很多数据网站,对于反爬虫都做了一定的限制,这个如果写过一些爬虫程序的小伙伴应该都深有体会,其实主要还是IP进了小黑屋了,那么为了安全,就不能使用自己的实际IP去爬取人家网站了,这个时候,就需要采用代理IP去做这些事情……
为什么要用高匿代理我们可以对比不同类型的代理的区别,根据代理的匿名程度,代理可以分为如下类别:
- 高度匿名代理:会将数据包原封不动的转发,在服务端看来就好像真的是一个普通客户端在访问,而记录的IP则是代理服务器的IP。
- 普通匿名代理:会在数据包上做一些改动,服务器上有可能发现这是个代理服务器,也有一定几率追查到客户端的真实IP。
- 透明代理:不但改动了数据包,还会告诉服务器客户端的真实IP。
- 间谍代理:指组织或个人创建的用户记录用户传输的数据,然后进行研究、监控等目的的代理服务器。
Python运行环境:Windows python3.6用到的模块:requests、bs4、json如未安装的模块,请使用pip instatll xxxxxx进行安装,例如:pip install requests
爬取西刺代理IP

这里,我只大概爬取西刺高匿代理50页的数据,当然了,爬100页,爬全部,都是可以的,就不多说了;
def run(self):
"""执行入口"""
page_list = range(1, 51)
with open("ip.json", "w") as write_file:
for page in page_list:
# 分页爬取数据
print('开始爬取第' str(page) '页IP数据')
ip_url = self.base_url str(page)
html = self.get_url_html(ip_url)
soup = BeautifulSoup(html, 'html.parser')
# IP列表
ip_list = soup.select('#ip_list .odd')
for ip_tr in ip_list:
# 单条Ip信息
td_list = ip_tr.select('td')
ip_address = td_list[1].get_text()
ip_port = td_list[2].get_text()
ip_type = td_list[5].get_text()
info = {'ip': ip_address, 'port': ip_port, 'type': ip_type}
# 先校验一下IP的有效性再存储
check_res = self.check_ip(info)
if check_res:
print('IP有效:', info)
self.json_data.append(info)
else:
print('IP无效:', info)
json.dump(self.json_data, write_file)
复制代码
爬取到的代理IP可能不能用,为了方便使用的时候,不报太多异常错误,所以需要先检测一下IP是否能正常使用,是否是有效代理IP,我这里列了三个网站,都可以很方便的检测IP地址是否能有效使用
- icanhazip.com/ 这个网站能直接返回代理的IP地址
- www.ip.cn/ 查询到代理的IP地址和位置信息
- ip.chinaz.com/ 站长工具也能定位到IP地址和位置信息
def check_ip(self, ip_info):
"""测试IP地址是否有效"""
ip_url = ip_info['ip'] ':' str(ip_info['port'])
proxies = {'http': 'http://' ip_url, 'https': 'https://' ip_url}
res = False
try:
request = requests.get(url=self.check_url, headers=self.header, proxies=proxies, timeout=3)
if request.status_code == 200:
res = True
except Exception as error_info:
res = False
return res
复制代码
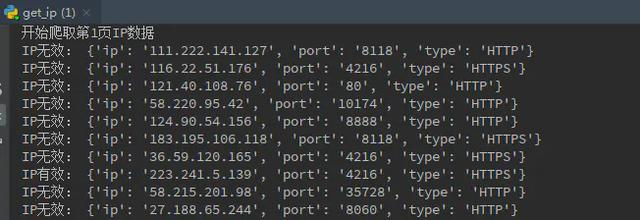
我这里就不搞那些花里胡哨的,我直接把所有有效的代理IP的json格式的数据存储到文件中,当然了,也可以存储到MongoDB或者MySQL数据库中,不管怎样存储,在使用的时候都是随机选取一个IP,更加方便快捷。
完整代码代码我已经上传了GitHub(GitHub源码地址),但是呢,作为一个热心的搬瓦工,为了方便部分人想偷懒,不直接去交友网站查看,我在这里也贴一下源码出来吧,如果有啥问题,最好还是去交友网站找我,请接码……
#!/usr/bin/env python
# -*- coding: utf-8 -*-
"""
利用requests bs4爬取国内高匿代理IP
author: gxcuizy
date: 2020-06-19
"""
import requests
from bs4 import BeautifulSoup
import json
class GetIpData(object):
"""爬取50页国内高匿代理IP"""
header = {'User-Agent': 'Mozilla/5.0 (Windows NT 6.1; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/83.0.4103.106 Safari/537.36'}
base_url = 'https://www.xicidaili.com/nn/'
check_url = 'https://www.ip.cn/'
json_data = []
def get_url_html(self, url):
"""请求页面html"""
request = requests.get(url=url, headers=self.header, timeout=5)
html = False
if request.status_code == 200:
html = request.content
return html
def check_ip(self, ip_info):
"""测试IP地址是否有效"""
ip_url = ip_info['ip'] ':' str(ip_info['port'])
proxies = {'http': 'http://' ip_url, 'https': 'https://' ip_url}
res = False
try:
request = requests.get(url=self.check_url, headers=self.header, proxies=proxies, timeout=3)
if request.status_code == 200:
res = True
except Exception as error_info:
res = False
return res
def run(self):
"""执行入口"""
page_list = range(1, 51)
with open("ip.json", "w") as write_file:
for page in page_list:
# 分页爬取数据
print('开始爬取第' str(page) '页IP数据')
ip_url = self.base_url str(page)
html = self.get_url_html(ip_url)
soup = BeautifulSoup(html, 'html.parser')
# IP列表
ip_list = soup.select('#ip_list .odd')
for ip_tr in ip_list:
# 单条Ip信息
td_list = ip_tr.select('td')
ip_address = td_list[1].get_text()
ip_port = td_list[2].get_text()
ip_type = td_list[5].get_text()
info = {'ip': ip_address, 'port': ip_port, 'type': ip_type}
# 先校验一下IP的有效性再存储
check_res = self.check_ip(info)
if check_res:
print('IP有效:', info)
self.json_data.append(info)
else:
print('IP无效:', info)
json.dump(self.json_data, write_file)
# 程序主入口
if __name__ == '__main__':
# 实例化
ip = GetIpData()
# 执行脚本
ip.run()
复制代码
最后,小编想说:我是一名python开发工程师,
整理了一套最新的python系统学习教程,
想要这些资料的可以关注私信小编“01”即可(免费分享哦)希望能对你有所帮助
,