摘 要
本文介绍了克隆选择原理,阐述了关键算子的设计与发展,并对克隆选择算法的研究现状和应用进行了展开,最后提出了克隆选择算法未来的研究趋势。
关键字
克隆;超变异;克隆选择算法
0 引言
生物免疫系统是脊椎动物为了保护机体抗御病原体等“非我”(non-self)的侵害所进化出的防御机制。鉴于其具有自学习、记忆机制、模式识别、动态自适应、动态鲁棒性和并行性等优越的特质,生物免疫系统为解决实际复杂工程问题提供了大量的仿生灵感。人工免疫系统(Artificial Immune System, AIS)通过模拟生物免疫系统功能、原理和模型来构造算法,被广泛应用于函数优化、异常检测、模式识别和工业工程等诸多领域。
由于生物免疫系统自身的复杂性,形成了多种免疫学说。其中,Burnet 在 1959 年提出克隆选择学说构建了克隆选择算法的基础。克隆选择学说解释了在抗原刺激下适应性免疫反应的基本特征,其基本思想是只有那些能识别抗原的细胞才被选择进行增殖,而那些不能识别抗原的细胞则不被选择,被选择的细胞通过增殖和超变异的过程提升其亲和度直至达到亲和度成熟。根据克隆选择理论,De Castro 等通过仿生免疫反应中的亲和度成熟过程,提出了克隆选择算法 CLONALG,成功应用于字母识别、多模态函数优化、组合优化和 TSP 问题等,掀起了免疫克隆选择算法的研究热潮。
随着研究的深入,克隆选择算法被不断改进,并与其他策略混合,在多模态优化、约束优化、动态优化、多目标优化、模式识别和路径优化等领域取得了亮眼的成绩。本文重点阐述克隆选择算法的基本原理、研究现状和需要进一步研究的热点问题。
1 克隆选择算法
由于生物免疫系统庞大且复杂,为便于模型设计,从计算的角度可以将生物免疫系统原理进行简化。“非我”的物质被统称为抗原,免疫系统受抗原刺激引发免疫应答产生抗体。抗体能与抗原产生特异性结合。抗体通过其抗体决定基和抗原的抗原决定基之间的模式互补匹配,来与它能识别的抗原结合。结合的强度取决于模式匹配程度,这种结合力称为亲和度。亲和度越高,抗原与抗体之间的关联越紧密。特定的抗体分子对不同的抗原具有不同的亲和力。抗体也能和其他抗体结合,这样抗体便具有识别抗原又被其他抗体识别的“双重身份”。如图 1 所示,在生物免疫系统克隆选择过程中,与抗原亲和度高的抗体被选择,然后通过克隆快速增殖分化,并通过超变异调整自身抗体与抗原亲和度直至亲和度成熟(affinity maturation),产生最佳抗体,最终消除抗原。一些抗体会转化为记忆细胞,当遭遇相同或相似抗原攻击时能迅速反应。
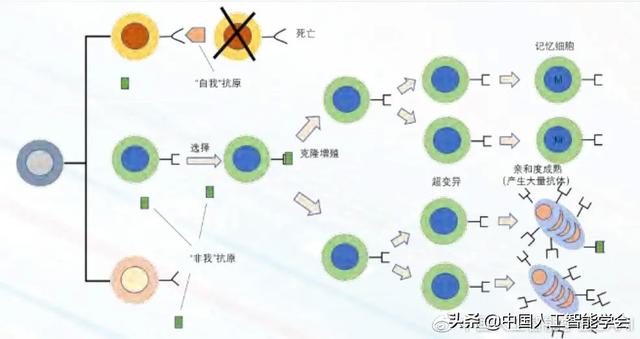
图 1 生物免疫系统克隆选择过程
克隆选择算法(Clonal Selection Algorithm, CSA)是通过仿生生物免疫系统通过克隆选择实现适应性免疫过程的计算模型。克隆选择算法的基本框架如算法 1 所示。通常情况下,需要解决的问题被映射为抗原,问题的解被映射为抗体。
算法 1 克隆选择算法基本框架
-----------------------------------------------
输入:种群数目,相关参数设定等
输出:问题的解
------------------------------------------------
Step 1: 初始化:产生初始抗体种群
Step 2: 亲和度计算:计算抗体 - 抗原亲和度,即抗
体的适应度值
Step 3: 选择:选择 m 个与抗原亲和度高的抗体
Step 4: 克隆:对所选择的抗体进行克隆操作
Step 5: 超变异:对克隆个体实施超变异操作
Step 6: 对新产生的抗体的亲和度进行评估
Step 7: 选择亲和度高的 n 个抗体到下一代
Step 8: 受体编辑:随机产生 d 个抗体,加入到种群中
Step 9: 终止条件判断。如果终止条件未满足则算法
继续,否则结束,输出最优抗体及其适应度值。返回 Step4
2 关键算子定义及其改进
2.1 亲和度
亲和度是对抗体质量进行评价的度量。根据不同的问题和编码方式,亲和度的定义各有不同。在模式识别和路径优化等问题中,通常采用二值编码或者整数编码等方式。此时,通常选择相似度距离计算方法,比如汉明距离和曼哈顿距离作为亲和度的衡量标准。对于连续优化问题,通常以实数编码实现,一般采用目标函数本身,或者是欧式距离来衡量。在处理多模态问题时需要同时考虑抗体与抗原的匹配度,以及抗体的多样性,亲和度被细化为抗原 -抗体亲和度和抗体 - 抗体亲和度并分别定义。
2.2 克隆
克隆是无性繁殖,复制自身的过程。克隆选择的过程如图 2 所示。在克隆增殖过程中,抗体克隆子代的数目与抗原的亲和度值正比,即越优秀的个体产生的克隆子代越多。因此,在算法实现时,克隆子代的数目也遵循与其比例克隆的定义方式。比例克隆在当前最优的局部增加搜索,能增强局部搜索能力。如果优化过程旨在单个抗体种群中定义多个最优值,那么可以选择种群中的所有抗体参与克隆过程。此时,比例克隆不再适用,新的克隆个数被重新定义为每个抗体都将拥有相同的克隆数目,即等比例克隆。
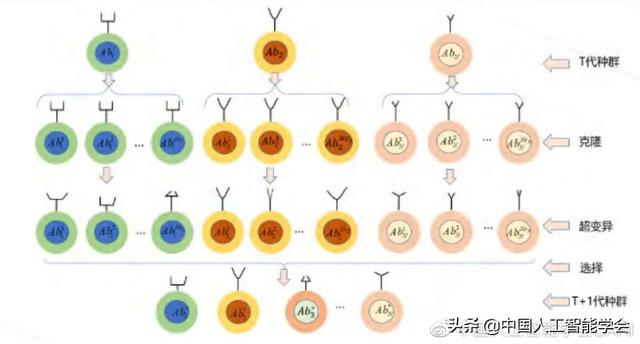
图 2 克隆选择算法中的克隆、超变异和选择过程
相较于遗传算法的两个父代通过交叉产生两个子代(2-2),粒子群算法一个父代通过位置更新生成一个子代(1-1)的产生方式,克隆操作的一个父代在一次迭代中就产生了多个子代(1-Nc)。这种方式虽然为产生更优秀的子代提供了更多的可能性,但显然也带来了计算资源的大量消耗。因此,为节约计算资源,有时会给克隆数目增加上界的阈值限制。极端情况下,克隆个数被设定为 1 个,这与 1-1 的设定在生成子代数目上几乎一致。
2.3 超变异
超变异是指高频的变异,抗体通过这种高频的变异修改自身可变区域结构,以期提升与抗原的亲和度。不同于遗传算法中的交叉操作,超变异直接在单个父代上进行,随机选择一个或者一段基因位进行改变,能显著增加抗体的多样性。在克隆选择过程中,超变异的频率一般遵循与抗体的亲和度成反比的规律,即适应度高的个体其变异的频度越低。
在遗传算法中,变异是与交叉算子配合使用的,变异频率通常较低,而且变异的主要的是增加算法的跳出局部最优的开拓能力。而在克隆选择算法中,变异算子作为主要算子之一,需要同时兼顾局部的勘探能力和全局的开拓能力,因此其设计更为复杂,每个抗体的突变率可以各不相同。在亲和度低的地方,则突变率较大,增加全局开拓能力;而在亲和度高的地方,变异率较低,增加局部勘探能力。
在克隆选择算法中,不同编码方式有不同变异算子的实施方式。对于二值编码或者整数编码,往往采取某些基因位或者基因段上值的改变,而对于实数编码其操作方式更加多样,常用的方式有采用亲和度的负指数函数,也有高斯变异和柯西变异等方式。超变异的实施主要集中在控制变异的步长上。在具体问题背景下,超变异的设定有时也与循环次数等相关,即变异的步长随着迭代次数的增加变小,从全局搜索逐渐到局部搜索。
2.4 选择
选择是指新产生的子代会以一定的生存几率存活或者死亡。一般来说,适应度值高的个体被选取到下一代继续生存的几率更大。在实际操作中,常用的方法有以下几种。
(1)轮盘赌选择:它属于比例选择操作,首先将适应度值归一化,然后把概率分布看作一个轮盘,轮盘的每一个切片的大小都与归一化后的个体选择概率成比例,选择的过程如同旋转轮盘,它停止旋转时,最上方的切片对应的个体即被选择。
(2)锦标赛选择:锦标赛选择从群体中随机选择 nts 个个体作为一组,其中 nts<p(p 为<="" div="">
群体中个体的总数)。选择的 nts 个个体相互竞争,并保留最优的个体。假如参与锦标赛规模nts 不是太大,其选择能防止最优个体主导群体,具有较低的选择压力;反之,若 nts 太小,则不良个体被选择的概率就会增大。
(3) (μ,λ) 选择和 (μ λ) 选择:这两种选
择方法是在进化策略中使用的确定性排序选择方法。μ 表示父代个体数目,λ 是每个父代产生的子代个体数目。(μ,λ) 是选择 λ 个子代中最好 μ 个子代作为下一代,而 (μ λ) 则是从 μ 个父代和 λ 个子代的并集中选择最好的 μ 个个体作为下一代。本算法中采用的是 (1 nc) 选择,每一个父代产生 nc 个子代,然后从父代和子代的并集中选取最优的个体。
(4)随机选择:随机选择不考虑个体的生存能力(即适应度),而只是随机地选择个体。每个个体,无论好坏都以相同的概率被选择。
2.5 受体编辑
受体编辑是对抗体基因组进行二次重排的操作。在克隆选择算法中,受体编辑被用来产生新的抗体以增加种群的多样性,避免算法在搜索过程中陷入局部最优。
2.6 其他
根据所求问题的实际需求,除克隆、超变异和选择操作算子以外,还有其他的一些免疫机制被引入到克隆选择算法中。常见的操作算子有以下几种。
记忆:在克隆选择过程中,会有一部分抗体以记忆的方式保留下来,当机体再次遇到相同或者相似的抗原攻击时,记忆机制能快速唤醒被保存的抗体,快速高效地达到亲和度成熟。记忆机制在模式识别中可以实现模式记忆,在动态优化中可以对发生的环境进行记忆,促进算法更高效的搜索。免疫记忆根据记忆时间长短还可以分为长期记忆和短期记忆,被提取出相应的策略运用在算法设计中。
基因重组:利用机体基因片段库中的基因片段,重新组合成有效的基因序列的一种重构抗体的方式。它是除高频突变的超变异以外,又一种增加抗体多样性的方式。在实际操作中,基因片段库从问题中抽取,或者是从经验中获得,还可以从搜索过程中产生的数据里得到。通过基因重组,一方面可以增加抗体多样性;另一方面有利于优势基因片段的结合,构造亲和度更高的个体。另外,还有新个体招募、交叉反应等免疫机制也在克隆选择算法中以不同的操作或者策略实现,在此不再赘述。
树突细胞算法模拟了生物免疫系统中树突细胞的工作方式。一般来说,典型的树突细胞算法依次包括初始化、检测、环境评估和分类四个阶段。在初始化阶段,首先生成一定规模的树突细胞群体,然后选取训练集元素中的关键属性,从属性的实际意义和问题需要出发,将其映射成不同类型的信号,包括安全信号、危险信号和 PAMP 信号。在检测阶段,首先由未成熟树突细胞收集抗原和信号,接着计算并累积协同刺激信号、半成熟信号和成熟信号的值。当累积的协同刺激信号值超过迁移阈值后,进入环境评估阶段。在环境评估阶段中,半成熟信号值和成熟信号值中较大的那一个将成为该细胞的环境。一般地,半成熟环境值记为 0,成熟环境值记为 1。最后是分类阶段,按照细胞的环境值总和计算成熟环境抗原值(MCAV),并根据 MCAV 衡 量 抗 原 的 可 能 有 害 程 度。MCAV 值越接近 1,抗原就越可能是有害的。
Greensmith 和 Aickelin 在 2005 年提出了第一个树突细胞算法;随后,Aickelin 领导的研究团队继续在树突细胞算法上做了大量的工作。目前,树突细胞算法已经应用在故障检测、网络入侵检测等多个领域。例如,Greensmith 等使用树突细胞算法进行网络入侵检测。
3 克隆选择算法的应用
3.1 克隆选择算法应用于全局优化
由于克隆算子需要消耗大量的计算资源,而超变异操作的随机性较强,因此在面对可能具有多个局部最优的全局优化问题时,克隆选择算法往往需要与具有引导性搜索的策略相结合来提升算法的收敛能力。Gao 等将重力搜索算法与克隆选择算法相结合,Peng 引入了鲍德温效应和正交学习,Liu 将粒子群与克隆选择算法融合起来,Tien 混合了克隆选择和蜂群算法。
3.2 克隆选择算法应用于约束优化
在解决约束优化问题时,进化算法往往需要结合罚函数、修复技术、约束和目标分离等约束处理技术。除了这种常用方式外,克隆选择算法另辟蹊径,从生物免疫机制中探求解决途径。Aragon 提出了一种基于 T 细胞模型来解决约束优化问题。T 细胞模型根据成熟的程度, T 细胞被分为处子细胞、效用细胞和记忆细胞。这三种类型的细胞被分别赋予特定的种群、特定的变异操作和选择策略,被用于解决工程优化和约束优化问题。Zhang 等受生物免疫机制启发,将种群分为寻求最优解的可行群体和接近可行区域的不可行群体来求解约束优化问题。其中,可行种群致力于通过克隆选择、重组和超突变操作在可行区域中进行勘探;不可行种群则通过位置更新来促进沿可行边界的探索,然后通过提取方向信息促进这两个群体之间的交互。
3.3 克隆选择算法应用于动态优化
多样性保持、对变化的及时反应、多种群和记忆机制是针对动态环境下优化问题代表性的处理手段。对动态环境的有效应对是生物免疫系统必备的技能之一,而以上的处理手段往往也内化在针对动态优化的克隆选择算法之中。通过调整超变异的概率和幅度,能对环境变化起到一定的积极作用。Zhang 等提出了类梯度搜索机制加快算法收敛速度,并采用聚类策略改善局部搜索能力和保持多样性。Shang 等将免疫克隆算法与协同进化策略相结合,并采用量子免疫计算理论,设计了量子更新操作、协同进化竞争操作与协同进化协同操作,提出了改进的量子免疫克隆协同进化算法解决动态多目标优化问题。Zhang 等将种群根据空间位置划分为多个聚类,增加基于学习的克隆选择算法促进个体进化,并形成记忆抗体,然后通过将每个环境下的最优解看作时间序列,利用记忆抗体进行预测。Zhang 等将种群划分为两个子种群,每个种群采用不同的策略分别进化,并将危险理论和克隆选择算法相结合解决了非线性动态约束优化问题。Qian 等针对动态环境中带约束的背包问题,提出了一种基于自适应记忆和人工系统动态识别功能的带约束的动态免疫优化算法。
3.4 克隆选择算法应用于多目标优化
Shang 等将种群中的抗体分为支配抗体和非支配抗体,采用等比例克隆提出了一种改进的克隆选择算法来求解多目标优化问题。Lin 等将亲和度与拥挤距离进行关联,提出了微种群免疫多目标优化算法。Liang 等设计了两个模块来求解多目标优化问题,模块一通过竞争者组成的子群体独立地优化每个目标;模块二采用克隆选择算法同时优化多个目标。Sun 等提出一种基于聚类的多目标优化免疫算法,该算法使用基于聚类的克隆选择算子,能更好地保持在搜索新的最优解区域与加强局部搜索之间的平衡,在收敛性、多样性和分布均匀性方面具有独特的优势。Li 等提出一种基于分解的克隆选择策略的多目标免疫算法,利用分解将个体与子问题一一关联,采用基于分解的克隆选择策略对表现好的子问题的解进行克隆,促进该子问题搜索。为了更加有效地解决复杂多目标优化问题,量子计算、协同进化和差分进化等各种策略与克隆选择算法结合在一起求解多目标优化问题,取得了很好的效果,在此不再详细展开。
3.5 克隆选择算法应用于实际优化问题
Lu 等利用克隆选择算法的全局搜索能力和不易早熟收敛的优点提出一种改进免疫克隆选择算法,解决车间调度问题。Shui 等提出一种基于克隆选择算法的车辆调度方法,应用于现实世界中的车辆调度问题,可以快速找到满意的调度方案。Vivekanandan 等利用克隆选择算法自动生成基础路径集,减少了路径生成的工作量和时间。Swain 等提出了一种基于克隆选择算法的高效优化程序,解决短期水热调度问题。Basu 将克隆选择算法,应用于动态经济调度问题。Hatata 等利用克隆选择算法对风力机 / 光伏 / 燃料电池混合可再生电力系统进行了优化设计,实现了更低的总成本,确保了高电力系统的可靠性。刘喜梅等提出人工免疫克隆选择算法,解决公共自行车系统再平衡调度问题。另外,克隆选择算法与其他策略相结合还被应用于动态社交网络中的社区检测、乳腺癌检测,以及数据降维、分类、模式识别等方面。
4 结束语
本文介绍了克隆选择算法的基本原理、核心算子及其改进,以及研究和应用现状。克隆选择算法经过近 20 年的发展在优化领域和各种应用领域得到了长足发展,虽取得了一些成绩,但还有很多值得深入研究的问题。首先,克隆选择算法本身的优缺点比较明确,现有的算法也在此基础上进行了各种改进,但是对其理论的分析还较少见于文献中;其次,免疫系统本身比较复杂,对其机理的抽取和仿生的方法性探索还处于起步阶段,现有的方式主要依赖研究者主观的解读,并没有形成系统的方法论;再者,克隆选择算法的核心竞争力及其最擅长的应用领域尚不明晰。
(参考文献略)

选自《中国人工智能学会通讯》
2021年第11卷第3期
免疫计算专题
,