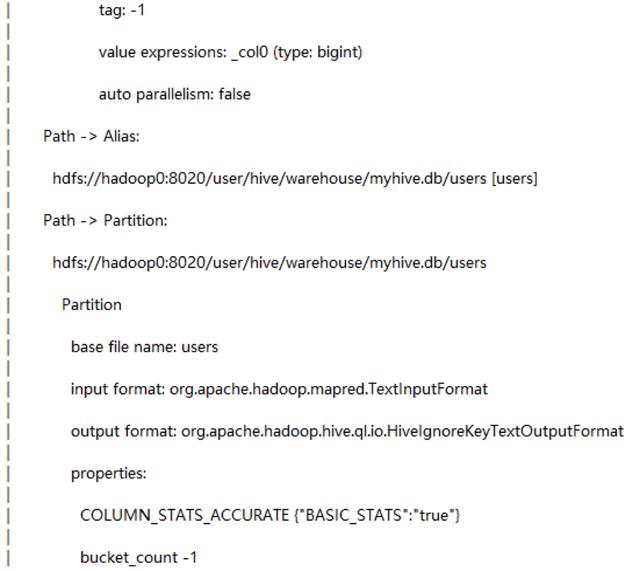






explain会把查询语句转化成stage组成的序列,主要由三方面组成:
(1) 查询的抽象语法树。
(2) plan中各个stage的依赖情况。
(3) 每个阶段的具体描述:描述具体来说就是显示出对应的操作算子和与之操作的对应的数据,例如查询算子,filter算子,fetch算子等等。
接下来举几个例子来看一下explain的语法及作用。
第一个例子,展示关于查询语句的具体过程。
hive> explain select * from test1;
OK
STAGE DEPENDENCIES:
Stage-0 is a root stage
STAGE PLANS:
Stage: Stage-0
Fetch Operator
limit: -1
Processor Tree:
TableScan
alias: test1
Statistics: Num rows: 1 Data size: 1 Basic stats: COMPLETE Column stats: NONE
Select Operator
expressions: id (type: int)
outputColumnNames: _col0
Statistics: Num rows: 1 Data size: 1 Basic stats: COMPLETE Column stats: NONE
ListSink
Time taken: 2.564 seconds, Fetched: 17 row(s)
第二个例子,展示关于查询语句以及限制行数的具体过程。
hive> explain select * from test1 limit 1,2;
OK
STAGE DEPENDENCIES:
Stage-0 is a root stage
STAGE PLANS:
Stage: Stage-0
Fetch Operator
limit: 2
Processor Tree:
TableScan
alias: test1
Statistics: Num rows: 1 Data size: 1 Basic stats: COMPLETE Column stats: NONE
Select Operator
expressions: id (type: int)
outputColumnNames: _col0
Statistics: Num rows: 1 Data size: 1 Basic stats: COMPLETE Column stats: NONE
Limit
Number of rows: 2
Offset of rows: 1
Statistics: Num rows: 1 Data size: 1 Basic stats: COMPLETE Column stats: NONE
ListSink
Time taken: 0.18 seconds, Fetched: 21 row(s)
在了解到explain的基本语法以及作用之后,还需要了解一个关键字,这个关键字就是analyze。该命令可以分析表数据,用于执行计划选择的参考。对表、partition、column level级别元数据进行统计,作为input传递给CBO(cost-based Optimizer),会选择成本最低查询计划来执行。接下来举一个简单的例子来说明一下analyze的作用。
这个例子的功能是分析计算统计的结果,如下,
hive> analyze table test1 compute statistics;
WARNING: Hive-on-MR is deprecated in Hive 2 and may not be available in the future versions. Consider using a different execution engine (i.e. tez, spark) or using Hive 1.X releases.
Query ID = lvqianqian_20181122130047_adb1e845-5401-44af-8c26-edb7d8f7270c
Total jobs = 1
Launching Job 1 out of 1
Number of reduce tasks is set to 0 since there's no reduce operator
Starting Job = job_1479847093336_0001, Tracking URL = http://hadoop0:8888/ proxy/application_1479847093336_0001/
Kill Command = /home/hadoop/software/hadoop-2.7.3/bin/hadoop job -kill job_1479847093336_0001
Hadoop job information for Stage-0: number of mappers: 1; number of reducers: 0
2018-11-22 13:22:05,790 Stage-0 map = 0%, reduce = 0%
2018-11-22 13:22:08,608 Stage-0 map = 100%, reduce = 0%, Cumulative CPU 2.5 sec
MapReduce Total cumulative CPU time: 2 seconds 500 msec
Ended Job = job_1479847093336_0001
MapReduce Jobs Launched:
Stage-Stage-0: Map: 1 Cumulative CPU: 2.5 sec HDFS Read: 2768 HDFS Write: 374948 SUCCESS
Total MapReduce CPU Time Spent: 2 seconds 500 msec
OK
Time taken: 500.843 seconds
0: jdbc:hive2://localhost:10000/myhive> analyze table users compute statistics ;
WARNING: Hive-on-MR is deprecated in Hive 2 and may not be available in the future versions. Consider using a different execution engine (i.e. spark, tez) or using Hive 1.X releases.
No rows affected (18.816 seconds)
0: jdbc:hive2://localhost:10000/myhive> desc extended users;