
聚类(Clustering)就是一种寻找数据之间内在结构的技术。聚类把全体数据实例组织成一些相似组,而这些相似组被称作簇。处于相同簇中的数据实例彼此相同,处于不同簇中的实例彼此不同。
聚类分析定义
聚类分析是根据在数据中发现的描述对象及其关系的信息,将数据对象分组。目的是,组内的对象相互之间是相似的(相关的),而不同组中的对象是不同的(不相关的)。组内相似性越大,组间差距越大,说明聚类效果越好。
聚类效果的好坏依赖于两个因素:1.衡量距离的方法(distance measurement) 2.聚类算法(algorithm)
聚类分析常见算法
-
K-Means
K-均值聚类也称为快速聚类法,在最小化误差函数的基础上将数据划分为预定的类数K。该算法原理简单并便于处理大量数据。
-
K-中心点
K-均值算法对孤立点的敏感性,K-中心点算法不采用簇中对象的平均值作为簇中心,而选用簇中离平均值最近的对象作为簇中心。
-
系统聚类
也称为层次聚类,分类的单位由高到低呈树形结构,且所处的位置越低,其所包含的对象就越少,但这些对象间的共同特征越多。该聚类方法只适合在小数据量的时候使用,数据量大的时候速度会非常慢。
案例
有20种12盎司啤酒成分和价格的数据,变量包括啤酒名称、热量、钠含量、酒精含量、价格。

问题一:选择那些变量进行聚类?——采用“R型聚类”
现在我们有4个变量用来对啤酒分类,是否有必要将4个变量都纳入作为分类变量呢?热量、钠含量、酒精含量这3个指标是要通过化验员的辛苦努力来测定,而且还有花费不少成本。
所以,有必要对4个变量进行降维处理,这里采用spss R型聚类(变量聚类),对4个变量进行降维处理。输出“相似性矩阵”有助于我们理解降维的过程。

4个分类变量各自不同,这一次我们先用相似性来测度,度量标准选用pearson系数,聚类方法选最远元素,此时,涉及到相关,4个变量可不用标准化处理,将来的相似性矩阵里的数字为相关系数。若果有某两个变量的相关系数接近1或-1,说明两个变量可互相替代。

只输出“树状图”就可以了,从proximity matrix表中可以看出热量和酒精含量两个变量相关系数0.903,最大,二者选其一即可,没有必要都作为聚类变量,导致成本增加。
至于热量和酒精含量选择哪一个作为典型指标来代替原来的两个变量,可以根据专业知识或测定的难易程度决定。(与因子分析不同,是完全踢掉其中一个变量以达到降维的目的。)这里选用酒精含量,至此,确定出用于聚类的变量为:酒精含量,钠含量,价格。
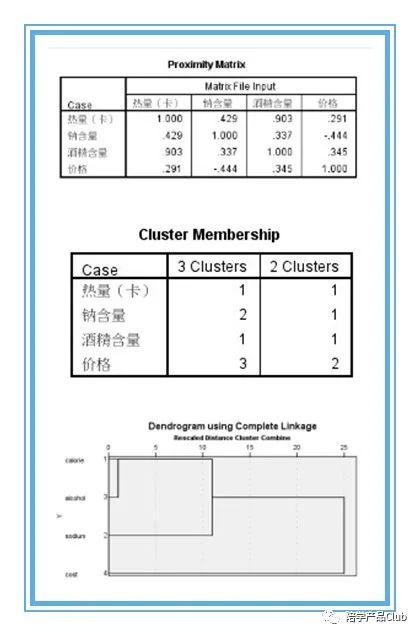
问题二:20中啤酒能分为几类?——采用“Q型聚类”
现在开始对20中啤酒进行聚类。开始不确定应该分为几类,暂时用一个3-5类范围来试探。Q型聚类要求量纲相同,所以我们需要对数据标准化,这一回用欧式距离平方进行测度。
主要通过树状图和冰柱图来理解类别。最终是分为4类还是3类,这是个复杂的过程,需要专业知识和最初的目的来识别。
这里试着确定分为4类。选择“保存”,则在数据区域内会自动生成聚类结果。

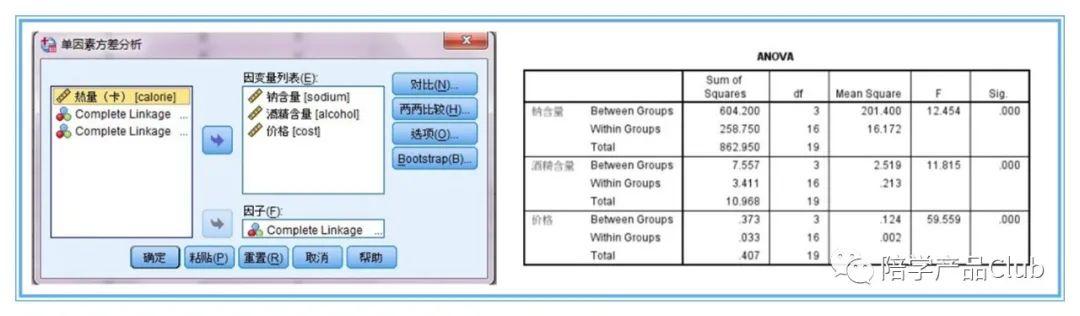
问题三:用于聚类的变量对聚类过程、结果又贡献么,有用么?——采用“单因素方差分析”
聚类分析除了对类别的确定需讨论外,还有一个比较关键的问题就是分类变量到底对聚类有没有作用有没有贡献,如果有个别变量对分类没有作用的话,应该剔除。
这个过程一般用单因素方差分析来判断。注意此时,因子变量选择聚为4类的结果,而将三个聚类变量作为因变量处理。方差分析结果显示,三个聚类变量sig值均极显著,我们用于分类的3个变量对分类有作用,可以使用,作为聚类变量是比较合理的。
问题四:聚类结果的解释?——采用”均值比较描述统计“
聚类分析最后一步,也是最为困难的就是对分出的各类进行定义解释,描述各类的特征,即各类别特征描述。这需要专业知识作为基础并结合分析目的才能得出。
我们可以采用spss的means均值比较过程,或者excel的透视表功能对各类的各个指标进行描述。其中,report报表用于描述聚类结果。对各类指标的比较来初步定义类别,主要根据专业知识来判定。这里到此为止。

以上过程涉及到spss层次聚类中的Q型聚类和R型聚类,单因素方差分析,means过程等,是一个很不错的多种分析方法联合使用的案例。
聚类分析的应用
-
商业上
聚类分析是细分市场的有效工具,被用来发现不同的客户群,并且它通过对不同的客户群的特征的刻画,被用于研究消费者行为,寻找新的潜在市场。
-
生物上
聚类分析被用来对动植物和基因进行分类,以获取对种群固有结构的认识。
-
保险行业上
聚类分析可以通过平均消费来鉴定汽车保险单持有者的分组,同时可以根据住宅类型、价值、地理位置来鉴定城市的房产分组。
-
互联网应用上
聚类分析被用来在网上进行文档归类。
-
电子商务上
聚类分析通过分组聚类出具有相似浏览行为的客户,并分析客户的共同特征,从而帮助电子商务企业了解自己的客户,向客户提供更合适的服务。





