mysql 是日常的开发中常用的关系型数据库,除了 CRUD 之外的操作,mysql 也有很多有趣而且巧妙的操作,掌握这些技巧,可以在工作中得心应手、游刃有余。
在本文中会涉及以下内容:
- 1 mysql 字符串的操作,例如如何使用 concat 拼接更新语句以及 group_concat 的神奇用法。
- 2 mysql 中 select 的神奇用法, select 不仅可以用来执行 DQL,还可以用来查询变量和数学运算。
- 3 mysql 多列查询配合联合索引的正确用法, 比如 in 的多列查询操作。
- 4 涉及时间操作的一些函数和常用写法。
- 5 索引的创建和使用高阶用法,例如如何在 text 类型的字段上创建索引、如何强制使用索引等操作。
- 6 数据库的一些运维函数,查询数据库信息、引擎、表结构、索引、系统变量的常用函数。
在项目开发中相信大多数人都与 mysql 数据库打过交道,对于各种业务场景的数据库操作,都可以八仙过海各显神通。本 chat 另辟蹊径,从日常的数据维护和修复场景出发,展现出在 mysql 不常用,但是很有效且提升操作效率的方法。
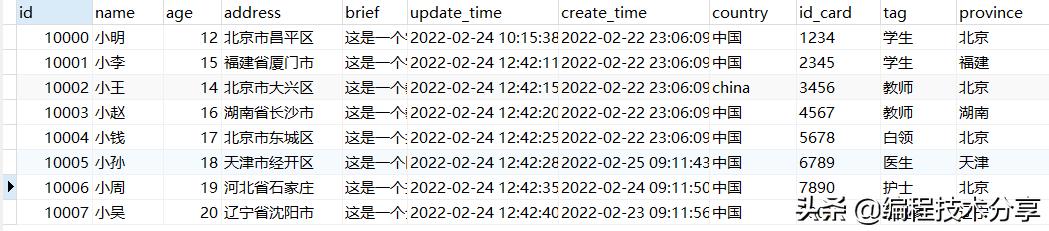
本 chat 中的数据操作采用如下表进行展示:
CREATE TABLE `tb_user` (
`id` int(11) NOT NULL AUTO_INCREMENT COMMENT '主键',
`name` varchar(255) DEFAULT NULL COMMENT '用户名称',
`age` int(11) DEFAULT NULL COMMENT '年龄',
`address` varchar(255) DEFAULT NULL COMMENT '地址',
`brief` text COMMENT '个人简介',
`update_time` datetime DEFAULT NULL ON UPDATE CURRENT_TIMESTAMP COMMENT '更新时间',
`create_time` datetime DEFAULT NULL COMMENT '创建时间',
`country` varchar(255) DEFAULT NULL COMMENT '国家',
`id_card` varchar(18) DEFAULT NULL COMMENT '身份证号',
`tag` varchar(20) DEFAULT NULL COMMENT '标签',
`province` varchar(30) DEFAULT NULL COMMENT '省份',
PRIMARY KEY (`id`),
UNIQUE KEY `uk_tb_user_id_card` (`id_card`) USING BTREE
) ENGINE=InnoDB AUTO_INCREMENT=10008 DEFAULT CHARSET=UTF8 COMMENT='用户信息表';
在介绍字符串操作之前,先提一个问题,一般情况下都会遇到修改线上数据的运维任务,此时大部分的手段就是提交 sql 变更。那么对于操作比较频繁的数据,比如账户信息表如果批量修改可能会造成表锁,导致服务不可用。此时就需要一条条的执行 sql 变更,那么如何快速拼写这些 sql 呢?大家思考一下自己常用的手段。
数据操作如下图所示:
第一个任务是将表中的年龄都加 1,这就用到了 mysql 字符串拼接函数 concat, 虽然这个不是最神奇的一个,但是确实是我工作中最常用到的一个。这里就直接给出答案:
# 这里使用了 concat 拼接函数
select concat("update tb_user set age = age 1", " where id = ", id,";" ) from tb_user;
执行后的结果如下图所示:

这里提一个稍微复杂的情况,将简介内容添加前缀 "个人简介:", address 修改为 address 和 conuntry 两个字段的拼接结果,其执行 sql 如下所示:
# 执行
select concat("update tb_user set brief = concat('","个人简介:' ,brief), address = concat( country , address)", " where id = ", id,";" ) from tb_user where id > 10003;
如图所示为最终的执行结果:

关于 concat 的使用方法,已经如前所示,还有一个类似的方法 concat_ws, concat(s1,s2) 等价于concat_ws("",s1,s2)
# concat_ws 即 concat width speator
select concat_ws("-","s1","s2")
展示结果如下图所示:

field(s,s1,s2...) 返回第一个字符串 s 在字符串列表(s1,s2...)中的位置。
乍一看这个方法没有什么用途,但这里提一个问题,如果查询结果要根据状态进行排序,排列顺序为 2 1 3 5 4 ,这个要怎么实现呢? 这就用到了 field 方法,因为返回的是字符串的下标那么实现起来就容易了:
select * from tb_user order by field(s,s1,s2...)
示例操作如下图,可以看出来确实是按照排列顺序进行了数据展示

length()、char_length() 和 character_length() 都是返回字符数, length() 是按照字节来统计的, 而后两者是根据字符来统计的,对于采用UTF-8 编码的中文来说,一个中文就是 3 个字节。 三者之间的区别如下图所示:

字符串分组拼接,这里说的就是 group_concat 方法,就是根据排序字段进行分组后,将组内的某列字段进行拼接。比如根据用户角色进行分组,展示用户角色下的所有权限。
# 1 mysql 分组的默认拼接符为逗号
select tag, group_concat(name) from tb_user group by tag;
执行结果如下图所示:

# 2 按照id 排序然后使用 - 进行拼接
select tag, group_concat(name order by id desc separator "-") from tb_user group by tag;
执行结果如下图所示:

# 3 使用 group_concat 来拼接 name 字段
select tag, concat("\"",group_concat(name order by id desc separator "\",\""),"\"") from tb_user group by tag;
执行结果如下图所示:

# 4 将 id 在 10000 和 30000 之间的数据进行拼接
select group_concat(id) from tb_user where id > 10000 and id < 30000;
执行结果如下图所示:

· 的用法在于分组,如果没有分组的话也是可以使用的。如果有某些后台的接口,需要根据 id 来修复数据,传入的参数一般都是 · 结构,这个时候直接在 · 平台上拼接好 id 参数,直接执行即可,省去了拼接的操作,如果是字符串类型的则参考第 3 条来执行。这里需要注意的是,拼接的长度是有限制的,超过长度的部分不会展示出来。
字符串的其它操作- 1 字符串倒序的方法。例如 select reverse("abcdef"),执行的结果就是字符串倒序。
- 2 字符串去空格 trim(s), 顾名思义就是去除字符串左右两边的空字符串,对应的还有 ltrim 和 rtrim,分别是去除左边和右边的空格。
- 3 字符串复制,select repeat('12',3) 即将字符串进行复制几遍,示例的结果就是 121212。
- 4 字符串的截取。substr("abcdef", 1, 3),从 1 开始截取长度为 3 的字符串。
- 5 字符串比较,strcmp("111","222") 相等返回 0, 否则根据返回 1 或者 -1 ,这个和 java 字符串比较的结果是类似的。
- 5 字符串大小写转换。 ucase(s) 和 upper(s) 都是将字符串转为大写,lcase(s) 和 lower(s) 都是将字符串转为小写。
列举了这么多,还以为 mysql 只是一个数据库那么简单吗,mysql 的知识分为两个部分,一部分是数据的存储,而另一部分则是 sql 语法,sql 其实是和 java 、python 一样的,也是一门开发语言。
数字的操作关于数字的操作,除了在开发中常用的聚合方法, sum, max ,min, avg 之外,还有字符串的格式化展示,四舍五入的操作。具体的函数方法如下所示:
# format(x,n) 格式化数字并四舍五入保留相应的位数,形式为 "#,###.##"
# 格式化两位后的数字为 12,45.35
select format(12345.345,2)
# round(x,n) 四舍五入保留小数
# 四舍五入后为 12345.35
select round(12345.345,2)
# 数字格式化,不会进行四舍五入
truncate(x,n)
# 指数运算
pow(x,y)
# 数据取整操作
floor(1.3) 向下取整取值,结果为1
ceiling(1.3) 向上取整取值,结果为2
对于日期的操作,也是经常使用的,比如获取当前的时间为 select now()。
# 格式化数据时间 date_format(d,f)
select date_format('2022-02-22 11:11:11','%Y-%m-%d')
2022-02-22
# 返回连个时间之间的相隔天数
datediff(d1,d2)
# date_add/date_sub 函数从日期减去、加上指定的时间间隔
# 其基本的表达式为 date_sub(date, interval expr type)
# 其下两个方法的含义是查询2天前的日期和3天后的日期
select date_sub(now(),interval 2 day)
select date_add(now(),interval 3 day)
# 日期部分的操作,分表获取小时数、天数、月份、年份和季度数据
hour(date)
day(date)
month(date)
year(date)
quarter(date)
# 一周的中周几,从周日开始算一周的第一天
dayofweek(date)
# 日期为当年的第几周
week(date)
select 在日常的工作开发中大家只是用来查询表数据的结果,但是小编想说的是,select 可不仅仅是这样一个单调的用途。
select 可以用来查询函数的运算结果,这个在前文中已多次使用,比如 select reverse("abcdef");除此之外,select 还可以用来四则运算,比如 select 1 2 。
# if 判断操作,age 大于 15个返回 address,其他的返回 country,这里在查询数据时需要简单的逻辑判断时可以使用
select if(age > 15, address , country ) as 'result' from tb_user
# 如果结果为null,给出计算的默认值
select ifnull(sum(age),0) from tb_user
执行结果如图:

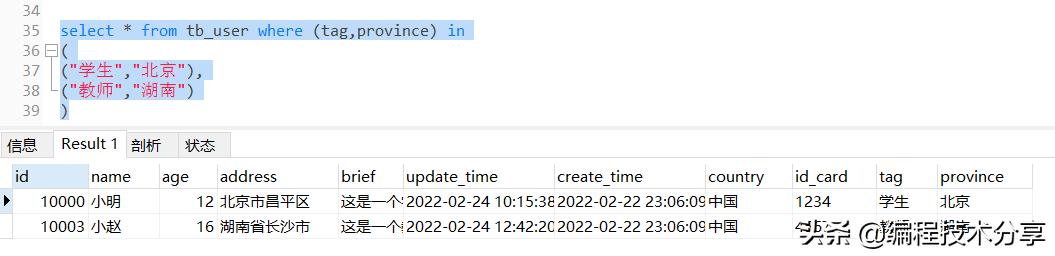
在日常的开发工作中,在查询数据时通常会遇到这样的情况,根据并列的两个或者多个条件查询多条数据,以前文讲述的数据表为例:
# 根据标签和省份批量查询数据,查询条件如下所示:
tag = "学生" and province = "北京"
tag = "教师" and province = "湖南"
最终实现的sql 语句如下所示:
select * from tb_user where (tag,province) in
(
("学生","北京"),
("教师","湖南")
)
执行结果如图所示,满足查询要求:
当然多列的查询也可以使用 (tag = "学生" and province = "北京") or (tag = "教师" and province = "湖南") 的方式来实现,但是这样的拼接不如上图展示的优雅,而且这个样多列 in 查询也是可以使用索引的,不会影响查询数据的效率。
数据先查询再操作在日常的开发任务中,经常会遇到这样的情况,要往数据库中插入数据,为了避免重复的插入,会根据某些唯一键先去数据库中查询,然后根据返回的结果判断是更新、忽略还是删除后插入。我们通常是按照两个步骤或者三个步骤来操作的,这里给大家说一下,其实这些需求可以根据一条 sql 搞定的。
- 1 数据存在则忽略更新。insert ignore into,如果插入的数据会导致 unique 索引或 primary key 发生冲突,则忽略此次操作不会插入数据。
- 2 数据存在则删除旧数据插入新数据。replace into 如果插入的数据会导致 unique 索引或 primary key 发生冲突,则先删除旧数据再插入最新的数据。
- 3 数据存在则更新数据。on duplicate key update 如果插入的数据会导致 unique 索引或 primary key 发生冲突,则执行执行更新操作。这样的操作在插入和更新数据时都可以使用。
# 其格式如下图所示,分别是忽略更新/删除后重新插入/重复更新的 sql 模板
insert ignore intao table_name ...
replace intao table_name ...
insert into table ... on duplicate key update fieldd1 = value1,fieldd2 = value2
在数据库查询中,经常会使用到索引,但是对于大字段如何创建索引呢,这是一个问题。
在实践中,可以使用全文索引来提高查询效率,常用的索引有 normal / unique/ fulltext 等,但是如果使用 mysql 全文索引还不如使用 ES 来的更快速一些,这样的话就引出了对大字段加索引的方法,不需要全部都加这样会比较占用空间,字需要加一部分的索引长度即可,
# 对 address 字段建立索引,并且只对前100的长度建索引
alter table tb_user add index `uk_tb_user_address`(`address`(100)) using btree;
这个是一种方法,对于 url 类型的字段十分有效,因为 url 只有后半部分的区分比较大,所以在存储和查询时对内容进行倒序排列,这样区分度大的就在字段前面,其区分度大大增加。
另外在查询数据时,对于使用索引,可以使用 force index 的当时强制使用某个索引,以提高索引效率,这个是在优化环节 mysql 使用索引错误的情况下经人工介入才可以使用。其使用方法为:
# 强制使用 uk_tb_user_id_card 索引时使用了全表扫描, type = all
explain select * from tb_user force index(uk_tb_user_id_card) where id = "10000"
# 默认情况下的执行计划使用了主键索引,type = const
explain select * from tb_user where id = "10000";
以上只是强制使用索引,在正常的 sql 查询中,mysql 会基于成本和时间优化选择合适的索引,在复杂的情况下如果需要强制走某个索引可以采用该方法。
mysql 的一些其它操作以下是常见的数据库操作命令,在日常的运维过程中有着重要的作用,大家有时间可以实操一下,命令也比较简单,就不展示查询的结果了。
# 查询数据库名称
select database()
# 查询数据库的版本信息
select version()
# 展示数据 innodb 的引擎信息
show variables like "%innodb%"
# 展示数据库中的表信息
show table like "tb_%"
# 展示数据库中的表结构信息
desc table_name
# 展示数据库表的创建信息 ddl 语句
show create table tb_user
# 查询当前数据库状态
show status
这里重点说一下 show processlist 命令,这个命令能够查询当前数据库的连接信息,类似于在 linux 中查看正在运行的进程,那么既然可以查到对应的进程,那么就可以杀死对应的进程,这在数据库死锁或者故障慢查询中可以使用,但仅限于开发和测试环境,线上环境还是要慎重的。 查询命令如下图所示,如果要杀死进程,使用 kill Id 号即可。

Id 进程号
User 连接数据库的用户
Host 对方的地址信息
db 使用的数据库信息
Command sleep 代表休眠,Query 表示进行中
Time 这个要和Commnad 结合来看,时间长的一般情况下就是异常
State 当前的任务状态
Info 执行的sql 信息
在本 chat 中,从日常工作中常用的操作出发,采用问题的方式递进延伸 mysql 的知识点,从简单查询到巧妙的函数操作,一切的目的都是为了减轻工作量,提高查询的效率。特别是 concat 和 group_concat 函数,还有数字和日期的操作,以及最后的 in 多列查询,最值得回顾的是数据先查询再操作的三种方式,从 sql 层面减轻了工作量。
,