
最近的研究表明,显式深度特征匹配以及大规模多样化的训练数据均可显著提升行人重识别的泛化能力。但是,在大规模数据上,学习深度匹配器的效率还未得到充分研究。

近日,特斯联科技集团首席科学家邵岭博士及团队提出了一种高效的小批量采样(mini-batch sampling)方法——图采样(Graph Sampling, GS),用于大规模深度度量学习,极大改善了可泛化行人重识别。目前,该研究成果(题为: Graph Sampling Based Deep Metric Learning for Generalizable Person Re-Identification)已被今年的 CVPR 接受并发表。
可泛化行人重识别引关注,大规模深度度量学习效率尚存提升空间
行人重识别是一项热门的计算机视觉任务,其目标是通过对大量图库图像进行检索,以便找出给定的查询图像中的行人。在过去的两年中,可泛化行人重识别因其研究和实用价值而受到越来越多的关注。这类研究探索学习行人重识别模型对于未见过的场景的可泛化性,并采用了直接的跨数据集评估来进行性能基准测试。
目前较热门的深度学习行人重识别模型的方法包括分类(使用ID loss)、度量学习(使用pairwise loss或 triplet loss),以及它们的组合(例如ID triplet loss)。ID损失函数对于分类学习来说十分便捷。然而,在大规模的深度学习中,涉及分类器参数会在前向和反向传播过程中产生大量的内存和计算成本。相似地,在全局视图中涉及用于度量学习的类别相关参数也效率不高。

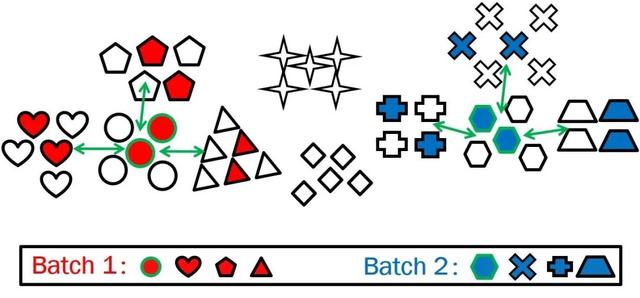
图1:两种不同的采样方法:(左侧)PK采样器;(右侧)邵岭博士团队提出的GS采样器。不同的形状表示不同的类别,而不同的颜色则表示不同的批次(batches)。GS为所有的类别构建一个图,并且总是对最近的相邻类别进行采样
因此,对于大规模的行人重识别训练来说,在分类或是度量学习中涉及类别参数或是特征并不高效。相比之下,团队认为小批量中的样本两两之间的深度度量学习更加合适。因此,批量采样器对高效学习起着重要作用。著名的PK采样器是行人重识别中最热门的随机采样方法。它首先随机选择P个类别,然后对每个类别随机抽取K张图像,以构建一个大小为B = P × K的小批量。由于这是随机进行的,小批量内的采样实例均匀分布于整个数据集中(见图1(左)),因此,对于深度度量学习来说,其可能并非信息丰富且有效的。为了解决这个问题,一种在线困难样本挖掘(online hard example mining)方法,在一定程度上提高了学习效率。然而,挖掘是在已经采样的小批量上在线进行的。因此,这种方法仍然受到完全随机PK取样器的限制——这种采样器得到的小批量不考虑样本关系信息。
为解决上述问题,团队建议将困难样本挖掘工作前移到数据采样阶段之前。因此,团队提出了一种高效的小批量采样方法,称为图采样(GS),用于大规模深度度量学习。其基本思想是在每个epoch开始时为所有的类别构建一个最近邻关系图。然后,通过随机选择一个类别作为锚点(anchor),同时选择其前k个最近邻类别来执行小批量采样,每个类别拥有相同K个实例,具体如图1(右)所示。通过这种方式,小批量采样中的实例大多彼此相似,从而为判别式学习提供了信息量大且具有挑战性的实例。
团队公布了其图采样细节。在每个传播(epoch)开始时,利用最新学习的模型来评估类别之间的距离或相似度,然后为所有的类别构建一个图。这样一来,类别之间的关系就可以用来进行信息充足的采样。具体来说,图采样为每个类别随机选择一张图片来构建一个小的子数据集(sub-dataset)。然后,提取当前网络的特征嵌入,表示为X ∈ RC×d,其中C是训练的总类别数,d是特征维度。接下来,通过查询自适应卷积(QAConv)之类的方法计算所有选定的样本两两之间的距离。结果,得到一个所有类别的距离矩阵dist∈ RC×C。
随即,对于每个类别c,可以检索出前P - 1个最近的相邻类别,用N(c) = {xi|i= 1,2,...,P− 1}表示,其中P是每个小批量中应采样的类别数量。因此,可以构建一个图G = (V,E),其中V = {c|c= 1,2,...,C} 代表顶点,每个类别作为一个节点,E= {(c1,c2)|c2 ∈ N(c1)} 代表边。
最后,对于小批量采样,对于每个作为锚点的类别c,我们检索其在G中的所有连接的类别。然后连同锚点类别c, 可得到一个集合A= {c}∪{x|(c,x) ∈ E}, 其中 |A| = P. 接下来,对于A中的每个类别,我们对每个类别随机采样K个实例,产生一个B= P× K的小批量样本用于训练。
需要注意的是,与其他小批量采样方法不同的是,对于GS采样器来说,每一次传播中,小批量数量或迭代次数总是C,这与参数B、P和K无关。尽管如此,参数B仍然影响每个小批量的计算量。此外,人们可能会担心GS采样器的计算量大,但需要注意的是,第一,每类别只有一个图像被随机抽样用于图的构建;第二,上述计算每个epoch只执行一次。在实践中,我们发现GS采样器配上查询自适应卷积(QAConv),尽管与主流的欧氏距离相比,算得上是计算量大的匹配器,但处理数千个的身份时,仅需几十秒。
实验结果优于传统方法,图采样提升大规模深度度量学习的学习效率
团队亦分享了其实验结果,并对最近发表的几种可泛化行人重识别方法进行了比较,其中包括OSNet-IBN、OSNet-AIN、MuDeep、SNR、QAConv、CBN、ADIN和M3L,结论由表1可得,QAConv-GS明显优化了之前的最佳成绩。例如,在Market-1501→CUHK03的情况下,Rank-1和平均精度均值(mAP)分别提高了8.8%和9.0%。在Market-1501→MSMT17的情况下, 数据分别提高了20.6%和7.7%。在MSMT17(全部)→Market-1501的情况下,数据分别提高了9.8%和13.8%。使用RandPerson作为训练数据,在Market-1501测试得出的Rank-1提高了12%,而mAP提高了7.4%,而在MSMT17测试,数据分别提升了25.1%和8.7%。虽然RandPerson是合成的,但结果表明,用其学习的模型可以良好地泛化到真实世界的数据集。
M3L使用了不同的测试协议,因此结果不具有直接可比性。具体来说,M3L在选自CUHK03、Market-1501、DukeMTMC-reID1和MSMT17的三个数据集上进行训练,而剩余的一个数据集则被用于测试。M3L在CUHK03-NP上取得了令人印象深刻的结果,虽然没有直接的可比性,但超过了团队-0006所有的结果,包括用所有MSMT17图像训练的结果。然而,团队提出的方法在MSMT17上训练后,在Market-1501中测试出的Rank-1比M3L的结果高出3.2%,二者mAPs数值则是相当的。此外,团队提出的方法在Market-1501上训练后,在MSMT17中测试出的结果明显优于M3L,Rank-1高出9%,mAP高出2.5%。

表1.直接跨库测试结果最优成绩的比较(%)。MSMT17(all)意味着所有图像都被用于训练,不考虑子集的划分。M3L在选自CUHK03、Market-1501、DukeMTMC-reID和MSMT17的三个数据集上进行训练,而剩余的一个数据集则被用于测试。灰色单元格中的结果是用数据集内(within-dataset)的测试作为参考。“-” 表示未报告或不适用。

表2. QAConv变体的比较。Ori:原始QAConv[17]。Base:团队改编的竞争性基线。GS:图采样(我们所提出)。MS-all:MSMT17(全部)。RP:RandPerson。
通过前述研究,团队证明了热门的PK采样器在深度度量学习中并不高效,因而提出了一种新的批量采样器,称为图采样器(GS),以帮助更有效地学习判别模型,通过构建所有类别的近邻图来进行信息采样,团队成功验证了所提出的方案。同时,借助有竞争性的基线,团队在可泛化行人重识别领域获得了最优成绩,显著改善了其性能。同时,通过去除分类参数,并且仅使用小批量中样本的两两之间的距离来计算损失,训练时间得到大大缩减。在特斯联看来,团队提出的技术尤其具备通用性,其同样可应用于包含图像检索等在内的其他领域。






