最近国产GPU、英特尔独显GPU以及英伟达RTX 40系列和AMD RX 7000等下一代GPU的信息在媒体上不断曝光。但这些GPU还没有正式发布,肯定不能用3DMark及各种游戏的实际运行、跑分来展示能力,相关报道中“与xxxx相当”、“比xxxx强xxxx”的说法到底是如何又是从何而来呢?

目前的GPU都是由很多小处理核心,或者叫流处理器组成,这个核心每时钟周期只负责处理一个浮点数据,所以总的浮点运算次数就是核心数量×时钟周期了(当前常见的GPU浮点运算单位一般是TFLOPS,即每秒浮点操作多少万亿次。)。又因为现在的核心可以一次性处理一个双精度浮点数据,相当于两个单精度浮点数据,所以再×2就得到了GPU的浮点运算次数。
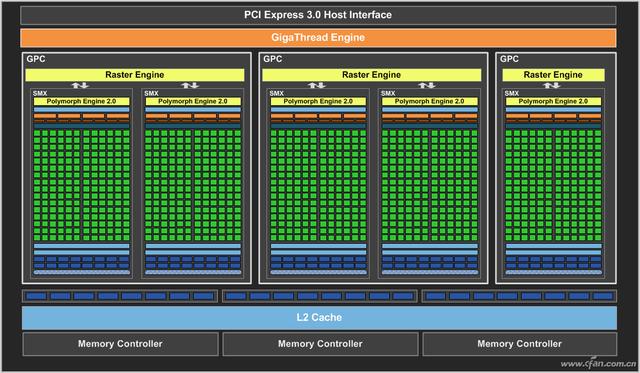
目前国产GPU、英伟达RTX 40系列和AMD RX 7000系列与当前GPU、显卡的性能对比其实就是根据其透露出的频率、流处理器数量配置而计算出来的理论浮点计算性能。因为现在的图像是分成像素点来处理的,每个点的色彩都要进行浮点运算,然后组合成一幅图片,所以这个浮点计算能力确实可以代表显卡或GPU的图像处理能力。

因为每秒处理的像素点越多,在同画质、同分辨率下,每秒能处理的画面数量当然就越多,游戏的帧速(每秒画面数)越高。对使用同一代特别是同一核心的显卡,算出它的浮点运算能力,基本就了解游戏画面的生成速度了。当然这是CPU、内存、输出接口、显示器等配件不拖后腿的情况下。

但对于不同代甚至不同架构的GPU,这种对比就不合适了,比如RTX 3080拥有两倍于RTX 2080 Ti的浮点运算次数,帧速能达到RTX 2080 Ti的两倍吗?这就牵扯出了另一个问题,也就是核心的效率,因为谁也不能保证所有的核心或者流处理器能一直满载、有效运行,它的实际发挥还要考虑到前端的分配、后端的合成、显存数据等单元的配合。

RTX 30系列的“问题”更大,它们让每个核心中的整数运算单元也参加浮点运算,得到成倍的“理论”运算能力。但干非“专业”工作,整数单元的浮点运算效率肯定是不如专业的浮点运算单元的,所以效率大幅下降。最终翻倍的理论浮点性能带来的只是不到40%的实际帧速提升。所以RTX 40和RX 7000到底如何,除了浮点计算性能外,还要看架构、效率有没有大的变化。

其实国产GPU以及前面对比中没提到的Intel GPU理论性能还有一个不同的地方,那就是它们已经开始密集测试了,因此除了浮点计算外,还多了一个OpenGL计算能力。相关测试在一定程度上能反映GPU架构的效率,但也同样不能和游戏性能完全扥通,因为游戏需要Direct 3D等消费级3D技术,与OpenGL的运行方式不一定相同,只能说参考意义比浮点计算更大一些吧。