
关注我,了解java
大家好,我是冰冰,今天接着来分享MySQL面试中常见的问题!
本
文
目
录
1、Mysql数据库各种数据类型所占用的空间?
2、为什么innodb表必须有主键?并且推荐使用整型的自增主键?
3、InnoDB和MyISAM存储引擎的存储文件格式
4、索引是怎么支撑千万级表查找的?
5、Mysql 遇到过死锁问题吗,你是如何解决的?
6、说说分库与分表的设计
7、limit 1000000 加载很慢的话,你是怎么解决的呢?
8、查询语句执行流程?
9、更新语句执行过程?
一、Mysql数据库各种数据类型所占用的空间?
字符串:
char(n):n字节长度
varchar(n):2字节存储字符串长度,如果是utf-8,则长度 3n 2
数值类型:
tinyint:1字节
smallint:2字节
int:4字节
bigint:8字节
时间类型:
date:3字节
timestamp:4字节
datetime:8字节
二、为什么InnoDB表必须有主键?并且推荐使用整型的自增主键?
1.因为InnoDB表的数据文件本身就是依照B Tree数据结构组织的,即使用户没有显式的指定主键值,在Mysql底层也会默认维护一个字段作为表的主键值,如果没有字段则维护一个隐藏的主键值列。
2.分为两个方面:
其一是整型:(比较简单,占用空间小)因为索引即B Tree的特性一棵排序好的数据结构,左侧叶子结点一定小于右侧叶子结点的值,在进行主键索引查询的时候,需要进行比较冗余索引主键值的大小,显然整型的效率要高于其它类型。
其二是自增:(利于插入)因为B Tree的特性涉及到树的自平衡,如果是乱序的整型主键,则在维护树的时候需要进行对比,确定位置,并且进行平衡,而如果是有序自增的主键,则只要默认将值添加到最右侧叶子结点再平衡即可。显然后者内存消耗更小。
三、InnoDB和MyISAM存储引擎的存储文件格式
.frm 文件:存储表结构
.ibd 文件:存储索引和表数据信息。所以说InnoDB为聚簇索引,即索引和表数据在一个文件中存储。
MyISAM(非聚簇)
.frm 文件:存储表结构。
.MYI 文件:存储索引信息。
.MYD 文件:存储表数据信息。

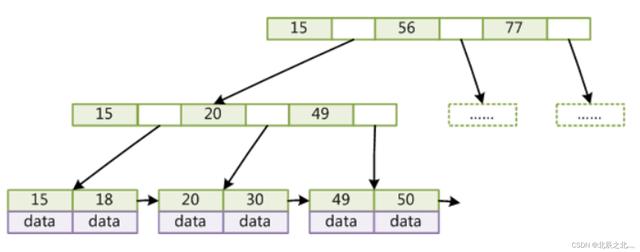
四、索引是怎么支撑千万级表查找的?
MySQL的索引B Tree索引如下图:
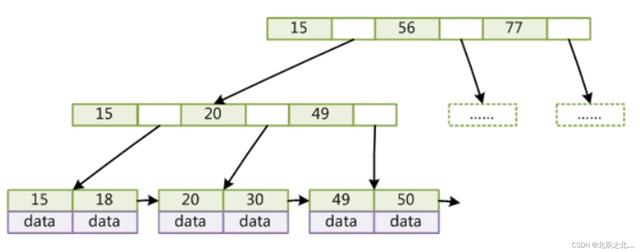
MySQL中InnoDB引擎配置的默认节点大小为16KB。
假设为整型作为主键,则一个索引值占据为(8 byte) 紧跟的磁盘指针(6byte)=14byte,则一个节点可存储的索引值大概为1170个,而一个有data数据的叶子节点占用大小为1K,则叶子节点可存储16个数据,则改索引数共可存储 1170*1170*16 约为 2190W左右的数据,仅需要3次磁盘IO,足以保证高效率。
五、MySQL 遇到过死锁问题吗,你是如何解决的?
发生死锁的必要条件有4个:互斥条件:在一段时间内,计算机的某个资源只能被一个进程占用。此时,如果其他进程请求该资源,则只能等待不可剥夺条件:某个进程获得的资源在使用完毕之前,不能被其他进程强行夺走,只能由获得资源的进程主动释放请求与保持条件:进程已经获得了至少一个资源,又要请求其他资源,但请求的资源已经被其他进程占有,此时请求的进程就会被阻塞,并且不会释放自己已获得资源 循环等待条件:系统中的进程之间相互等待,同时各自占用的资源又会被下一个进程所请求。例如有进程A、进程B和进程C三个进程,进程A请求的资源被进程B占用,进程B请求的资源被进程C占用,进程C请求的资源被进程A占用,于是形成了循环等待条件,如下图所示:

预防死锁:处理死锁最直接的方法就是破坏造成死锁的4个必要条件中的一个或多个,以防止死锁的发生。避免死锁:在系统资源的分配过程中,使用某种策略或者方法防止系统进入不安全状态,从而避免死锁的发生。检测死锁:这种方法允许系统在运行过程中发生死锁,但是能够检测死锁的发生,并采取适当的措施清除死锁。 解除死锁:当检测出死锁后,采用适当的策略和方法将进程从死锁状态解脱出来。
六、说说分库与分表的设计
分库分表方案,分库分表中间件,分库分表可能遇到的问题
分库分表方案:
1.水平分库:以字段为依据,按照一定策略(hash、range等),将一个库中的数据拆分到多个库中。
2.水平分表:以字段为依据,按照一定策略(hash、range等),将一个表中的数据拆分到多个表中。
3.垂直分库:以表为依据,按照业务归属不同,将不同的表拆分到不同的库中。
4.垂直分表:以字段为依据,按照字段的活跃性,将表中字段拆到不同的表(主表和扩展表)中。
常用的分库分表中间件:
1.sharding-jdbc(当当)
2.Mycat
3.TDDL(淘宝)
4.Oceanus(58同城数据库中间件)
5.vitess(谷歌开发的数据库中间件)
6.Atlas(Qihoo 360)
分库分表可能遇到的问题
1.事务问题:需要用分布式事务啦
2.跨节点Join的问题:解决这一问题可以分两次查询实现
3.跨节点的count,order by,group by以及聚合函数问题:分别在各个节点上得到结果后在应用程序端进行合并。
4.数据迁移,容量规划,扩容等问题
5.ID问题:数据库被切分后,不能再依赖数据库自身的主键生成机制啦,最简单可以考虑UUID
七、limit 1000000 加载很慢的话,你是怎么解决的呢?
1.如果id是连续的,可以这样,返回上次查询的最大记录(偏移量),再往下limit
select id,name from employee where id>1000000 limit 10.
2.在业务允许的情况下限制页数:
建议跟业务讨论,有没有必要查这么后的分页啦。因为绝大多数用户都不会往后翻太多页。
3.order by 索引(id为索引)
select id,name from employee order by id limit 1000000,10
4.利用延迟关联或者子查询优化超多分页场景。(先快速定位需要获取的id段,然后再关联)
SELECT a.* FROM employee a, (select id from employee where 条件 LIMIT 1000000,10 ) b where a.id=b.id
八、查询语句执行流程?
查询语句的执行流程如下:权限校验、查询缓存、分析器、优化器、权限校验、执行器、引擎。
举个例子,查询语句如下:
select * from user where id > 1 and name = '冰冰';
1.首先检查权限,没有权限则返回错误;
2.MySQL8.0以前会查询缓存,缓存命中则直接返回,没有则执行下一步;
3.词法分析和语法分析。提取表名、查询条件,检查语法是否有错误;
4.两种执行方案,先查 id > 1 还是 name = '冰冰',优化器根据自己的优化算法选择执行效率最好的方案;
5.校验权限,有权限就调用数据库引擎接口,返回引擎的执行结果。
九、更新语句执行过程?
更新语句执行流程如下:分析器、权限校验、执行器、引擎、redo log(prepare状态)、binlog、redo log(commit状态)
举个例子,更新语句如下:
update user set name = '冰冰' where id = 1;
1.先查询到 id 为1的记录,有缓存会使用缓存。
2.拿到查询结果,将 name 更新为冰冰,然后调用引擎接口,写入更新数据,innodb 引擎将数据保存在内存中,同时记录redo log,此时redo log进入 prepare状态。
3.执行器收到通知后记录binlog,然后调用引擎接口,提交redo log为commit状态。
4.更新完成。
为什么记录完redo log,不直接提交,而是先进入prepare状态?
假设先写redo log直接提交,然后写binlog,写完redo log后,机器挂了,binlog日志没有被写入,那么机器重启后,这台机器会通过redo log恢复数据,但是这个时候binlog并没有记录该数据,后续进行机器备份的时候,就会丢失这一条数据,同时主从同步也会丢失这一条数据。
星辰大海,永不止步
END
,




