第十二节梯度下降之背后的原理之泰勒公式(7)
我们接下来给大家深化一下,梯度下降背后到底是什么原理?谈到这个,我们要谈到一个叫泰勒展开的这么一个数学定理,泰勒发现任何一个函数不用管它有多复杂,不管它什么样,千奇百怪的任何一个函数,都可以写成关于N阶导数的一个多项式。即
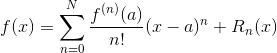
解释下,在A点附近,比如说A为1,那么在1附近,那么f(x)=f(1),你有个解析式,f(1)总能算出来,把1丢进去算出来,那么泰勒展开即:

f''是二阶导数,什么叫二阶导数?导函数再求一下导。这么一直这么往下加,加到余项为零的时候就加完了。假如余项始终不为零,它就一直无限这么加下去,加的项越多,这个函数越像原始的函数。
泰勒公式实际上用多项式函数去逼近一个光滑函数,什么叫逼近?因为它是把一个原始的函数拆成好多项了,那么拆项越多,这个加出来的结果就越像原函数。那好好的一个普通的函数,你为什么非得要给它拆成好多项呢? 一个X2 1,就两项很简单的,你为什么要给它变成N项?实际上不是所有的函数都是能这么写,比如sin X,在计算机里,实际上计算sin X背后的本质是它他先进行完了泰勒展开,展开成200 多项,然后把这200多项算出来,得到sin X到底是多少。这个是交给计算机计算的这么一种方式。再比如

此时我令a=0,就相当于在零点附近给它展开。如果按照刚才展开式来讲的话,零阶展开就是n等于0,
X轴是x=1,你发现0阶展开,如果把余项抛弃了的话,就是一条直线,这条直线像原函数吗?看起来不像。但在x=0这一点上的这条直线跟这个原函数很像。假如阶数增高的话,如图:






可以看到,随着阶数的升高,甚至仅仅到达十阶展开的时候,在我们肉眼可及的地方,它跟原函数已经非常接近了。零阶展开,如果就光说零附近的话,即使是零阶展开,在极小的区域里它也是比较像的,对吧?随着阶数越来越多,是不是离零越远的地方也越跟原函数很像了?这就是泰勒展开的本质。它实际上就是通过在某一点附近用一个多项式去逼近原来的原函数,你可以理解为它是一个原函数的近似取值。
回到我们梯度下降来说,我们梯度下降其实就是对原函数展开一个一阶泰勒近似。 假如对泰勒展开式在x0进行一阶泰勒展开,只得到两项。第一项就是f(x0),第二项就是(x-x0)f`(x0)。这个式子里谁是未知数?谁是已知数?可以发现只有x是未知数,剩下这些数虽然写的是字母,但实际上你带到真实的场景里,就能算出来是具体的数。假如此时的f是损失函数的话,在x0的值是可求的,x0点的导数也可求。这x0自然也是知道的,所以它的一阶泰勒的近似公式就是已经知道的了。
我们看梯度下降是怎么来的? 回到函数最优化问题上,如果我初始出来一组W0了,你想让W0加上λd这个东西之后带回到损失函数里,希望损失函数越小越好。也就是我们想要找到一个 λd 使上一代的 w λd后 损失函数下降得最多,即 min 0 。λ是学习率,d应该等于什么值?按照之前经验,d应该等于负的梯度才对。为什么d等于负梯度?我们来一步步推导。我们对E在w0附近进行一阶泰勒展开:

如果把0 入到上面的展开式里面也就是:
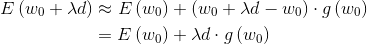
我们进行完一阶泰勒展开之后,我想要让损失函数:
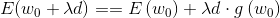
越小越好。看第一项E(0)能改变大小吗?它已经是一个既成事实了,λ是你人为定的,所以只有让d.g(0)越小越好。我们先回顾下向量点乘的几何含义:

也就是两个向量长度乘积再乘一个向量之间的夹角cosθ。所以

怎么让这结果最小,我们假设d向量长度变小一点,这样能让d*g(0)这项更小,但是你仔细想,d如果太大小了的话,一阶泰勒展开的不等号还能成立吗?因为我们只展开了一阶,阶数越高,越接近原函数,当d太小的时候,展开的函数是不是就远离原来的W0点了?远离W0点的时候,不等号是不是就不成立了?相当于去求一个跟损失函数不一样的函数的最小值,这是没有意义的。假设向量长度不变的话,那么怎么让它们相乘的结果越小越好?自然而然想到,让cosθ=-1的时候,结果就最小。那什么时候cosθ=-1?也就是θ等于180度的时候,也就是d向量应该跟原来的梯度向量成180度夹角,即当d向量等于负的梯度向量的时候,此时的夹角θ能使cosθ=-1,所以我们通常利用当d=-g(w0),此时的d向量和g(w0)之间的夹角为180度,这时d*g(0)就是最小的。这也就是为什么梯度下降每一步的迭代,加的那个东西就刚好是负梯度这么巧,是从一阶泰勒展开,一步步推导出来的。
总结下,梯度下降的本质是什么?对损失函数进行了一阶泰勒展开的近似,然后对这个近似出来的函数求最小值,把最小值当作下一步用来迭代的值。 这就是梯度下降背后的数学原理。
欢迎关注我的公众号LhWorld,不仅为你推荐最新的博文,还有更多惊喜和资源在等着你!一起学习共同进步!

,




