关于本专栏

由民生银行潜望者Zabbix开源监控项目项目组投稿,为社区分享他们整理的Zabbix源码解析、民生银行潜望者Zabbix运维管理平台、多Server架构实现、容器/数据库/中间件全自动注册监控等项目文档。
本专栏将每季度发布2-3篇,持续更新,希望大家交流互动,一起讨论优化、提高!
Zabbix常见问题处理手册

张帆
中国民生银行潜望者Zabbix开源监控项目经理,在Zabbix多Server架构设计、自动化 监控方案设计实现、源码解析方面有丰富的经验。
一、概述
为了提高应对突发事件的处置能力,在出现故障的情况下,使用该手册中常见问题作参考能快速排出监控系统出现的故障,恢复监控系统正常运行。实现即时发现问题,快速处理问题,满足监控系统在突发情况下保障和恢复工作机制。
二、适用范围
本手册适用于zabbix server,proxy,agent在使用和运行过程中出现的异常问题,对常见问题提供解决方法参考。
三、监控系统常见问题
3.1 Zabbix server
3.1.1WEB页面无法登陆
问题描述:
WEB页面(http://<host>:<port>/zabbix)无法登陆
解决方法:
使用zabbix用户操作:
查看浮动IP地址是否在可用状态:ping <host_ip>
如不通:在主服务器端执行:/usr/bin/vrrpd –I bond0 –n –v 54 –p 100 <host_ip>
使用root用户操作:
查看HTTP进程是否运行:ps –ef | grep httpd
如未运行:执行 /usr/local/apache2/bin/httpd –k start启动HTTP进程
查看HTTP端口8000是否在监听状态:netstat –tulnp | grep 8000
如未在监听状态重启HTTP进程
使用zabbix用户操作:
查看zabbix server 进程是否运行:ps –ef | grep zabbix_server
如未运行:
执行/usr/local/zabbix/sbin/zabbix_server
3.1.2WEB页面无法刷新
问题描述:
WEB页面(http://<host>:<port>/zabbix)选项无法刷新
解决方法:
使用zabbix用户操作:
在zabbix server(主)端检查MySQL的IP地址连通性:ping <host_ip>
如不通请在MySQL检查网络或在MySQL端检查VIP
在zabbix server(主)端检查MySQL能否被访问:mysql –utest –p –h127.0.0.1
如数据库没有问题查看zabbix_server进程是否正常运行:ps –ef | grep zabbix_server
如未运行:
执行/usr/local/zabbix/sbin/zabbix_server启动zabbix server
3.1.3Web界面出现Allowed memory exhausted
问题描述:
zabbix server web页面ReportàNotifications项出现Allowed memory exhausted告警提示
解决方法:
需要将zabbix server主机上PHP配置文件相应内存配置调整,即/usr/local/php/etc/php.ini文件中memory_limit值进行增加。
3.1.4Trigger告警未发邮件
问题描述:
出现监控项告警未发告警信息到告警平台
解决方法:
1、zabbix server Web页面Reports →Action log 界面查看是否有该告警触发action日志,
2、如有触发action日志,查看zabbix server中告警日志 /tmp/具体日期zabbixAlertNew.log(如:2018-01-05zabbixAlertNew.log)是否有相应的日志。如有联系告警平台检查
3、如无触发action日志,Web页面Configuration→Actions 查看 SendEventNew 和sendevent状态是否是Enabled,如不是请点击Status列对应部分启动。
3.1.5监控项最新数据无趋势图
问题描述:查看某主机数值型监控项last data时,value处有最新数据
,但Graph没有展示趋势图,具体选择持续时间长的有趋势图展示,时间短的没有
分析:zabbix4.0历史数据和趋势数据设置若无单位,默认按秒存储,历史数据保存时间为1小时到25年,趋势数据保存时间为1天到25年,支持时间后缀,例如:h、d
解决方法:查看监控项历史数据和趋势数据保留时间,建议以d为单位,修改全部监控项的历史数据和趋势数据的sql脚本路径为:/test/updatehistory.sh,查看items表中history和trends字段设置的时间是否包含单位,如:
update zabbixser.items set history=’1d’;
update zabbixser.items set trends=’30d’;
然后执行脚本即可修改成功,监控项修改历史数据和趋势数据保留时间后,即可正常查看任意时间段的趋势图。
3.2 Zabbix proxy
3.2.1Proxy进程异常
问题描述:
Zabbix Proxy进行启动异常,日志显示无法连接数据库
解决方法:
使用MySQL用户操作
检查zabbix_proxy MySQL数据库进程是否异常:ps –ef | grep mysql
如无进程可执行启动:/bin/sh /path/to/the/file/mysql_safe –defaults-file=/path/to/the/file/my.cnf
如无法启动查看/path/to/the/log/error.log记录,根据报错排除故障。
使用MySQL用户操作:
检查 zabbix_proxy端MySQL 数据库是否可访问:mysql -uzabbix -p –h127.0.0.1
3.2.2Proxy无法收到server发送配置数据
问题描述:
Proxy正常工作会定时接受server发送的配置数据,Proxy日志显示无法收到配置数据
解决方法:
1、检查配置文件/path/to/the/file/zabbix_proxy.conf 中Server 地址是否正确。
2、检查配置文件/path/to/the/file/zabbix_proxy.conf中Hostname对应的值是否是与zabbix server Web界面配置的proxies名称(AdministrationProxies)是否一致,不一致请修改成一致。
3、查看proxy日志(位于/tmp/zabbix_proxy.log)具体报错信息,根据信息排除故障。
4、修改完后重启proxy进程。
3.2.3某个值的类型不可用
问题描述:
Value "XXX" of type "XXX" is not suitable for value type "XXXX" 或者Received value xxxx is not suitable for value type [xxxx] 此类报错可能出现在所有监控类型,多是监控项中的信息类型配置出现错误。
解决办法:
登陆zabbix web页面修改监控项中的信息类型
3.2.4 某个proxy突然出现unreachable poller进程繁忙程度过高的告警
问题描述:收到某个proxy的告警,unreachable poller进程繁忙度超过90%。
环境:zabbix server3.0 zabbix proxy3.0
问题分析:
unreachable poller进程负责对处于unreachable和unavailable状态的主机进行检查。当处于unreachable和unavailable状态的主机数量较大时,就会导致该进程繁忙程度增加。在这种情况下,就需要定位到时哪些主机处于unreachable或者unavailable状态。
解决方法:
登录到告警的proxy,执行命令tail -f /tmp/zabbix_proxy.log|grep unavailable可以看到有哪些主机是unavailable状态;
执行命令tail -f /tmp/zabbix_proxy.log|grep‘network error’,可以看到有哪些主机处于unreachable状态以及造成该主机unreachable的item key。
定位到主机和item key以后,就可以查看问题主机有哪些监控项出现报错。
在本次事件中,是因为该proxy下新加了一批主机,这些主机存在一些passive agent check,因为passive agent端口被禁用了,所以出现无法连接的情况,导致unreachable。
3.3Zabbix agent
3.3.1Agent所有监控项无数据
问题描述:
Agent监控项没有监控数据,也没有任何错误信息
解决方法:
使用zabbix用户操作:
在zabbix_server web页面MonitoringLatest date具体host 监控项都无最新数据变化:
1、检查Agent的运行状态,被动模式可直接在Zabbix Web上查看状态,主动模式可在该机器上检查zabbix_agent进程:ps –ef | grep zabbix_agent 是否正常运行。
如异常可登陆该host机器重启zabbix_agent,命令:/home/zabbix/zabbix-agent/zabbix_agentd restart
2、检查网络情况,探测Proxy(server)和Agent之间的端口通断性
3、检查Agent配置是否正确,A登陆该host机器检查/home/zabbix/zabbix-agent/etc/zabbix_agentd.conf中Hostname对应的值是否与Web页面相应的host名称一致。
3.3.2Zabbix_agent某监控项无监控数据检查
问题描述:
Agent某监控项无监控数据,其它监控项正常
解决方法:
使用zabbix用户操作
1、检查配置是否异常,查看监控项的运行状态,是否有not support等报错信息
2、手工执行监控项取值,看是否可正常取值,可用zabbix_get或登陆问题host手工执行监控脚本,通过返回情况来进一步检查问题原因。
3.3.3Trapper 监控项无监控数据检查
问题描述:
Trapper监控项无监控数据
解决方法:
使用zabbix用户操作
在被监控主机端执行:zabbix_sender –z server –p 10051 –s host –k key –o 监控数据在zabbix server (zabbix_sender默认位于:/path/to/zabbix-agent/bin/)端检查是否能接受到测试数据。
如果server能收到数据,则问题出在被监控主机监控脚本上,联系相关监控项维护人员处理。如果收不到数据,则需排查网络或server端trapper服务问题。
3.3.4Host not found处理
问题描述:
在zabbix_server.log和zabbix_proxy.log中 出现某host not found 信息
解决方法:
使用zabbix用户操作
1、检查该host的配置文件(默认:
/path/to/zabbix-agent/etc/zabbi_agentd.conf)配置hostname与zabbix_server web页面配置的hostname名字不相同,确保两者相同。
2、检查该host与proxy的网络是否能连通。
3.3.5监控项not support状态
问题描述:
WEB界面主机监控项显示not support, 表示监控项可以收到监控数据,但数据异常。
解决方法:
在zabbix web界面
1、web界面相应监控项配置数据类型是否与实际返回数据类型一致。
2、检查配置的KEY是否与定义的key一致
Zabbix agent主机端
3、检查相应监控项对应脚本返回结果是否有异常。
4、检查相应脚本是否有执行权限,自定义KEY是否正确。
3.3.6监控项nodata
问题描述:
WEB界面主机监控项没有数据同时也没not support(如配置了nodata的Trigger会触发告警),表示监控项无法收到监控数据。
解决方法:
1、检查被监控主机相应监控项对应脚本执行是否有异常(nodata一般意味着相关key的数据没有任何返回,脚本执行异常的概率最大)。
2、依次检查Proxy Server相关poller /trapper /snmp等服务是否正常。
3.3.7监控项延迟生效问题
1、检查Proxy端配置文件
ConfigFrequency
2、检查agent端配置文件
RefreshActiveChecks
主动式proxy 主动式监控项
最大延迟时间=(proxy的ConfigFrequency配置) (agent的RefreshActiveChecks
)
被动式监控项,没有proxy:
生效延迟时间:无,实时生效
Zabbix主动式监控项,没有proxy:
最大延迟时间=(agent的RefreshActiveChecks)
被动式proxy 被动式监控项:
最大延迟时间=(Server的ProxyConfigFrequency配置)
被动式proxy 主动式监控项:
最大延迟时间=(Server的ProxyConfigFrequency配置)
(agent的RefreshActiveChecks)
主动式proxy 被动式监控项:
最大延迟时间=(Server的ProxyConfigFrequency配置)
3.3.8无法检查到脚本文件
问题描述:
/path/to/zabbix-agent/etc/scripts/a.sh: [2] No such file or directory
解决办法:
检查文件路径,或者检查对应server/proxy的ExternalScripts= 配置项
3.3.9不支持的监控项的key值
问题描述:
Unsupported item key/ZBX_NOTSUPPORTED/Not supported by Zabbix Agent/Internal check is not supported。
解决办法:
非自定义监控项
官网确认当前版本key_值是否支持,确认agent版本,注意拼写错误。注意key_值与对应的监控类型是否匹配
自定义监控项
确认自定义监控项配置,agent的UserParameter= 是否与页面一致
3.3.10脚本执行超时
问题描述:
Timeout was reached/Timeout while executing a shell script
解决办法:
Zabbix客户端(主动式)
Zabbix_agent的配置项,Time_out=(默认3秒)
Vmware监控
对应Zabbix_server/Zabbix_proxy 的配置项VMwareTimeout
SNMP TRAP/Zabbix采集器
对应Zabbix_server/Zabbix_proxy 的配置项, TrapperTimeout
其他对应Zabbix_server/Zabbix_proxy 的配置项 Timeout
自定义监控项
尝试优化脚本效率
3.3.11无效的参数
问题描述:
Invalid % parameter案例:Invalid second parameter./Invalid first parameter.
解决方法:
官网确认该监控项的参数规范,确认server版本
错误案例:
比如 system.cpu.util[,idle],
如果填system.cpu.util[,abcde],就会报该类错误
3.3.12 无法获取一个被监控日志文件的信息:没有这个文件或者目录
问题描述:
Cannot obtain information for file "%": [2] No such file or directory案例:
Cannot obtain information for file "/tmp/test.log": [2] No such file or directory
解决方法:
检查被监控日志文件路径是否存在及zabbix可读权限
3.3.13 No "%" processes started
问题描述:
No "%" processes started案例:No "vmware collector" processes started出现场景:Zabbix内部监控
解决方法:
在对应的server/proxy上开启对应的配置
3.3.14 windows zabbix-agent启动报错不能执行套接字
问题描述:
Windos主机:[[11.11.11.11]:10051]由于系统缓冲区不足或队列已满,不能执行套接字
解决方法:
此问题是windows主机的连接数占满,无法建立新的连接。可重启agent端服务器释放连接,并重新启动zabbix-agent。
3.3.15 zabbix-agent启动报错
问题描述:
45647:20160808:220507.717 no active checks on server [11.11.11.11:10051]:host [22.22.22.22] not found
解决方法:
此问题是zabbix-agent和zabbix-server配置了不同的hostname,可主机名修改正确保持一致
3.3.16 Zabbix_agent心跳告警(nodata告警)
现象描述:某一台主机有监控数据,但是采集数据时间跟当前时间不一致,导致反复出现zabbix_agent心跳告警
现象及解决方式:
(1)心跳告警30秒出现一次且一直未恢复,可能是主机端有问题,配合查看有无ping监控告警确认是否是主机挂掉导致
(2)心跳告警及心跳恢复告警反复出现,可能是主机端数据上送延迟导致(大多发生在windows主机上),使用自动化重启zabbix_agent查看数据采集时间是否同步成功。
(3)上述现象的另一种原因,如果重启zabbix_agent后发现数据采集时间还未同步成功,说明主机的系统时间跟当前时间不同步,可适当调大心跳告警的默认阈值解决。
3.4其他
3.4.1 Active agent监控项数据采集间隔变长
现象描述:某些host的一些active agent监控项(UserParameter)采值间隔设置的是2分钟,但是实际获取到值的间隔却为10分钟左右,导致误告警
环境:zabbix server 3.0 zabbix agent3.0 AIX
问题分析:
active agent监控项由agent调用脚本或者系统命令完成原始数据采集,然后通过TCP连接传输到proxy端,再由proxy传到server端。出现采值间隔时间过长,可能是因为agent原始数据采集的间隔变长了,或者是数据传输过程变慢了。一般来说,数据传输变慢不会只影响zabbix agent,还会影响到系统上的其他服务。在这一事例中,并没有人反映其他服务出现异常,因此初步判断是zabbix agent采集原始数据的间隔变长了。
通过分析zabbix agent源码,发现Zabbix agent的原始数据采集过程是:由zabbix_agentd服务进程调用zbx_popen函数,fork一个新的进程来执行所需要的命令,并等待返回结果(同步调用,而非异步)。需要注意的是,所有active agent监控项由单个zabbix_agentd进程负责,即采值命令都是顺序地串行执行,因此如果某些监控项的命令执行时间过长就可能导致其他命令执行被推迟。假设一个host有60个监控项,每个监控项的采集间隔为60秒,则意味着平均每个监控项命令可用的执行时间为1秒,如果某一个监控项命令执行时间超过20秒,则意味着剩余的59个监控项需要在40秒内执行完毕,才能够保证准时获取到数据。如果不能在所需要的时间内执行完毕,zabbix agent并不会跳过一些监控项,而是继续按顺序执行,也就意味着采值间隔变长。
新的进程执行完命令以后,会调用process_value函数将命令执行结果插入到buffer中。在插入buffer之前会记录debug日志,内容为:for key [%s] received value [%s],在插入buffer以后也会记录debug日志,内容为:new element %d。
为了定位具体是哪些监控项导致间隔变长,我们开启了zabbix agent的debug模式(配置文件中的DebugLevel参数改为4并重启zabbix_agentd服务,或者执行命令./zabbix_agentd -R log_level_increase=’active checks’),然后跟踪日志中每一次zbx_popen函数的调用以及其执行的命令。通过两次调用之间的间隔可以计算出单次执行的时间长度。
通过分析日志,我们发现在所有监控项中有30个监控项平均执行时间长度在10秒左右。为了解决这一问题,我们将这30个监控项的采集间隔调整到10分钟一次,意味着每分钟只需要对这30个监控项中的3个执行命令。这样一来就可以有足够的时间来完成所有的数据采集。
下图为zbx_execute函数源码截图,该函数用于处理自定义监控项的命令,可以看到它进一步调用了zbx_popen函数来处理。

以下为zbx_popen函数截图,可以看到它会记录debug级别的日志,记录内容包括函数名和所执行的command。
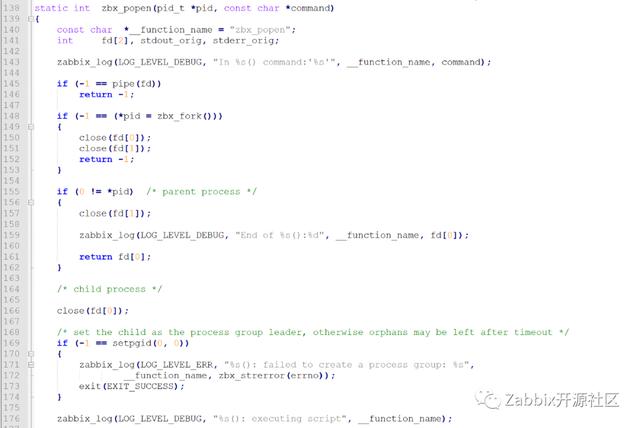
说明:该分析结果仅适用于用户自定义的agent监控项,也就是使用UserParemeter设置的监控项。
解决方法:
首先,开启zabbix agent端的debug模式。修改配置文件中的DebugLevel参数为4并重启zabbix_agentd,或者执行命令:/home/zabbix/zabbix-agent/sbin/zabbix_agentd -R log_level_increase=’active checks’
然后,执行命令: tail -f /tmp/zabbix_agentd.log | grep –E ‘In zbx_popen|received value’ 可以观察到每次调用的命令内容及其调用时间,根据两次调用之间的时间差可以计算出执行时间。
然后,对于执行时间明显过长的,首先考虑优化命令执行的效率,压缩执行时间。如果不能压缩执行时间,可以考虑调大相应监控项的采集间隔时间,调整的目标值根据需要进行计算,需要保证zabbix agent有足够的时间来执行所有item的采值命令。
3.4.2 某个主机的监控项数据实际采集频率比配置频率高,且部分取值和实际不符
现象描述:收到大量告警,观察该主机的events列表发现某个事件以两分钟为周期触发然后再close,然后再触发。进一步查看发现该告警相关的监控项数据实际采集频率比配置频率高,且部分取值和实际不符。
环境:zabbix server 3.0 zabbix agent 3.0 AIX
问题分析:
zabbix的trigger告警都是依赖于数据的,只要zabbix server收到数据就会对trigger进行重新计算并决定是否触发event,因此首先检查数据的内容和获取情况。找到trigger所依赖的item,查看其最近一段时间的数据,观察其采集数据的时间戳,发现相邻的两次值的时间间隔在1分钟左右(但是并不是准确的1分钟),而该监控项设置的采集间隔为2分钟。正常情况下,单个agent会以固定的周期发送数据到server端。这种时间间隔的不一致,表明可能存在不止一个agent在发送该监控项的数据(zabbix server并不会主动验证数据的来源ip是否合法,它只考虑agent hostname是否相符,当两个不同ip的host以同样的agent hostname发送数据时,zabbix server会照单全收,同时接受两份数据,这两份数据都会用于trigger的计算)。
对于如何找到具有同样的agent hostname的另一个host的问题,请见下面的解决方法。
解决方法:
1 登录zabbix原生页面,查看告警主机的system.hostname监控项的值,会发现交叉出现两个名称,其中有一个名称与当前host name不一致,这个名称就是有问题的主机。
2 定位了问题主机以后,登录该问题主机,查看其agent配置文件,会发现配置文件中的agent hostname是错误的,将其修改为正确的值,然后重启agent即可解决。
3 需要注意的是:这一问题能够暴露出来是因为问题主机发送的数据触发了告警,如果问题主机发送的数据不能触发告警,则有可能无法暴露出问题。需要通过数据获取的频率或者通过system.hostname监控项的值来检查判断是否存在问题。
3.4.3 如何对某个监控项的数据传输整个过程进行跟踪和定位?
背景:我们发现某个agent active监控项的数据接收延迟了,但是数据从agent到server端经过了多个环节,如何确定数据在每个环节经过了多长时间的处理?
问题分析:
Zabbix监控数据采集过程为数据源->agent->proxy->server,任何一个环节或者几个环节的延迟都会导致最终的延迟。因此,需要定位每个环节的数据接收和发送时间,才能明确故障出现在什么地方。Zabbix无论是agent、proxy或者server,都有不同级别的日志,可以记录非常详细的信息,而且日志的每条记录都有进程id以及精确到毫秒的日期和时间,因此可以尝试通过日志确定数据在每个环节的处理时间。
具体方法:
1)数据在agent端的接收和发送:
Agent端成功采集到监控数据以后会在debug级别的日志中记录一条包含‘received value’关键字的日志,因此可以使用下面的命令获取到其采集数据成功的时间戳:
# ./zabbix_agentd -R log_level_increase=’active checks’
# tail -f /tmp/zabbix_agentd.log | grep ‘received value’ |grep ‘<item_key>’
Zabbix agent向proxy发送数据的过程由send_buffer函数负责,该函数的debug级别日志会记录每次所发送的json串和接收的响应json串,可以使用下面的命令开启debug日志并查询所需的日志内容:
# ./zabbix_agentd -R log_level_increase=’active checks’
# tail -f /tmp/zabbix_agentd.log | grep -E ‘JSON before sending | JSON back ‘ | grep ‘<item_key>’
2)数据在proxy端的接收和发送:
Proxy进程每次处理从socket读到的数据,都会调用process_trap函数,该函数的debug级别的日志会记录所处理的字符串(json串)。因此可以使用下面的命令开启debug日志,并筛选所需的日志内容:
# ./zabbix_proxy -R log_level_increase=trapper
# tail -f /tmp/zabbix_proxy.log|grep ‘trapper got ’ | grep ‘agent data’ | grep ‘<item_key>’|grep ‘<host>’
而proxy向server端批量发送数据由data sender进程负责,该进程是从数据库读取的监控数据。在此过程中zabbix日志没有记录发送的数据内容,但是会记录每次发送的数据在数据库中的id,通过该id可以间接查询到数据内容。id在日志中的查询方法为:
# ./zabbix_proxy -R log_level_increase=’data sender’
# tail -f /tmp/zabbix_proxy.log | grep ‘End of proxy_get_history_data()’
3)数据在server端的接收:
Server端接收数据进程与proxy端相同,也是trapper进程负责。但是server接收的proxy data中是以itemid来识别监控项的,而非item key。筛选所需日志可使用以下命令:
# ./zabbix_server -R log_level_increase=trapper
# tail -f /tmp/zabbix_server.log|grep ‘trapper got ‘|grep ‘proxy data’|grep ‘<itemid>’
3.4.4 关闭某个trigger后出现大量Escalation cancelled告警,为什么?
问题背景:在关闭某个trigger后出现大量告警,其内容为“NOTE:Escalation Cancelled……”
问题分析:
这一现象与zabbix对escalation的处理方式有关。在zabbix server端,Escalator进程负责循环调用process_escalations函数对escalation进行处理。该函数会创建一个指针向量(声明为:zbx_vector_ptr_t escalations)用于临时存储当前处理的escalations,待处理完毕以后将该向量中的相关修改内容flush到数据库中,最后再销毁该向量。该函数首先从数据库escalations表中查询符合条件的记录(nextcheck在未来3秒之前,即小于now 3),并按照actionid、triggerid、itemid、escalationid进行排序。从数据库获取到的这些escalations会按照1000个一批进行分批处理。因此,escalator进程主要负责处理escalations表中的信息,而每个escalation的预期处理时间则由nextcheck字段的值决定。
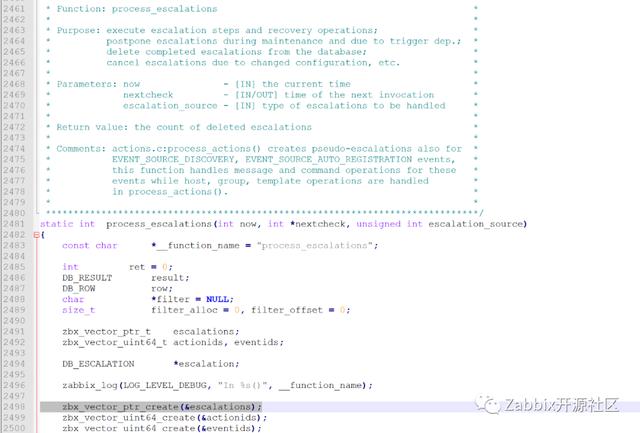
Escalation status枚举值:

Escalation记录最初由process_actions函数insert到数据库中,此时escalation的status字段值为0(即active状态),但是此时并没有设置nextcheck值和esc_step值,二者都是用的默认值0。实际上,Nextcheck和esc_step值在process_escalations过程中由escalation_execute_operations函数进行更新,更新过程为:
a 将esc_step值加1(此时,初始的0值将改为1,如果是在第2步则由1修改为2)。
b 在operations表中查找满足esc_step条件的记录,如果存在则执行相关操作。
c 调用flush_user_msg,将需要发送的message插入到alerts表中。
d 检查operations表中是否存在大于当前esc_step值的记录,根据查询结果进一步处理。
e 如果上一步的查询结果非空,说明存在后续待执行的操作,则修改nextcheck值为当前时间 设定的周期;如果查询结果为空但是设定了recovery operation,则将状态值改为2(sleep状态)并将nextcheck修改为默认step duration以后的时间;如果查询结果为空并且不存在recovery operation,则将状态值改为3(competed状态)。
对于状态值为3的escalations,process_escalations函数负责将这些escalation从数据库删除,因此在数据库中不会存在这个状态值。
escalation_execute_operations函数部分代码截图:

回到process_escalations函数对escalation的分批处理。其处理方法为按照顺序逐个处理,每个escalation会先检查其相应的action、event、trigger是否被删除,如果为已删除,则记入zabbix日志并从数据库中删除对应的escalation记录。如果未被删除,则继续检查action、event、trigger的状态是否为disabled,如果为disabled状态则先调用escalation_cancel函数执行escalation取消操作,然后再记入日志并从数据库删除。
process_db_escalations函数部分代码截图:

对于escalation cancelled告警,zabbix会通知此前曾经收到过该event通知的收件人。escalation_cancel函数负责将“NOTE:Escalation Cancelled”信息写入数据库并记日志。写入数据库的过程是,先查找符合条件的userid和mediatype(根据过往的alerts记录),对每个userid mediatye都在alerts表中插入一条记录(clock字段值为当前时间)。如果没有找到任何符合条件的userid mediatype,则插入一条状态值为2的alert记录。然后escalation_cancel函数会将escalation->status的值修改为3(该状态的escalation会从数据库删除)。

具体到本例中出现的大量escalation cancelled告警问题,告警主机事先已经生成了大量event并且这些event一直处于problem状态,因此在escalations表中相应会存在同等数量的escalation记录。这些escalation都已经完成了第一步的动作,但是因为event没有恢复,所以escalator进程会持续更新nextcheck值(按照action设置,以1小时为周期)。当trigger关闭以后,escalator进程对每个escalation进行cancel操作,并将报警信息写入alerts表(随后由alerter进程负责发送)。
解决方法:
可以调整action设置,使得event能够在一定时间内达到completed状态,而不致触发escalation cancel操作。
3.4.5 某个windows agent 采集不到cpu指标项,查看日志发现大量“Collector is not started”
问题背景:巡检过程中发现某个windows主机的cpu监控项没有值,检查zabbix agent日志文件发现大量“Collector is not started”记录。
问题分析:
关于该问题,首先该主机的zabbix agent端的日志记录如下图,可以发现在报出Collector not started之前还有两行错误日志:
1 PdhLockupPerfNameByIndex() failed: [0x800007D0] 无法连接到指定的计算机或该计算机已处于脱机状态
2 Cannot add performance counter “\UnknownPerformanceCounter(_Total)\% Processor Time”: Invalid performance counter format
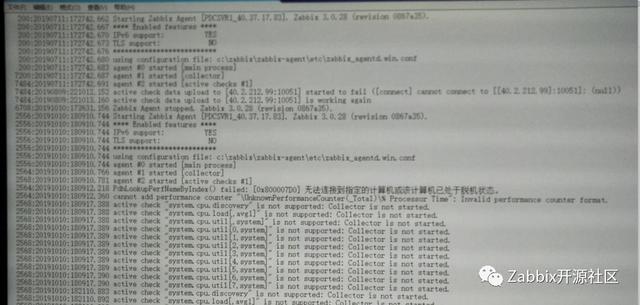
因此怀疑后面的错误都是因为这两行报错引起。根据这两行错误日志内容进行代码追踪,从追踪结果来看,这两个错误起始于init_cpu_collector函数(src/zabbix_agent/cpustat.c),该函数调用了get_counter_name和add_perf_counter两个函数,分别导致了第一行和第二行的报错。具体来说,这两个函数执行过程中调用了两个Windows API(get_counter_name调用了PdhLookupPerfNameByIndex函数,add_perf_counter调用了PdhAddCounter函数),zabbix正是在调用这两个API过程中出现错误,从而输出了两行错误信息。
另外,观察发现这两行错误发生的时间正好是在os重启以后。我们怀疑当os重启以后zabbix调用这两个Windows API时出现了问题,最终导致这个问题。
get_counter_name函数(src/libs/zbxwin32/perfmon.c)报错的具体代码为:

add_perf_counter函数(src/zabbix_agent/perfstat.c中)报错的具体代码如下,该函数会报Invalid performance counter format。

进一步分析zabbix agent端collector进程的工作原理。zabbix定义了一个名为collector的变量,该变量为ZBX_COLLECTOR_DATA结构体类型,zabbix使用该变量存储监控数据,在服务启动时会对该变量进行初始化,使用上文中的init_cpu_collector函数。上文的两行错误就是在这个初始化过程中出现的。
结构体定义如下:
typedef struct{ZBX_CPUS_STAT_DATAcpus;#ifndef _WINDOWSint diskstat_shmid;#endif#ifdef ZBX_PROCSTAT_COLLECTORzbx_dshm_tprocstat;#endif#ifdef _AIXZBX_VMSTAT_DATAvmstat;#endif}ZBX_COLLECTOR_DATA;
typedef struct{PERF_COUNTER_DATA**cpu_counter;PERF_COUNTER_DATA*queue_counter;intcount;}ZBX_CPUS_STAT_DATA;
上文的初始化过程失败并未导致zabbix agentd服务失败,所以当zabbix_agentd服务继续试图从collector变量中收集cpu信息时,出现了“Collector is not started”的错误。
在zabbix_agent/cpustat.c中的get_cpustat函数有该报错的具体代码,如下图:
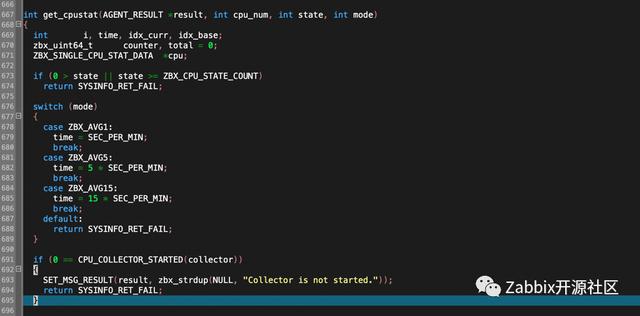
解决方法:
从以上分析来看,该问题属于zabbix agent在windows环境中的一个缺陷。在不修改zabbix代码的情况下,我们需要检查windows系统环境,保证zabbix对windows API的调用能够成功。
3.4.6 安装agent后,主机被置为生产,但是原始状态是预维护状态,导致告警。
现象描述:某批主机安装了agent以后,状态由预维护改为生产状态,生成了大量告警。但是这批主机在安装agent之前就是预维护状态,本来不需要进行告警。
环境:所有使用自动化平台进行agent部署的情况
问题分析:
zabbix agent自动化部署的过程是先将host修改为预维护状态,待安装agent完毕以后,再将host修改为生产状态。而在第一步修改为预维护状态之前并不会记录原始状态。因此,即使原始状态是“预维护”,在安装agent以后也会被修改为生产状态。
解决方法:
临时的解决方法是,部署agent之前,先查询目的host的状态,对于那些原始状态为“预维护”的,待部署完毕以后再修改回“预维护”状态。
彻底的解决方法是修改部署程序,修改状态之前先记录host的原始状态,待安装完毕以后将状态恢复为原始状态。
3.4.7 监控部署所使用的AIX的tar包,用ftp传输以后再解压时出现异常
现象描述:zabbix部署时所使用的tar包,使用ftp传输以后再解压,有时候出现解压以后缺少文件的情况。
环境:ftp AIX/UNIX/LINUX
问题分析:
使用ftp在windows和unix/linux系统之间传输文件的过程中有可能出现内容的变化。因为ftp传输模式分为ascii和binary两种模式,ascii模式下传输会对检测到的换行符进行修改以适应目的系统,binary模式则是原样传输不进行修改。
解决方法:将所有ftp的传输模式修改为binary模式。
联系我们
电话:17502189550(微信同号)
邮箱:china@zabbix.com
网站:www.zabbix.com/cn www.grandage.cn
一键关注
关注公众号
加入社区群


Zabbix社区,因你而更美好
,




