在一些公司和企业中,特别是档案管理行业,经常会遇到将大批的扫描件转换成可以复制和检索的双层PDF或者是word文本的情况!下面就简单介绍一下:
首先这个过程是指,将纸质文件通过扫描仪快速扫描成图片后,经过OCR识别,然后可以直接生成可以检索的双层PDF文件。双层PDF文件是指文件内容既包含文本层,也包含图像层,且其位置上下一一相对应,这样,既可以100%保留原始版面效果(包括公章、签名),又可以通过下层的文字信息支持选择、复制、全文检索等功能。因此,双层PDF同时兼顾视觉效果和检索方便性,极大地方便了电子文件的管理,提高用户对文档的查询和利用。
这个将文件或图片转换成双层的PDF的过程,就需要一个必不可少的条件又或者说是技术——OCR文字识别!
首先我们需要一台扫描仪(平板或者高扫)需要将纸质的文件扫描成图片!

然后打开“快档通”OCR文字识别软件

在软件的左上角有个图像采集的按钮,这时我们可以选择导入或者扫描!导入的意思就是导入电脑上早已经扫描完的图片,扫描呢就是将手头上的纸质文件通过扫描仪扫描后再识别!
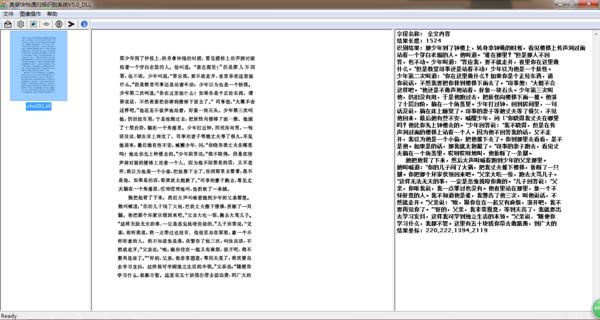
点击识别之后,识别出了结果,然后选择导出双层PDF就可以了,而且识别率可以高达98%以上!

下面就是识别导出后的双层PDF文件!

而且这个软件可以识别多种语言!

这款软件又分为标准版和普通版!标准版是针对普通用户的,不需要开发集成,买去可以直接使用的!而普通版是针对有集成能力的集成商的,软件需要开发集成才能用!
更多OCR产品及详情请点击此处!https://shop151858109.taobao.com/?spm=a1z10.1-c.0.0.lkHGQX
,




