随着项目业务的快速扩张,你是否已经注意到很多单独的线程游离在各个模块中,一旦想做线程方面的监控与优化,代码将需要大动干戈。
相信你一定用过rxjava、okHttp这些流行的框架,它们内部都涉及线程的调度,且封装好一系列的API供你使用,你甚至完全不必关心这些线程是如何工作的。如果单独使用它们都没问题,可是如果你从项目架构的角度考虑是否应该重新考量如何使用它们。
为什么要用线程池?
- 线程属于稀缺资源,它的创建会消耗大量系统资源。
- 线程频繁地销毁,会频繁地触发GC机制,使系统性能降低。
- 多线程并发执行缺乏统一的管理与监控。
线程池的使用
线程池的创建使用可通过java并发包中的Executors类完成,它提供了创建线程池的常用方法。
- newFixedThreadPool
- newSingleThreadExecutor
- newCachedThreadPool
- newScheduledThreadPool
后面会陆续介绍它们,我们先来看一个例子。
public void main() { ExecutorService executorService = Executors.newFixedThreadPool(3); for(int i = 0; i < 20; i ) { executorService.execute(new MyRunnable(i)); } } static class MyRunnable implements Runnable { int id; MyRunnable(int id) { this.id = id; } @Override public void run() { try { Thread.sleep(3000); Log.i("threadpool", "task id:" id " is running threadInfo:" Thread.currentThread().toString()); } catch (InterruptedException e) { e.printStackTrace(); } } } 复制代码
示例中创建了一个固定线程数的线程池,并向其中添加20个任务。

通过log打印可以看到,日志一次打印三条,每3秒打印一次,所有任务都在名为pool-1-thread-1,pool-1-thread-2,pool-1-thread-3的线程中运行,这与我们为线程池设置的大小相吻合。导致这种现象的原因是线程池中只有三个线程,当一次性将20个任务加入到线程池中时,前三个任务优先执行,后面的任务都在等待。
而如果我们把 ExecutorService ExecutorService = Executors.newFixedThreadPool(3); 换为 ExecutorService executorService = Executors.newCachedThreadPool();再来看一下效果。
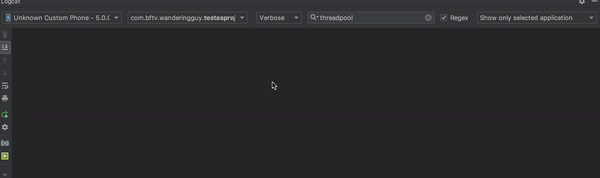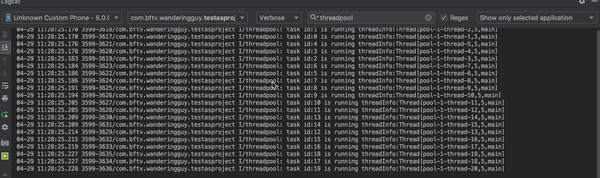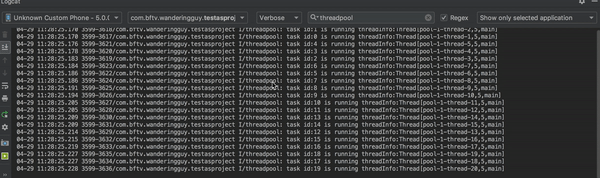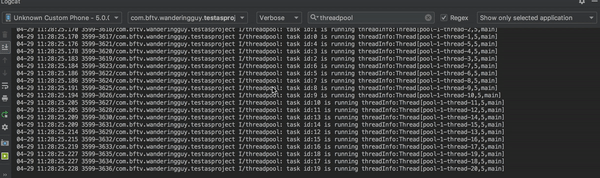
一瞬间任务都执行完了,可以预见使用newCachedThreadPool方式创建的线程池,执行任务时会创建足够多的线程。
接下来,我们正式来看线程池的内部的工作原理,我们分为三个部分来讲解。

常见的线程池种类上面已经提及,我们来看一下它们是如何创建出来的,我们举两个栗子。
# -> Executor.newFixedThreadPool public static ExecutorService newFixedThreadPool(int nThreads) { return new ThreadPoolExecutor(nThreads, nThreads, 0L, TimeUnit.MILLISECONDS, new LinkedBlockingQueue<Runnable>()); } # -> Executor.newSingleThreadExecutor public static ExecutorService newSingleThreadExecutor() { return new FinalizableDelegatedExecutorService (new ThreadPoolExecutor(1, 1, 0L, TimeUnit.MILLISECONDS, new LinkedBlockingQueue<Runnable>())); } 复制代码
可见线程池的创建都是通过ThreadPoolExecutor完成的,来看一下它的构造方法。
# -> ThreadPoolExecutor构造方法 public ThreadPoolExecutor(int corePoolSize, int maximumPoolSize, long keepAliveTime, TimeUnit unit, BlockingQueue<Runnable> workQueue) { this(corePoolSize, maximumPoolSize, keepAliveTime, unit, workQueue, Executors.defaultThreadFactory(), defaultHandler); } public ThreadPoolExecutor(int corePoolSize, int maximumPoolSize, long keepAliveTime, TimeUnit unit, BlockingQueue<Runnable> workQueue, ThreadFactory threadFactory, RejectedExecutionHandler handler) { ... this.corePoolSize = corePoolSize; this.maximumPoolSize = maximumPoolSize; this.workQueue = workQueue; this.keepAliveTime = unit.toNanos(keepAliveTime); this.threadFactory = threadFactory; this.handler = handler; } 复制代码
构造方法声明的一系列参数非常重要,理解了它们线程池的基本原理你就掌握了,我们来看看他们的具体含义:
- corePoolSize 核心线程数,除非设置核心线程超时(allowCoreThreadTimeOut),线程一直存活在线程池中,即使线程处于空闲状态。
- maximumPoolSize 线程池中允许存在的最大线程数。
- workQueue 工作队列,当核心线程都处于繁忙状态时,将任务提交到工作队列中。如果工作队列也超过了容量,会去尝试创建一个非核心线程执行任务。
- keepAliveTime 非核心线程处理空闲状态的最长时间,超过该值线程则会被回收。
- threadFactory 线程工厂类,用于创建线程。
- RejectedExecutionHandler 工作队列饱和策略,比如丢弃、抛出异常等。
线程池创建完成后,可通过execute方法提交任务,线程池根据当前运行状态和特定参数对任务进处理,整体模型如下图:

下图清晰的展示了线程池提交任务后的流程,不再赘述。

接下来我们看看Executors工具类中常见的几种线程池使用的构造参数是怎样的。

其中specific指的是需要使用者传入固定值。
这里需要先对阻塞队列进行额外的分析。
阻塞队列
你有没有想过为什么要用阻塞队列,非阻塞的不行吗?
实际上阻塞队列常用于生产者-消费者模型,任务的添加是生产者,任务的调度执行是消费者,他们通常在不同的线程中,如果使用非阻塞队列,那势必需要额外的处理同步策略和线程间唤醒策略。比如当任务队列为空时,消费者线程取元素时会被阻塞,当有新的任务添加到队列中时需唤醒消费者线程处理任务。
阻塞队列的实现就是在添加元素和获取元素时设置了各种锁操作(Lock Condition)。
另一个需要关注的是阻塞队列的容量问题,因为根据线程池处理流程图,阻塞队列容量的大小直接影响非核心线程的创建。具体来说,当阻塞队列未满时并不会创建非核心线程,而是将任务继续添加到阻塞队列后面等待核心线程(如果有)执行。
Integer.MAX_VALUE
应根据实际需求选择合适的阻塞队列,现在我们再来看这些线程池的使用场景。
- newFixedThreadPool 它的特点是没有非核心线程,这意味着即使任务过多也不会创建新的线程,即使任务闲置也仍保留一定数量的核心线程。等待队列无限,性能相对稳定,适用于长期有任务要执行,同时任务量也不大的场景。
- newSingleThreadExecutor 相当于线程数量为1的newFixedThreadPool,因为线程数量为1,所以用于任务需顺序执行的场景。
- newCachedThreadPool 它的特点是没有核心线程,非核心线程无限,可短时间内处理无限多的任务,但实际上创建线程十分消耗资源,过多的创建线程极可能导致OOM,同时设置了线程超时时间,还涉及到线程资源的释放,大量任务并行时性能不稳定,少量任务并行且后续不再需要执行其他任务的场景可使用。
- newScheduledThreadPool 通常用于定时或延迟任务。
在实际开发过程中不建议直接使用Executors提供的方法,如果任务规模、响应时间大致确定,应根据实际需求通过ThreadPoolExecutor各种构造函数手动创建,还自由可控制线程数、超时时间、阻塞队列、饱和策略(默认的饱和策略都是AbortPolicy即抛出异常)。
饱和策略
内置的饱和策略有如下四种
- DiscardPolicy 将丢弃被拒绝的任务。
- DiscardOldestPolicy 将丢弃队列头部的任务,即先入队的任务会出队以腾出空间。
- AbortPolicy 抛出RejectedExecutionException异常。
- CallerRunsPolicy 在execute方法的调用线程中运行被拒绝的任务。
用户也可通过实现RejectedExecutionHandler接口自定义饱和策略,并通过ThreadPoolExecutor多参的构造函数传入。
接下来我们有必要了解一下线程池的继承结构。
线程池类图

- Executor 基类接口,仅定义一个execute方法,这也就是我们提交任务时使用的方法,使用execute添加的任务不具备返回值。
- ExecutorService 仍然是一个接口,开始产生池化概念,定义了带返回结果的提交任务方法submit,以及关闭线程池的SHUTDOWN方法。
- AbstractExecutorService 实现了大部分接口方法,剩余shutDown相关和execute抽象方法未实现。
- ThreadPoolExecutor 最常用的线程池
- ScheduledThreadPoolExecutor 定义了一系列支持延迟任务的线程池。
- ForkJoinPool 与ThreadPoolExecutor解决的问题不同,它采用分治思想,将一个任务细分为多个子任务在多线程中执行。比如要计算1到100万的整数和,按ThreadPoolExecutor的方案是将这一个任务拆分为多个提交至线程池,而按ForkJoinPool的方案是提交一个任务到线程池,任务的拆分细化工作交由自定义任务执行。感兴趣的小伙伴参考这篇文章 多线程 ForkJoinPool 详解 。
线程池大小选定
了解了线程池的内部结构,在实战中我们应该如何选取线程池的大小呢?
这需要大致了解任务是CPU密集型还是IO密集型。
最佳线程数 = CPU 核数 * [ 1 (I/O 耗时 / CPU 耗时)]
以单核、CPU计算和I/O操作的耗时是1:2为例,可以看到三个线程可使CPU利用率达到100%(本例来自 极客时间 --Java并发编程实战 )。

线程池状态
线程池的状态在整个任务处理过程中至关重要,比如添加任务时会先判断线程池是否处于运行状态,任务添加到队列后再判断运行状态,如果此时线程池已经关闭则移除任务并执行饱和策略。
我们接下来看看线程池的几种状态:
- RUNNING :能接受新提交的任务,并且也能处理阻塞队列中的任务;
- SHUTDOWN:关闭状态,不再接受新提交的任务,但却可以继续处理阻塞队列中已保存的任务。在线程池处于 RUNNING 状态时,调用 shutdown()方法会使线程池进入到该状态。(finalize() 方法在执行过程中也会调用shutdown()方法进入该状态);
- STOP:不能接受新任务,也不处理队列中的任务,会中断正在处理任务的线程。在线程池处于 RUNNING 或 SHUTDOWN 状态时,调用 shutdownNow() 方法会使线程池进入到该状态;
- TIDYING:如果所有的任务都已终止了,workerCount (有效线程数) 为0,线程池进入该状态后会调用 terminated() 方法进入TERMINATED 状态。
- TERMINATED:在terminated() 方法执行完后进入该状态,默认terminated()方法中什么也没有做。
一图说明状态流转

总结
回到文章开始的问题:RxJava和OkHttp采用哪种线程池进行调度的呢?
- 在rxjava内部定义了几个线程调度器常用的 Schedulers.io() 和 Schedulers.computation() 分别对应了IO密集型和CPU密集型调度器,内部均使用的是 ScheduledThreadPoolExecutor 线程池,这是出于链式调用中可能存在delay等延时操作的考量而设计的。二者不同点在于最大线程数不同,对computation来说最大线程数为CPU核心数,而对io来说最大线程数为无限。
- 在OkHttp中默认使用线程池就是 newCachedThreadPool ,上面介绍过此线程池的弊端,这可能是出于高并发量的考量而做的选择,在实际使用中可根据实际情况灵活配置。
# -> Dispatcher public Dispatcher() { } public Dispatcher(ExecutorService executorService) { this.executorService = executorService; } public synchronized ExecutorService executorService() { if (executorService == null) { executorService = new ThreadPoolExecutor(0, Integer.MAX_VALUE, 60, TimeUnit.SECONDS, new SynchronousQueue<Runnable>(), Util.threadFactory("OkHttp Dispatcher", false)); } return executorService; }
,




