
来源:科技新报(台) 作者:痴汉水球
相信各位一直会有相同疑惑:为何今天的x86 处理器市场,台面上只剩下英特尔和AMD 两家美国公司?顶多再加个存在感稀薄的台湾VIA,和少人知悉的俄罗斯Elbrus?对技术有点基础认知的人,多少会直接想到「x86 指令集很复杂很难搞,又有英特尔的授权问题,所以x86 处理器非常不好做」之类的标准答案。
当然,更不乏某些夜郎自大的高论,像「就算x86 指令集再复杂,控制单元也还是很好设计」、「微指令转译早就克服了所有x86 指令集的瓶颈」等。拜托,「做出勉强能动的东西」和「开发出有市场竞争力的产品」完全是天差地别的两件事,要不然你以为英特尔和AMD 天文数字般的产品开发经费,都拿去填海了吗?
总之,高效能x86 处理器之所以难做,混杂了诸多技术和商业因素,暗藏在台面下的细节非外人足以道也。但我们可以回到x86 处理器最重要的历史转捩点:1993年Pentium 处理器,抽丝剥茧一般人难以察觉到的蛛丝马迹。
以「唯偏执狂得以生存」(Only theParanoid Survive)留名于世的英特尔创办人之一安迪·葛洛夫(Andy Grove) 曾经说,2003 年的Centrino 是英特尔的「第二个儿子」与「十年来最重要的品牌」 ,那「第一个儿子」和「十年前最重要的品牌」,想当然尔就是1993 年的Pentium 了。
Pentium 之名起源于希腊文的Penta(意思是「五」),再加上拉丁文的ium 结尾,意指「第五代x86 处理器」,英特尔自此也不再使用80×86 来定义处理器世代(要不然现在还真的讲不出来到底是「几86」)。而Pentium 也在不知不觉中,一步步转型为入门级低价处理器品牌,更不再受限于1993 年的P5,进而横跨历代英特尔的超标量(Superscalar)x86 微架构。
原始Pentium 里的P5 处理器微架构,并没有像后继Pentium Pro 的P6 活得如此之长,影响又如此深远(到2011 年Sandy Bridge 才结束)。但Pentium 问世的时机,却是众多历史机运的集大成:
-
「x86 处理器走向高效能化」。
-
「x86 开始与RISC 正面竞争」。
-
「x86 指令集的缺陷让厂商感到棘手」。
-
「x86 处理器进军多处理器平台」。
-
「个人电脑市场因Windows 95 的问世而蓬勃成长」。
-
「笔记本电脑即将逐渐普及」。
-
「英特尔默默埋下让擅长改良的以色列海法研发团队,主导x86 处理器技术发展」。
-
「x86指令集的兼容性,成为其他竞争者的潜在障碍,也造成软件开发商的困扰」。
这些因素交错,奠定了之后25 年技术演进与市场发展的基础逻辑,连时下「AMD 处理器的核心太多,竟然造成Windows 操作系统的大麻烦」,也和Pentium 留下的遗产,多少有些千丝万缕的纠结。
既然连AMD Zen成功的背后,都有这么多不为人知的故事,了解英特尔「Landmark」芯片Pentium的轨迹,将有助跳脱琳琅满目的技术营销名词,重新建立属于自己的「x86处理器世界观」,值得各位细细品味。
x86 指令集先天不足后天失调的原罪
催生「计算机结构」(ComputerArchitecture)一词的「指令集架构」(Instruction Set Architecture),为「电脑的基础语言」与「软硬件中间的接口」(Interface Between Hardware and Software),相同指令集的电脑理应可执行一样软件,具备彼此兼容性,对电脑与处理器微架构(Microarchitecture)的未来发展有举足轻重的影响力。
不同的时空背景,也会产生相异的指令集设计理念,没有绝对的优劣对错──x86算是少见的例外,另一个则是DEC VAX,两者的共同点只有「着毋庸议」的糟糕,英特尔IA-64(Itanium)和DEC Alpha的激烈反动,足以证明连生父都如此厌恶小孩。

说到指令集架构如何影响处理器微架构的设计,这几年来最有名的实例,就是苹果利用充分掌握封闭平台的优势在「最短时间内驱逐32位元应用程序」,掌握ARM指令集迈向64位元的过程带来的改革与机会,让A7之后的自家ARM处理器,彻底为64位元的ARMv8-A量身订做,研发出一系列能同时有效处理更多指令的先进微架构。
所谓的CISC(复杂指令集电脑)出自存储器容量稀少、缺乏成熟的高级语言编译器、大多数人使用语言撰写程序的时空背景,程序设计者寄望直接用透过微码(Microcode)组成功能强大的单一指令,像十进位数字和复杂字串处理等,撰写应用程序。
相较之下,RISC(精简指令集电脑)则是在「万事皆备」的环境,追求更快更便宜的电脑,将晶体管预算砸在「最经常被使用的简单指令和运算元定址模式」的刀口上,尽量用硬件线路去取代微码,并藉由强制仅载入(Load)/储存(Store)指令可存取存储器,搭配大型化的数据寄存器与快取存储器,填补处理器和存储器之间越来越大的效率鸿沟。

时过境迁,在x86 主宰云端数据中心、中低端服务器、工作站、桌面机一路到笔电的今日,可能已经没有多少人能回想起「RISC 与CISC 之争」曾发生在1990 年代初期的史迹,但毕竟x86 指令集公认是充满缺陷的产物,连当代最伟大的计算机结构教科书都「白纸黑字」并「烧录」于无数莘莘学子的脑中,而AMD K5 的创造者更是用一句「毫无道理可循」(it just doesn'tmake a lot of sense)一锤定音,几无争议空间。
让人满脸黑线的,只有动辄挥出「逆向思考全垒打」的大恩大德,将x86 的市场胜利,视为「x86 指令集架构优良」佐证的天真论点,并时有所闻,连ARM 都比x86 更「存储器存取密集」(Memory-Intensive)这种话都讲得出口。
我们先来瞧瞧当年AMD K5 的总工程师Mike Johnson 怎么评论x86 指令集,由设计x86 处理器的大师级人物(他本人的确是超标量流水线技术的先驱者,那份变成首本超标量技术专书的史丹佛大学博士论文非常有名,附录更深度分析设计超标量x86 处理器的困难点)写出来的批评,特别有说服力,也一再被后人引述:
The complexity of the x86 is not animpassable barrier. The x86 really isn't all that complex—it just doesn't make a lotof sense…. The biggest weakness in the x86 instructionset is the lack of registers coupled with an extremely painful addressingscheme.

从这短短一段话,可看到几个重点:
「毫无道理可循」(doesn't make a lotof sense):相较于指令编码程度统──4 Bytes(32 bits)的多数RISC体系,x86指令集的格式和编码极度混乱,长短粗细肥瘦不一,从1~17 Bytes都有可能。影响所及,遍及所有的环节,从快取存储器撷取指令、实作指令流水线化,到处理器发生中断例外时要迅速储存执行状态并尽快回复等,都造成非常严重的后遗症,激增研制高效能x86处理器的门槛,也增加验证产品的时间与成本。
「缺乏足够的寄存器」(the lack ofregisters):一般RISC指令集都会定义32个通用数据寄存器(讲的精确一点是31个)或浮点运算寄存器,但x86在64位元和AVX之前,怎么样都只有少少的8个(因为要扣掉ESP和EBP,说6个或许比较贴切)。当引进指令流水线化和更先进的超标量流水线后,自然就激增了寄存器冲突的机率,这也是激发x86处理器拥有强大非循序指令执行(寄存器重新更名)与高效率存储器子系统的主因。

「让人感到极度痛苦的定址模式」(extremelypainful addressing scheme):定址模式讲得白话一点是「存取所需运算元(运算的目标,例如某个寄存器或某个存储器位址)的方式」,历经多年叠床架屋的x86定址模式,尤其是恶名昭彰的节区存储器(Segmentation),不只加重产生有效位址的工作负荷,也激增整数逻辑运算(ALU)和控制单元的复杂度,「副作用」跟第一项「毫无道理可寻」可谓不相上下。

这些烫手山竽,就是1980 年代末期和1990 年代初期,众多企图研制高效能x86 处理器的有志之士,包含不小心制造出这些「炸弹」的英特尔,不得不面对并设法克服的挑战,身为x86 世界首颗「超标量(Superscalar)流水线」处理器的Pentium,则是第一个提出的「有效解决方案」,英特尔为此付出了不小代价。
一个时钟周期执行一个以上指令的「超标量流水线」
近似近代工业生产线的概念,让所有人都「闲闲有事做」的流水线化(Pipeline)一直是提高效率的最基本手段,80386 的预先指令撷取(Prefetch)已有雏型,而80486 是x86世界首款真正达成指令流水线化的处理器,为了确保存储器跟得上运算需求,也配置指令/数据共用的第一阶快取存储器,虽然真正「每个时钟周期都可稳定输出」者,也只限于简单的整数逻辑运算指令。

「一个时钟周期内执行一个以上指令」的超标量流水线(Superscalar),早在1965 年发迹于RISC 始祖的CDC6600,1980年代陆续出现在RISC 处理器,如1985 年Power 前身的IBM「America」计划(也是「超标量」一词由来)、1988 年Motorola MC88100、1989 年英特尔i960CA、1990年AMD 29050 等。各位绝对没看错,英特尔、AMD 也做过RISC 处理器。
指令流水线化、超标量流水线、非循序指令执行、大型化快取存储器等常见的效能加速手段,清一色优先降临RISC 处理器的原因,也很简单:RISC 指令集的单纯性与简洁性,让设计者更轻易导入这些技术,并用更短的时间完成产品开发与验证。
1990 年代上半期,一提到高效能处理器,几乎都由RISC 独领风骚,像至今硕果仅存的IBM Power、HP 的PA-RISC、SGI 的MIPS、Sun 的UltraSPARC、Fujitsu 的SPARC64及充满传奇色彩的DEC Alpha 等,这也是「RISC 优于CISC」的理论基础。
但「理论」是一回事,不代表CISC 的x86「实务上」做不到,更何况又是拥有一整支庞大「研发军队」的英特尔,革命性的第五世代x86处理器Pentium 在1993年3 月22 日登上历史舞台,不只要迎击来自AMD、Cyrix、NexGen(被AMD 购并,Nx686 变成K6)的竞争产品(之后还多出Centaur 和Transmeta),更要面对AIM 联盟(Apple、 IBM、Mororola,不是美国的空对空飞弹)PowerPC 的挑战,后者享有威镇四方的「RISC 王者」IBM Power 当强大后盾,市面更不乏「专书」鼓吹PowerPC 相对x86 的优越性,把Pentium批评得一文不值。

更扯的是,意图抢夺英特尔势力范围的IBM 还开发了「脚位与Pentium 兼容,可以同等效率硬件执行x86 程序码,并兼具32 / 64 位元PowerPC 指令集兼容性」的PowerPC 615,要不是微软可能觉得难搞,不符成本效益,拒绝支持这颗处理器,导致永远无法量产,英特尔的处境会更危险。至于PowerPC 615 取消后,研发团队就投靠Transmeta,接着就无疾而终了。
也许各位难以想像「为什么x86 会受PowerPC 威胁,不是属于不同市场吗」,但此时此刻,没半个正常人会将连服务器市场边都沾不上的x86 和「高效能」三个字联想在一起,甚至连那时候英特尔内部,都很少人愿意相信x86 还有未来性,否则也不会出现IA-64 指令集和Itanium 处理器了。况且微软1993 年7 月发表未来操作系统基础的WindowsNT,打从一开始就同时支持x86、MIPS 和Alpha 三版本,之后还加码PowerPC 和IA-64,「不将鸡蛋放在同一个篮子里」意图太明显了。
换句话说,英特尔当时的战略地位,并不像今天如此牢不可破,更早在1990 年同步启动第六世代Pentium Pro 研发案,完全没有承受失败的本钱与余裕。
天底下没有白吃的午餐
Pentium 是如假包换的x86 世界首款超标量处理器,可在同一个时钟周期内执行最多两个指令,整体结构近似双重流水线的「放大发展版」80486,但也因扛着x86指令集的原罪,由外到内付出了不少代价。爬文至此,建议各位回头复习一次Mike Johnson 评论的3 个重点,你一定会更有感触。

我们光从初代Pentium(P5)的晶粒图,即可清楚看到x86 兼容性的代价:大型化的快取存储器(尽管实质容量不高,但内部结构却出奇复杂)、巨大的指令撷取单元、解码与复杂指令微码控制单元(Complex Instruction Support),这也是日后所有高效能x86 处理器的共同特色。

指令/数据分而治之的第一阶快取存储器:x86指令集因缺乏足够的数据寄存器,且包含了大量「寄存器/存储器互通有无」与直接以存储器为运算目标的指令,不像RISC的「载入/储存」架构「一次从存储器抓了大量数据进来,算完后再一次性丢回存储器」,特别需要强力的存储器子系统,所以采用指令/数据分开的第一阶快取存储器,确保两边足以喂饱个别的需求。而Pentium的指令快取和数据快取,更是各自大有文章。
前面有提及「x86 指令最大长度是17Bytes」,Pentium 第一阶指令快取的内部结构,是以两个最小存取单位16Bytes 区块,组成单一32Bytes 的快取线(Cache-Line),假若发生最糟糕的情况,17Bytes 长度的指令「横跨」了两条32Bytes 快取线,但仍希望一次撷取到指令流水线,那该怎么办?Pentium 导入跨指令线分离式撷取(Split Fetch),可连续读取横跨边界的两条16Bytes 最小区块,而指令读取缓冲区也是4 倍于80486 的128Bytes,以确保撷取指令的效率可「喂饱」两条流水线的指令解码器。

顺便对照一下从NexGen Nx686 发展而来的AMD K6。AMD 取消了两倍核心时钟频率的第一阶快取存储器,但除了既有的预先解码位元(Pre-decoded Bits)用来标定指令边界,再追加第二个指令存取埠,以应付这种状况。反正各家厂商都各显神通,直到可降低指令解码器使用率的微指令快取(uOp cache)同时成为英特尔和AMD 的制式武装为止。
数据快取亦不遑多让,数据快取具备3 个存取埠,可同时应付来自快取数据一致性协定与双重执行流水线的需要,更进一步将每条32Bytes 快取线,切成彼此交错的8 个独立4Bytes「Bank」,只要两个数据存取需求不会同时使用同一个Bank,即可在单一时钟周期内搞定。这是计算机工业史上的第一次尝试,但这也大幅加重了快取存储器的复杂度,也连带不得不强化配置数据快取的虚拟/实体位址转换缓冲区(TLB,Translation-Lookaside Buffer ),并新增判断Bank 是否发生冲突的功能电路。
巨大的微程序只读存储器:基于「加速常用的简单指令」的理念,Pentium 的指令解码器可直接硬体解码大多数「寄存器→存储器」与「存储器→寄存器」之类的「相对简单」运算指令,但 x86 历代累积下来的庞大复杂指令,还是需要动用微码组成微程序产生控制讯号。
Pentium 的单一微码字元长度是 92Bits,总共存放了 4K 数量。换言之,产生了高达 47kB 容量的只读存储器(ROM)空间,还远多于第一级快取记忆体的容量(8kB+8kB),相当惊人,老旧指令兼容性带来的巨大负担,由此可见一斑,这就是维持回溯兼容性,所必须付出的昂贵代价。
4 个输入的位址计算单元:一套所谓「复杂」的指令集,除了不规则的指令编码长度,乱无章法的运算元定址模式和存储器定址,更是必备的条件(可回顾一下 AMD Mike Johnson 讲过的话)。实现高效能的超标量流水线 x86 处理器,并非只需弄好流水线前端的指令撷取、解码,与执行阶段的存取存储器,高效率的有效位址计算(Address Calculation)能力,更是 x86 有别于 RISC 体系的一大差异点,坊间人云亦云、积非成是的「x86 处理器只有指令解码器比较难做」完全是大错特错的误解。
为了加速存储器位址计算,让执行单位尽快得到「运算目标」,Pentium 的两条指令流水线个别有一套 4 个输入值的加法器(4-Input Address Adder),对应 x86 指令集产生有效位址的 4 个数字:
节区描述器(Segment Descriptor)提供的基底值(Base)。
来自通用寄存器的基底位址(Base Address)。
取自通用寄存器的索引值(Index,再加上scale)。
指令编码附上的的移位值(Displacement)。
因此部分仅支持 3 个输出值的 486,需耗费两个时钟周期完成位址计算的复杂指令,Pentium 只需一个时钟周期週期即可,更利于流水线化执行指令。

但惨剧尚未划下句点,x86 的节区存储器(Segment),必须强制检验每个节区的大小,确保存储器运算元落在节区描述器所定义的存储器范围内。80286 时代的保护模式,节区描述器会影响节区位置与体积的参数,总计有:
-
32 位元基底值(Base)。
-
20 位元范围值(Limit)。
-
范围值单位Page 或Byte(前者上限4GB,后者则1MB)。
-
针对堆叠(Stack)数据结构的向下扩展(Expand-Down)栏位。
处理器需采取不同的方式计算最高与最低位址,结果Pentium的两条指令流水线,为此个别又得「再」加上一套4 个输入值的加法器(4-Input Segment-Check Adder) ,为检查节区正确性之用,而486的情况如上述位址产生器,须耗费更多时钟周期做这件事。

为何「位址计算单元」一向是历代x86 处理器增加执行单元的重头戏,原因就在此。Windows 95 刺激个人电脑普及的年代,「32 位元最佳化」的Pentium Pro 被批评「16 位元效能不佳」就因动到数据节区寄存器的指令,无法被非循序预测执行,会让随后的指令上演大塞车,到了Pentium II 才修正。即使假以时日,这些老旧包袱的使用率只会越来越低,也早不再是改善效能的重点,但也没人胆敢冒着牺牲软件兼容性的风险,根除这些历史遗迹。

正面对决PowerPC 且落居下风
相较于同时期且较早推出的超标量RISC 处理器,就可明显看出x86 指令集的复杂度造成的负面影响。
以1993 年秋季上市的IBM PowerPC 601 为例,晶体管数目仅280 万,采用0.6um(600nm)制程时的晶粒面积仅121 平方公厘,却有比晶体管310 万的Pentium 更高的80MHz时钟频率、更大一倍的32kB 指令/数据共用式第一阶快取存储器,与1.5 倍的指令执行能力,而采用0.8um(800nm)制程的初代Pentium是一颗16.7×17.6mm、294平方公厘的巨大芯片,完全瞠乎其后。英特尔当时就表示,相较于同等级RISC 处理器,Pentium 有约30% 晶体管都「贡献」给x86 指令集的兼容性。不难想见那时候的「RISC 十字军」有多high。
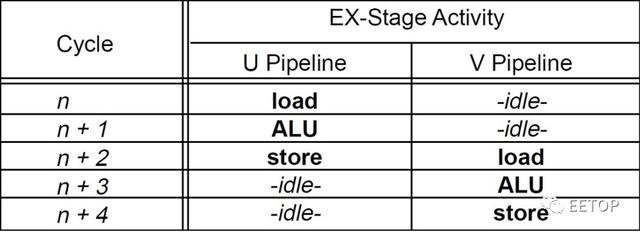
而Pentium 的双重超标量指令流水线也是限制重重,只有主流水线「U Pipe」可以执行所有的x86 指令,副流水线「V Pipe」仅能负责比较简单者,而要这两条流水线一起动,还需要依循指令配对规则,讲白了就是「两边都要跑简单指令」,且涉及寄存器和存储器两边数据互相搬移的指令也无能为力,就是要强迫其中一条流水线「发呆」两个时钟周期给你看。PowerPC 601「理所当然」比较没有这样的烦恼。
80×87 浮点指令集更是x86 处理器追求高效能浮点运算的罩门,因「英特尔内部沟通不良」(英特尔美国加州总部和以色列海法之间实在太远了,1970 年代末期的联络手段又没像今天这么方便)诞生的「极度愚蠢」堆叠式(Stack)寄存器架构(附赠让人摸不着头绪的80 位元延伸双倍精确度浮点格式),强迫多数浮点指令的运算元,其中一个非得指定放在堆叠寄存器的顶端不可。

英特尔在Pentium 加入FXCH 指令用来交换置顶寄存器,原本仅内建一组浮点运算单元,流水线不能同时执行两个浮点运算指令的Pentium,简单的浮点运算指令可和FXCH 一同塞进两条指令流水线,但实际上也只有执行一个有效浮点运算,况且后头接连着的整数指令,都会被延误最少一个时钟周期。
判断分支条件需「借用」整数运算通用寄存器与执行单元,则是80×87 另一个弱点,从一个浮点运算设定条件码、将浮点运算的执行资讯搬移至通用寄存器、传送至条件码寄存器,再依据其结果,启动正常的分支处理流程,Pentium 整整耗时9 个时钟周期。当然可透过「插入」其他整数指令来降低效能损失,但无法弥补当执行条件判断密集的程序,整数浮点单元之间反覆「踢皮球」的伤害。
这些在今天只会让人觉得很荒谬的往事,让Pentium 的浮点性能仍远远不及同时期的RISC 处理器,只能在x86 的世界当大王,这宿疾到了新一代Pentium Pro 依旧无解,同期MIPS R10000 的SPECfp92 浮点效能还是Pentium Pro 的「3 倍」以上,还因为PowerPC「外挂」AltiVec 而一度被拉开差距到差点看不见车尾灯的程度。
直到Pentium III(Katmai)开始扩充SIMD(单一指令,多重数据流)浮点指令集SSE、初代Pentium 4(Willamette)的SSE2 新增双倍精确度浮点格式,一路到Sandy Bridge 的AVX,引入VEX (VectorExtension)标头,一口气解放了过去x86 指令编码带来的重重枷锁,才算功德圆满。

但即使看似出师不利,x86 指令集的沉重包袱,并未让英特尔就此停下脚步,依然持续精进Pentium 处理器,就算没有一鼓作气打开天堂大门,却也让紧闭已久的门缝渗出充满希望的曙光。
从企图杀入很长一段时间内「可远观不可亵玩焉」的服务器市场,预期Windows 95 激发个人电脑市场爆发性成长时,补足高效能桌机和笔记型电脑需要的基本功能,到迎合「多媒体」的新潮技术营销名词,无不是英特尔1990 年代初期念兹在兹的技术发展重点。这些努力的痕迹,统统一字不漏深深刻在Pentium和整个计算机工业的历史上。
原汁原味的多处理器支持性
「多处理器支持性」是进入工作站与服务器市场的最低门槛入门票,而Pentium 则是x86 历史上首度「原生支持(Glueless)多处理器」的先行者,但严格说来,这到了0.5 um 制程的第二代Pentium(P54C)才实现,而在此之前,也并不是没有「多处理器x86」的存在,只是需要外挂特制的系统芯片组,或连操作系统都要特殊版本。
一个便于实作的「无需外挂额外芯片」(Glueless)的多处理器(或多核心)环境,需具以下条件:
-
分配、协调各I/O 周边装置存取处理器需求的能力,发出中断(Interrupt)时,知道该由哪个处理器负责:标准化的中断处理机制。
-
快取存储器数据一致性协定(Cache Coherence Protocol):回写式(Write-Back)快取存储器常见的MESI(Modified, Exclusive, Shared, Invalid)协议。
-
低成本多处理器系统的根基:可让多处理器共享的系统总线。
3 项条件之一,最重要者莫过于第一项。1983 年,17 名因英特尔极具野心的「32 位元微电脑大型主机」iAPX432 计划失败而离职的员工,创立的Sequent ComputerSystems(1999 年被IBM 购并,研发高阶英特尔处理器的系统芯片组),就曾推出一系列采用80386 与80486 的多处理器产品线,但这些花费不菲的专属方案,仰赖特制系统芯片组与定制化过的操作系统,才能正确的将系统中断(System Interupt)传送到各处理器,多处理器x86 平台仍缺标准化的中断处理机制,并非可长可久的解决之道。

1993 年10 月27 日,也是初代Pentium 发表后的半年,英特尔首度公开第一版「多处理器规范」(MPS,Multi-Processor Specification)与最重要的「处理器本地端先进可程序化中断控制器」(Local APIC,Local Advanced ProgrammableInterrupt Controller)与I/O 专属的I/OAPIC,取代老旧的8259 PIC。
每个Pentium 或80486 处理器起码要有一个Local APIC,与系统I/O 芯片组的I/O APIC,透过独立于系统总线的3 位元APIC Bus,I/OAPIC 将周边装置的中断需求传递给处理器的Local APIC,以决定中断服务需求该指派给那些处理器,踏出了低成本多x86 处理器系统的第一步。

英特尔的竞争对手并非没有替代方案,1996 年上市的Cyrix 6×86 依据OpenPIC规范,支持自家定义的SLiC,但也只有VIA 的Apollo 芯片组对应此规格,基本上有跟没有一样,而AMD的x86 多处理器环境,更是要等到1999 年采用Alpha EV6 总线、理论上最多支持14 颗处理器的K7了。

不过初代Pentium 并未内建Local APIC,同时期系统芯片组也没有I/O APIC,要打造多颗Pentium 平台,每一颗Pentium 需外挂一颗单价高达26 美元、兼具Local APIC 与I/OAPIC 两者功能的82498DX,I/O 也需动用一颗。换句话说,双处理器系统就需要用到3 颗,怎么看都不算便宜,还会占用不少主机板空间。
后来0.5um 制程的第二代Pentium(P54C)变成史上第一颗整合Local APIC 的x86 处理器,对应的系统芯片组也陆续在南桥(South Bridge)内建I/O APIC(未内建者,可选配专用的82093AA I/O APIC),总算让双Pentium 摇身一变,成为「Glueless」的多处理器平台。

受制于缺陷重重的系统架构,如效率不足的系统总线、处理器缺乏非循序存储器存取能力、处理器共享外部的第二级快取存储器让总线问题更加雪上加霜等等,并未让Pentium 在服务器市场取得重大突破,到了Pentium Pro 面世后才迎刃而解,开启Xeon 统治服务器市场之路,那又是另一段截然不同的故事了。
决定处理器核心/线程上限的Local APIC 与闯祸的操作系统支持性
处理器核心持续激增的今日,Local APIC 最重要的角色在于决定处理器的核心与线程上限。原先最早的APIC 上限是15,2000 年Pentium 4 开始出现的xAPIC(将APIC 的3 位元专属总线直接「融入」系统总线的通讯协定,避免APIC 运作时影响存储器存取效能)增加到255,2008 年Nehalem 的x2APIC更多达4294967295,可视为「无限大」。
假如各位想多学些对亲朋好友炫耀的「无用知识」,稍微花点脑筋,牢记一下这3 个数字的由来:
-
APIC:Pentium和Pentium Pro(与Pentium II、Pentium III、P6核心的Xeon)动用Local APIC的ID寄存器24-27四个位元,16进位的0xF(10进位制的15)用做广播,所以2 4 −1=15。
-
xAPIC:Pentium 4到Penryn用到Local APIC的ID寄存器24-31八个位元,16进位的0xFF(10进位制的255)用做广播,所以2 8 −1=255。
-
x2APIC:Nehalem开始使用存于MSR(Model-Specific Register)的32位元x2APIC ID,16进位的0xFFFFFFFF(10进位制的4294967295)用做广播,所以2 32 −1=4294967295。
但帐面上的「理论值」让人看得很爽是一回事,微软这些操作系统厂商是否乖乖买单又是另一回事。很不幸的,AMD Zen2 世代EPYC 与Threadripper将单颗处理器的实体核心术/逻辑处理器,一举推进到64 核/128绪,就变成微软Windows 的灾难了。

一台2 颗EPYC 7742 或7702 的服务器,拥有128 个处理器核心和256 条线程,但是Windows Server 2016 和2012 R2 并不支持「AMD 新型平台的x2APIC」,无法吃下这么多逻辑处理器。
事实上,根据微软的EPYC 性能调校文件,Windows Server 2019 之前的旧版Windows Server,只能支持2 颗48 核心的EPYC 和192 个逻辑处理器。安装2019 年9月前的Windows Server 2019,也需要事先在BIOS关闭x2APIC 和多线程,安装完毕并装完所有的系统更新档,重新开机进BIOS 恢复功能,才能在工作管理员的效能选单看到全部CPU。

再次同场加映AMD。刚好前阵子Anandtech 有特别报导的EPYC 在Windows 10 发生的灾情(尽管这和APIC 没有关系)。Windows 系统核心会预设64 个CPU组成一个「Windows Processor Group」,当逻辑处理器超过64 个,会将多出余数包成另一群,像一颗64 核/128 绪的Threadripper,就会变成一颗实体CPU 有「两包」64 个逻辑处理器。

但Windows 10 要企业版(Enterprise)才提供此功能,家用版(Home)和专业版(Professional)会将「满出来的部分」,误判为占用另一个处理器脚位的实体CPU,意思就是误解成「两颗」处理器的系统,将误导操作系统的线程排程,降低系统效能,这时关掉多线程,很可能表现还比较好。
在计算机的世界,任何「看起来很棒」的技术和功能,无不是「软硬兼备」的成果,当入手顶规的硬件时,也请多多关心手上的软件环境是否可发挥最高效益。笔者现在都可以猜到花大钱买TR 3990X 的「长辈」急着升级Windows 10 企业版的画面了。
「让人比较有感」的指令集扩展
如果能让笔者选择,其实x86 指令集扩张史中最重要的一幕,绝对是迈向32 位元的80386、虚拟86 模式(Virtual 8086 Mode)与具备分页表的虚拟存储器。但事隔多年,印象最深刻的,依旧对个人电脑市场规模爆炸式成长、使用者急速增加的1990 年代,英特尔在Pentium 家族干的一堆好事,包括极具历史意义的第一次SIMD 扩张:MMX。

相信各位不可能不知道CPUID 这经常用来辨识处理器厂牌、功能、版本与规格的好工具,但你们知道背后作这件事的「CPUID」指令,就是从Pentium 开始登场的吗?众多程序设计师计算指令执行周期数的RDTSC(Read Time-Stamp Counter),也伴随着Pentium 而生。用在操作系统避免不同线程同时对共用资源读写「互斥锁」的CMPXCHG8B(Compare and Exchange 8 Bytes),也是小有名气,WindowsXP 就是因这个必备指令,无法执行于Pentium 之前的所有x86处理器。
前面有提到MSR(Model-Specific Register),意指在x86 架构处理器中,一系列用于控制处理器执行、功能开关、除错、追踪程序执行、监测处理器效能等功能的寄存器。MSR 的雏形始于80386 和80486,到了Pentium,英特尔新增RDMSR(ReadMSR)和WRMSR(Write MSR)指令用于读写MSR,使其真正的实用化。此外,软件可透过前述的CPUID 指令,查询处理器可支持的功能,并确认这些功能对应的MSR 是否存在。
同时英特尔在Pentium「复刻」笔电专用的80386SL 和80486SL 处理器,那独立于真实模式和保护模式,干了哪些好事,连操作系统都不知情的系统管理模式(SMM,System Management Mode)。英特尔制定SMM 的初衷,在于让笔电OEM 厂商自订必备的电源管理与周边装置管理,如为了省电,动态关闭用不到的周边设备,需要时再重新启动等,将SMM 从「特殊武器」提拔成「制式装备」,暗示英特尔认定笔电即将普及化的未来。
顺道一题,相对于x86 指令集在节区定址定义4 层权限的Ring 0 到Ring 3(数字越小权力越大),SMM 的权限经常戏称为Ring -2,那Ring -1 跑到哪去了?答案是x86 硬件虚拟化技术用来拦截「在使用者模式仍会更动系统底层的危险指令」的Hypervisor 权限。

这些指令集扩张看似微不足道,远不如那票SIMD(MMX、SSE、SSE2、SSE3、SSE4、AVX、AVX-512)「华丽壮大」,却也是不可或缺的基本功,同为「高效能处理器不可被分割的一部分」。但Pentium 史上最知名的指令集MMX,就是一场欢乐异常的连续剧了。

为了MMX 让Pentium 被迫大兴土木、脱胎换骨
Windows 95 带动个人电脑的多媒体需求,英特尔自然不能免俗,势必要让处理器跟「多媒体」沾上边,试图推动主机板加挂一颗来自第三方的数位讯号处理器(DSP),专门处理即时性影音应用程序。但因为NSP 的运作模式是独立于操作系统的化外之民,等于需要操作系统开后门,微软为此拒绝买单,因此胎死腹中,才出现了MMX。

打从英特尔在1996 年,抛出MMX 这从未讲清楚说明白的「无意义技术营销商标」,全名一直众说纷纭、莫衷一是,还先后出现3 个版本:
-
MultiMedia eXtension
-
Multiple Math eXtension
-
Matrix Math eXtension
名称怎样不重要,各位只要记得一件事:为了操作系统兼容性,MMX指令集借用x87 浮点运算寄存器(80 位元中的64 位元)的SIMD「整数」运算,这样就够了。英特尔定义全新SIMD 寄存器,从Pentium III「Kaimai」的SSE(KNI,Katmai New Instructions)才开始。

指令集的编码空间毕竟有限,英特尔要从哪里挤出这57 个指令的位置?英特尔将脑袋动到「0Fh」开头的运算码(Opcode),这却造成前所未见的麻烦:过去0Fh 的主要用途「当处理器的解码器收到时,自动将该指令执行流程跳到外挂的辅助处理器」,当初英特尔就靠这招来处理8087 浮点辅助处理器,0Fh 开头的x86指令都不是什么「需要追求效率」者,也因此,Pentium 的指令解码器也没有特别「关照」它们,意味着难以迅速完成解码MMX 指令的重责大任。
主导Pentium MMX(P55C)研发的以色列海法团队,不得不大兴土木,将指令流水线深度从五阶延长到六阶,争取足够的指令解码时间。多这一阶并非有害无益,因为执行单元将有更充裕的时间存取数据快取,并缩短电路的关键路径,利于提高时钟频率,让Pentium MMX 最终可到达300MHz,比前代P54C 多出整整50%。

但延长指令流水线也带来更严重的分支预测错误代价,英特尔索性将「流水线深度长达12 阶」的第六世代Pentium Pro 搭载的双层动态分支预测与副程序返回位址缓冲区等先进技术,原封不动的逆向移植到Pentium MMX,亦倍增快取存储器和数据写回缓冲区,转换虚拟和实体存储器位址的TLB,也强化为可同时处理两种不同分页大小的版本,种种改进项目仿佛威而刚,让吃下蓝色小药丸的Pentium MMX 摇身一变成「5.5 代」x86 处理器。

为了减少耗电与发热,英特尔将MMX 执行单元与实体寄存器独立于x87 浮点运算器,执行MMX 指令时,因指令集定义「逻辑上MMX 和x87 浮点无法同时执行」,可关闭「吃电如喝水」般的浮点单元以节约电力,可是结合加倍的快取存储器和种种增强方案,P55C 晶体管数从P54C 的330 万激增到450 万,制程从「不计多出10%芯片面积以追求最高时钟频率」的350 纳米BiCMOS 改进为「自此英特尔转向追求更低成本并降低耗电」的280 纳米CMOS,芯片面积和制造成本仍足足比P54C 多50%。
Pentium MMX 在1997 年1 月上市没多久,同年5 月同样支持MMX的Pentium II 就以「塑胶大弹夹」外观,现身于各地电脑卖场的玻璃柜,无论怎么看,Pentium MMX 都是过渡期强烈的尴尬产物。

(Source:Flickr/AndyRogers CC BY 2.0)
但Pentium MMX 对英特尔在以色列海法的研发团队而言,却是极为重要的历史里程碑,建立起「擅长精炼现有架构压榨更多价值」的名号,接连重塑P6 微架构成为Centrino 心脏的PentiumM (Banias, Dothan)、当英特尔在Pentium4(NetBurst)惨遭滑铁卢的危急存亡之秋端出Core 2(Merom, Conroe, Woodcrest)救驾成功、融合P6 与NetBurst 之长的Sandy Bridge 终结AMD K8 的辉煌岁月、直到「奋六世之余烈」集大成的「终极x86 微架构」Skylake,清一色都是出自以色列海法团队的不朽杰作。
x86 指令集长期欠缺标准造成竞争对手与软件开发商的困扰
Pentium 的「历史地位」倒是值得另外添一笔:x86 指令集欠缺公开业界标准,搞死不少人的陈年旧帐,终于正式浮上台面。
Pentium Pro 总工程师之一的Robert Colwell 回忆录《The Pentium Chronicles》说过,开发一颗x86 处理器,最艰巨的挑战在于「如何保证可兼容所有旧程序」。特别早期x86 处理器,很多未定义的运算码(Opcode)并没有遮掉,被人发现又拿来用了,以后的处理器开发人员就只能乖乖想办法「塞」进去,前提是你也要知道这些陷阱到底藏在哪里。
各位是否天真的以为所有x86 处理器厂商的产品,都保证彼此兼容,可执行一模一样的软件?很遗憾的,这种好事从来就不存在英特尔统治的x86 世界(最起码,前阵子让Linus Torvalds 大暴走的AVX-512,AMD 现有产品也是付之阙如),英特尔在Pentium 时代的所作所为就是最好例证,让初版使用者手册描述新增指令的「附录H」故意保持完全空白,英特尔的竞争者与软件开发商纷纷变成倒霉的苦主。
英特尔并不像那票会定期推出版本演进与相关规范的RISC 指令集(有关心ARM 的读者应该很清楚)、积极推广自家指令集给其他潜在竞争对手,而是完全不管其他人死活。想研发x86 兼容处理器的有志之士,假若没有跟英特尔签订互相授权协议,只有两条路可选:乖乖用电子显微镜默默研究英特尔处理器的晶粒,尝试逆向工程,要不然就干脆不支持不顾兼容性,碰到就视为非法指令,剩下的烂摊子就丢给操作系统厂商伤透脑筋了。
像Cyrix 在被National Semiconductor 购并前,压根没有英特尔技术授权,只能闷着头逆向工程慢慢搞,自然也无法100% 兼容,让号称「第六世代」的6×86,连CPUID 和RDTSC都残缺不全,指令集兼容水准只有80486 等级,甚至还得逼迫软件厂商撰写修正程序。同时期的AMD 则是不计代价拼死拼活,都要藉由逆向工程挤出100% 兼容性,下场就是产品上市延误,错失商机,还亏当初Compaq 傻傻不肯推出Pentium 个人电脑,宁愿痴痴等待AMD K5,更惨的是,撑到最后还是等不到。
英特尔竞争者也都不是省油的灯,不遑多让抢着跳出来扮演「麻烦制造者」,自行定义「兄弟独有之创见」的自家指令,不仅企图争夺x86 指令集的主导权,并强化产品效能及营销筹码,像AMD K6 的3DNow!、AMD K8 的x86-64,Cyrix 6x86MX 的EMMI 与CyrixIII 的MMX-FP,Centaur 一度想不开的57 个SIMD 浮点指令和22 个自定义浮点寄存器,都是斑斑可考的历史陈迹。
AMD 还一度想不开,抢先注册「SSE5」,摆明跟英特尔AVX 打对台,还好在2009 年5 月6 日紧急采煞车,宣布「皈依」AVX,但还是忍不住捞过界「补完」被英特尔废除的四运算元指令格式(xmm1=xmm2×xmm3+m32)。AMD 要开始支持乱成一团的AVX-512并完全兼容,大概也是很久以后的未来了。

回顾这些年来的x86 指令集扩充战争,唯一从英特尔手上抢下先机的,也只有AMD x86-64 那次,还是微软私下威胁「不打算支持两种不同的64 位元x86」(英特尔本来有自己的Yamhill,但为了保护IA-64 迟迟不肯拿出来)强迫英特尔接受的结果。
最初英特尔多心不甘情不愿、打死都不承认 64 位元 x86 存在的「IA-32e」和 AMD x86-64 也并非一模一样,英特尔独占 CMPXCHG16B(Pentium 那个 CMPXCHG8B 的进阶版)和 SSE3,AMD 多出分页表 NX(No Execute)保护位元和 3DNow!。谈到 x86 处理器厂商要彼此 100% 水乳交融,说有多麻烦就有多麻烦,说微软有多火大就有多火大。
不过乱象还是持续延烧,还烧到虚拟化领域,近十多年来虚拟化应用快速普及,然后 2005 年英特尔 VT-x(Vanderpool)和 2006 年 AMD AMD-V(Pacifica),双方根本就是各搞各的,老死不相往来,让 VMware vMotion 此类不停机的虚拟机动态迁移技术,迟迟跨越不了不同 x86处理器厂商的边界,无形中也侷限了 x86 处理器「向上发展」的潜力,目睹此景,IBM 应该会继续开心下去。
重塑x86 处理器世界观的历史认知
行文至此,想必各位看官脸上已挂著颤抖的嘴角与充满劫后馀生的表情,或多或少逐步解构并重组过往对个人电脑市场与 x86 处理器演进史的认知,有可能瞬间茅塞顿开,也有可能继续满头问号。
本文并非教科书,而是经由複习坊间甚少重视的历史背景与不容易注意到的细节,体认到平日陪伺在旁、习以为常的 x86 处理器,能走到今天是多麽不容易的一件事。罗马不是一天造成,英特尔的霸权也不是平白从天上掉下来,这些年来我们一同挤过这麽多条牙膏,更不是毫无苦衷。
身为英特尔 1990 年代「Landmark」芯片与无数潜藏已久历史暗流的缩影,Pentium 带来 x86 世界太多「第一次」,承先启后,奠定 25 年技术演进与市场发展的基础逻辑。毕竟电脑是人类创造的东西,背后的人性和思维远远超越技术。英特尔可靠开创新局的 Pentium 与继往开来的 Pentium Pro,在众多敌人环伺下杀出一条通往全新市场血路过程中「产生的价值」,如「技术领先无法保证商业胜利」和「成功的产品往往是折衷妥协后的产物」,统统很有意思,更值得各位细细品味。
关于Pentium,似乎笔者不小心遗漏了什麽,听说跟浮点除法(FDIV)有关?算了,就当作提醒世人吧。
微信加群
,




