缓存是用于解决高并发场景下系统的性能及稳定性问题的银弹。
本文主要是讨论我们经常使用的分布式缓存 Redis 在开发过程中的相关思考。
1. 如何将业务逻辑与缓存之间进行解耦?
大部分情况,大家都是把缓存操作和业务逻辑之间的代码交织在一起的,比如(代码一):
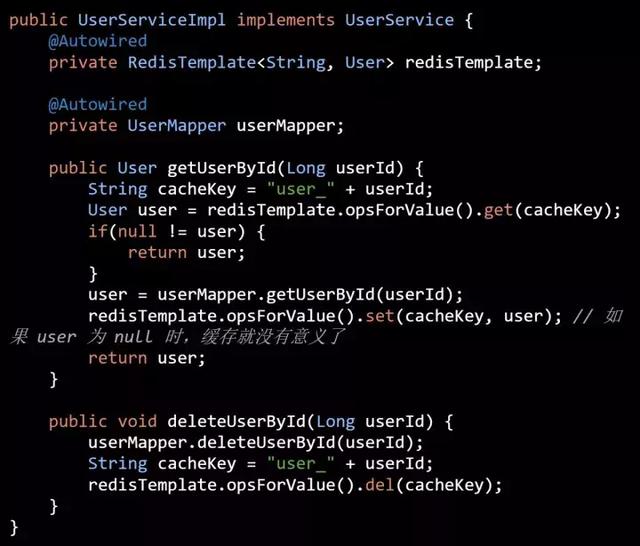
从上面的代码可以看出以下几个问题:
-
缓存操作非常繁琐,产生非常多的重复代码;
-
缓存操作与业务逻辑耦合度非常高,不利于后期的维护;
-
当业务数据为 null 时,无法确定是否已经缓存,会造成缓存无法命中;
-
开发阶段,为了排查问题,经常需要来回开关缓存功能,使用上面的代码是无法做到很方便地开关缓存功能;
-
当业务越来越复杂,使用缓存的地方越来越多时,很难定位哪些数据要进行主动删除;
-
如果不想用 Redis,换用别的缓存技术的话,那是多么痛苦的一件事。
因为高耦合带来的问题还很多,就不一一列举了。接下来以笔者开源的一个缓存管理框架 AutoLoadCache为例,看看我的设计是如何帮助我们来解决上述问题的。
AutoloadCache 在 AOP 拦截到请求后,大概的流程如下:
1 . 获取到拦截方法的 @Cache 注解,并生成缓存 key;
2 . 通过缓存 key,去缓存中获取数据;
3 . 如果缓存命中,执行如下流程:
-
如果需要自动加载,则把相关信息保存到自动加载队列中;
-
否则判断缓存是否即将过期,如果即将过期,则会发起异步刷新;
-
最后把数据返回给用户。
4 . 如果缓存没有命中,执行如下流程:
-
选举出一个 leader 回到数据源中去加载数据,加载到数据后通知其它请求从内存中获取数据(拿来主义机制);
-
leader 负责把数据写入缓存;如果需要自动加载,则把相关信息保存到自动加载队列中;
-
最后把数据返回给用户。
这里提到的异步刷新、自动加载、拿来主义机制,我们会在后面再说明。
2. 对缓存进行“包装”上面代码一的例子中,当从数据源获取的数据为 null 时,缓存就没有意义了,请求会回到数据源去获取数据。当请求量非常大的话,会造成数据源负载过高而宕机。
所以对于 null 的数据,需要做特殊处理,比如使用特殊字符串进行替换。而在 AutoloadCache 中使用了一个包装器对所有缓存数据进行包装(代码三):

在这上面的代码中,除了封装缓存数据外,还封装了数据加载时间和缓存时长,通过这两项数据,很容易判断缓存是否即将过期或者已经过期。
3. 如何提升缓存 key 生成表达式性能?使用 Annotation 解决缓存与业务之间的耦合后,我们最主要的工作就是如何来设计缓存 key 了,缓存 key 设计的粒度越小,缓存的复用性也就越好。
上面例子中我们是使用 Spring EL 表达式来生成缓存 key,有些人估计会担心 Spring EL 表达式的性能不好,或者不想用 Spring 的情况该怎么办?
框架中为了满足这些需求,支持扩展表达式解析器:继承 com.jarvis.cache.script. AbstractScriptParser 后就可以任你扩展。
框架现在除了支持 Spring EL 表达式外,还支持 Ognl、javascript 表达式。对于性能要求非常高的人,可以使用 Ognl,它的性能非常接近原生代码。
4. 如何解决缓存 key 冲突问题?在实际情况中,可能有多个模块共用一个 Redis 服务器或是一个 Redis 集群的情况,那么有可能造成缓存 key 冲突了。
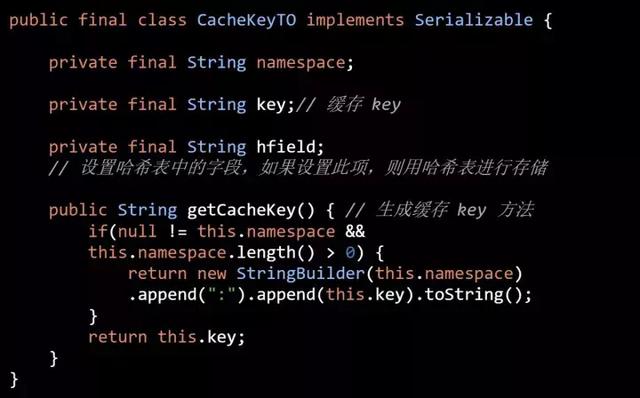
为了解决这个问题 AutoLoadCache,增加了 namespace。如果设置了 namespace 就会在每个缓存 key 最前面增加 namespace(代码四):
我们希望缓存数据包越小越好,能减少内存占用,以及减轻带宽压力;同时也要考虑序列化与反序列化的性能。
AutoLoadCache 为了满足不同用户的需要,已经实现了基于 JDK、Hessian、JacksonJSON、Fastjson、JacksonMsgpack 等技术序列化及反序列工具。也可以通过实现 com.jarvis.cache.serializer.ISerializer 接口自行扩展。
JDK 自带的序列化与反序列化工具产生的数据包非常大,而且性能也非常差,不建议大家使用;JacksonJson 和 Fastjson 是基于 JSON 的,所有用到缓存的函数的参数及返回值都必须是具体类型的,不能是不确定类型的(不能是 Object, List<?>等),另外有些数据转成 JSON 时其一些属性是会被忽略,存在这种情况时,也不能使用 JSON;而 Hessian 则是非常不错的选择,非常成熟和稳定性。阿里的 dubbo 和 HSF 两个 RPC 框架都是使用了 Hessian 进行序列化和返序列化。
1、具有1-5工作经验的,面对目前流行的技术不知从何下手,需要突破技术瓶颈的可以加群。
2、在公司待久了,过得很安逸,但跳槽时面试碰壁。需要在短时间内进修、跳槽拿高薪的可以加群。
3、如果没有工作经验,但基础非常扎实,对java工作机制,常用设计思想,常用java开发框架掌握熟练的,可以加群。
4、觉得自己很牛B,一般需求都能搞定。但是所学的知识点没有系统化,很难在技术领域继续突破的可以加群。
5. 群号:高级架构群 651013434备注好信息!
6.阿里Java高级架构师免费直播讲解知识点,分享知识,多年工作经验的梳理和总结,带着大家全面、科学地建立自己的技术体系和技术认知!
6. 如何减少回源并发数?当缓存未命中时,都需要回到数据源去取数据,如果这时有多个并发来请求相同一个数据(即相同缓存 key 请求),都回到数据源加载数据,并写缓存,造成资源极大的浪费,也可能造成数据源负载过高而无法服务。
AutoLoadCache 使用 拿来主义机制 和 自动加载机制 来解决这个问题:
拿来主义机制
拿来主交机制,指的是当有多个用户请求同一个数据时,会选举出一个 leader 去数据源加载数据,其它用户则等待其拿到的数据。并由 leader 将数据写入缓存。
自动加载机制
自动加载机制,将用户请求及缓存时间等信息放到一个队列中,后台使用线程池定期扫这个队列,发现缓存即将过期,则去数据源加载最新的数据放到缓存中,达到将数据长驻内存的效果。从而将这些数据的请求,全部引向了缓存,而不会回到数据源去获取数据。这非常适合用于缓存使用非常频繁的数据,以及非常耗时的数据。
为了防止自动加载队列过大,设置了容量限制;同时会将超过一定时间没有用户请求的数据从自动加载队列中移除,把服务器资源释放出来,给真正需要的请求。
往缓存里写数据的性能相比读的性能差非常多,通过上面两种机制,可以减少写缓存的并发,提升缓存服务能力。
7. 异步刷新AutoLoadCache 从缓存中获取到数据后,借助上面提到的 CacheWrapper,能很方便地判断缓存是否即将过期, 如果即将过期,则会把发起异步刷新请求。
使用异步刷新的目的是提前将数据缓存起来,避免缓存失效后,大量请求穿透到数据源。
8. 多种缓存操作大部分情况下,我们都是对缓存进行读与写操作,可有时,我们只需要从缓存中读取数据,或者只写数据,那么可以通过 @Cache 的 opType 指定缓存操作类型。现支持以下几种操作类型:
READ_WRITE:读写缓存操,如果缓存中有数据,则使用缓存中的数据,如果缓存中没有数据,则加载数据,并写入缓存。默认是 READ_WRITE;
WRITE:从数据源中加载最新的数据,并写入缓存。对数据源和缓存数据进行同步;
READ_ONLY: 只从缓存中读取,并不会去数据源加载数据。用于异地读写缓存的场景;
LOAD:只从数据源加载数据,不读取缓存中的数据,也不写入缓存。
另外在 @Cache 中只能静态指写缓存操作类型,如果想在运行时调整操作类型,需要通过 CacheHelper.setCacheOpType() 方法来进行调整。
9. 批量删除缓存很多时候,数据查询条件是比较复杂的,我们无法获取或还原要删除的缓存 key。
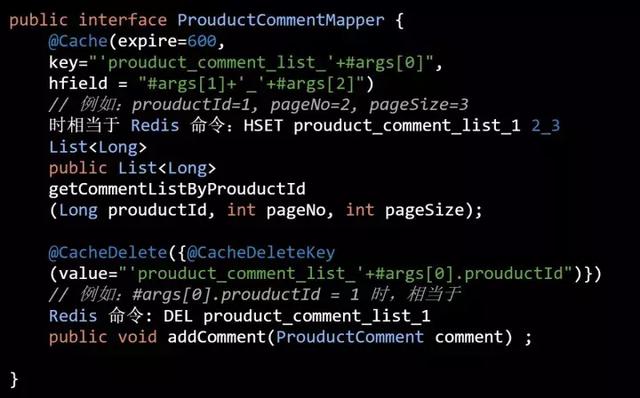
AutoLoadCache 为了解决这个问题,使用 Redis 的 hash 表来管理这部分的缓存。把需要批量删除的缓存放在同一个 hash 表中,如果需要需要批量删除这些缓存时,直接把这个 hash 表删除即可。这时只要设计合理粒度的缓存 key 即可。
通过 @Cache 的 hfield 设置 hash 表的 key。
我们举个商品评论的场景(代码五):
如果添加评论时,我们只需要主动删除前 3 页的评论(代码六):
10. 双写不一致问题
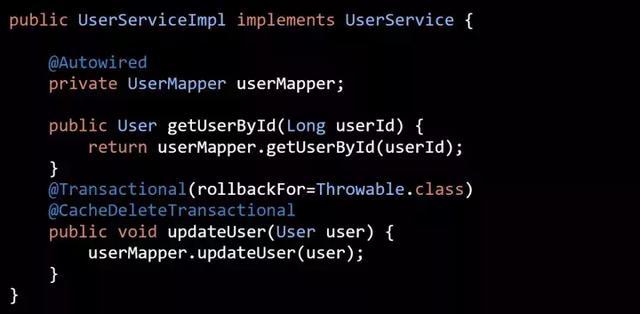
在代码二中使用 updateUser 方法更新用户信息时, 同时会主动删除缓存中的数据。 如果在事务还没提交之前又有一个请求去加载用户数据,这时就会把数据库中旧数据缓存起来,在下次主动删除缓存或缓存过期之前的这一段时间内,缓存中的数据与数据库中的数据是不一致的。
AutoloadCache 框架为了解决这个问题,引入了一个新的注解:@CacheDeleteTransactional (代码七):
使用 @CacheDeleteTransactional 注解后,AutoloadCache 会先使用 ThreadLocal 缓存要删除缓存 key,等事务提交后再去执行缓存删除操作。其实不能说是“解决不一致问题”,而是 缓解 而已。
缓存数据双写不一致的问题是很难解决的,即使我们只用数据库(单写的情况)也会存在数据不一致的情况(当从数据库中取数据时,同时又被更新了),我们只能是减少不一致情况的发生。对于一些比较重要的数据,我们不能直接使用缓存中的数据进行计算并回写的数据库中,比如扣库存,需要对数据增加版本信息,并通过乐观锁等技术来避免数据不一致问题。
11. 与 Spring Cache 的比较AutoLoadCache 的思想其实是源自 Spring Cache,都是使用 AOP Annotation ,将缓存与业务逻辑进行解耦。区别在于:
1 . AutoLoadCache 的 AOP 不限于 Spring 中的 AOP 技术,即可以脱离 Spring 生态使用,比如成功案例 nutz
https://github.com/nutzam/nutzmore/tree/master/nutz-integration-autoloadcache
2 . Spring Cache 不支持命名空间;
3 . Spring Cache 没有自动加载、异步刷新、拿来主义机制;
4 . Spring Cache 使用 name 和 key 的来管理缓存(即通过 name 和 key 就可以操作具体缓存了),而 AutoLoadCache 使用的是 namespace key hfield 来管理缓存,同时每个缓存都可以指定缓存时间(expire)。也就是说 Spring Cache 比较适合用来管理 Ehcache 的缓存,而 AutoLoadCache 更加适合管理 Redis,Memcache,尤其是 Redis,hfield 相关的功能都是针对它们进行开发的(因为 Memcache 不支持 hash 表,所以没办法使用 hfield 相关的功能)。
5 . Spring Cache 不能针对每个缓存 key,进行设置缓存过期时间。而在缓存管理应用中,不同的缓存其缓存时间要尽量设置为不同的。如果都相同的,那缓存同时失效的可能性会比较大些,这样穿透到数据库的可能性也就更大了,对系统的稳定性是没有好处的;
6 . Spring Cache 最大的缺点就是无法使用 Spring EL 表达式来动态生成 Cache name,而且 Cache name 是的必须在 Spring 配置时指定几个,非常不方便使用。尤其想在 Redis 中想精确清除一批缓存,是无法实现的,可能会误删除我们不希望被删除的缓存;
7 . Spring Cache 只能基于 Spring 中的 AOP 及 Spring EL 表达式来使用,而 AutoloadCache 可以根据使用者的实际情况进行扩展;
8 . AutoLoadCache 中使用 @CacheDeleteTransactional 来减少双写不一致问题,而 Spring Cache 没有相应的解决方案;
,