72节内容),对编码的概念、分类和作用,做过一个简单的介绍,今天的内容,还是从"编码"开始谈。
最早的字符串编码是ASCII码,是由美国国家标准学会(American National Standard Institute , ANSI )制定的,所以叫做"美国信息交换标准代码",它的内容是这样的:

ASCII码只包括以上四种字符内容,并且最多只能表示256个字符。
1967年ASCII第一次以规范标准的类型发表以来,到今天它已经走过了53年的风雨历程,作为一种国际通用的西文字符编码标准,它的作用的不可忽视的,但随着技术的发展,由于ASCII码自身的局限性,它已逐渐被后起之秀-万国码"utf-8"所取代。
而在汉语环境下,最适合的编码标准,应该是我国制定的"GBK"和"GB2312"。
在Python中,常用的字符串类型有str和bytes两种。
str表示Unicode字符,就是包括ASCII码、utf-8码、GBK码、GB2312码之类的编码;
bytes表示的则是二进制数据,其中包括了编码的文本。
我们知道,机器语言本质上就是0和1组成的二进制语言,所以str和bytes字符在不能拼接的情况下,它们之间的转换就非常必要了,因为在储存和传输的时候,是必须要将str字符类型转换为bytes字节类型的。
今天就来学习如何str和bytes类型之间转换的方法。
1、在Python中,提供了encode()方法来将str转换为bytes类型,通称"编码过程",它的语法格式是这样的:
str.encode(encoding="utf-8",errors="strict")
上面的str当然代表了要进行转换的字符;
方法关键字encode后面的小括号中可以包含两个可选参数,其间使用逗号","分隔;
第一个参数encoding="utf-8",用来指定转码的时候所采用的字符编码,省略时默认为utf-8,当只用这一个参数时,可以直接用引号引用编码;
第二个参数errors="strict",用来指定出错时的处理方式,省略时默认值为strict,而它的值分别是:strict=出现错误抛出异常、ignore=忽略错误、replace=使用"?"替换错误、xmlcharrefreplace=使用XML的字符引用。
谭嗣同就义时留下一首诗,其中两句:"我自横刀向天笑,去留肝胆两昆仑。",颇为大气磅礴!接下来就用这两句诗定义一个字符串,并分别采用"GBK"和"utf-8"编码转换为二进制编码输出,详见下图:
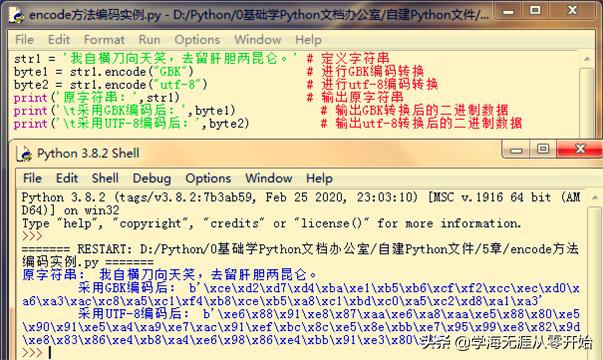
观察上面的结果,发现采用"utf-8"编码转换为二进制后要比采用"GBK"的长,这是因为,"GBK"编码中汉字占两个字节,"utf-8"编码中汉字占三个字节。
至于encode()方法的第二个参数,一般情况下使用默认值处理,现在就不赘述了。
2、使用decode()方法将二进制的bytes类型转换为str类型,通称"解码过程",它的语法格式下面这样的:
bytes.decode(encoding="utf-8",errors="strict")
可以看到,这个语法格式和参数和encode()方法的基本一致,事实上参数的内容也是一样的,因为这两种方法事实上就是一种相互逆转的过程,所以直接用代码实例就能说明,详见下图:

注意:在解码过程中采用的字符编码,要和编码过程中采用的字符编码保持一致。如同上面的实例一样,编码时采用"GBK",解码时依然采用"GBK",否则就会出现异常,详见下图:

在使用decode()方法时,还有一点要注意的是:原字符串不会被修改。如果想修改原字符串,只能通过重新赋值。
以上就是普通字符串和二进制编码之间互相转换的方法。各位朋友还能看的入眼吗?
感谢大家一直以来的支持,明天奉上的是"正则表达式"的内容,敬请拭目以待。
为自己加油,我是"学海无涯自学不惜!"
,




