一.文件操作
文件是指存储在外部介质上数据的集合,文本文件编码方式包括ASCII格式、Unicode码、UTF-8码、GBK编码等。文件的操作流程为“打开文件-读写文件-关闭文件”三部曲。
1.打开文件
打开文件调用open()函数实现,其返回结果为一个文件对象,函数原型如下:
<variable> = open(<name>, <mode>) -<name>表示打开文件名称 -<mode>表示文件打开模式其中mode常见参数包括:
- r: 只读,文件指针将会放在文件的开头
- w:只写,如果文件已存在则打开文件,并从开头开始编辑,即原有内容会被删除;如果该文件不存在,创建新文件
- a: 打开一个文件用于追加,如果该文件已存在,文件指针将会放在文件的结尾;如果该文件不存在,创建新文件进行写入
- rb: 只读二进制文件,一般用于非文本文件如图片等
- wb: 只写二进制文件,一般用于非文本文件如图片等
- ab: 以二进制格式打开一个文件用于追加
- w+: 打开一个文件用于读写
open()函数的完整语法如下:
- open(file, mode=‘r’, buffering=-1, encoding=None, errors=None, newline=None, closefd=True, opener=None)

举一个简单的例子:
infile = open("test.txt","r")注意:使用open()方法一定要保证关闭文件对象,即调用close()方法。
2.读写文件
(1) 读文件
常用文件读取方法包括:
- read()返回值为包含整个文本内容的一个字符串
- readline()返回值为文件内容的下一行内容的字符串
- readlines()返回值为整个文件内容的列表,列表中每项为一行字符串
示例如下:
infile = open("test.txt","r",encoding="utf8")data = infile.read()print(data)print(")infile = open("test.txt","r",encoding="utf8")list_data = infile.readlines()print(list_data)输出结果如下图所示:

(2) 写文件
从计算机内存向文件写入数据,方法包括:
write()把含有文本数据或二进制数据集的字符串写入文件中
writelines()针对列表操作,接收一个字符串列表参数,并写入文件
outfile1 = open('test.txt','a+',encoding="utf8")str1 = 'nhellon' str2 = 'worldn'outfile1.write(str1) outfile1.write(str2)outfile1.close() outfile2 = open('test02.txt','w',encoding="utf8")outfile2.writelines(['hello',' ','world']) outfile2.close()infile = open('test.txt','r',encoding="utf8")data = infile.read()print(data)针对test.txt文件完成追加写入操作,针对test02.txt文件完成新建及写入操作,同时调用write()和writelines()不同方法写入数据。
3.关闭文件
文件读写结束后,一定要记住使用close()方法关闭文件。如忘记使用该关闭语句,则当程序突然崩溃时,该程序不会继续执行写入操作,甚至当程序正常执行完文件写操作后,由于没有关闭文件操作,该文件可能会没有包含已写入的数据。为安全起见,在使用完文件后需要关闭文件,建议读者使用try-except-finally异常捕获语句,并在finally子句中关闭文件。
try: #文件操作except : #异常处理finally: file.close()其他方法包括:



- file.flush():刷新文件内部缓冲
- file.next():返回文件下一行
- file.seek(offset[, whence]):设置文件当前位置
- file.tell():返回文件当前位置
- file.truncate([size]):截取文件,截取的字节通过size指定
4.循环遍历文件
在数据爬取或数据分析中,常常会涉及到文件遍历,通常采用for循环遍历文件内容,一方面可以调用read()函数读取文件循环输出,另一方面也可以调用readlines()函数实现。其两种方法的对比代码如下所示:
infile = open('test02.txt', 'r', encoding="utf8")for line in infile.readlines(): print(line)print(infile.close())infile = open('test02.txt', 'r', encoding="utf8").read()for line in infile: print(line)print(infile.close())输出结果《静夜思》如下图所示,包含TXT文件和输出值。
二.CSV文件操作
我们在使用Python进行网络爬虫或数据分析时,通常会遇到CSV文件,类似于Excel表格。接着我们补充SCV文件读写的基础知识。
CSV(Comma-Separated Values)是常用的存储文件,逗号分隔符,值与值之间用分号分隔。Python中导入CSV扩展包即可使用,包括写入文件和读取文件。
1.CSV文件写
基本流程如下:
- 导入CSV模块
- 创建一个CSV文件对象
- 写入CSV文件
- 关闭文件
# -*- coding: utf-8 -*-import csvc = open("test-01.csv", "w", encoding="utf8") #写文件writer = csv.writer(c)writer.writerow(['序号','姓名','年龄']) tlist = []tlist.append("1")tlist.append("小明")tlist.append("10")writer.writerow(tlist)print(tlist,type(tlist)) del tlist[:] #清空tlist.append("2")tlist.append("小红")tlist.append("9")writer.writerow(tlist)print(tlist,type(tlist)) c.close()输出结果如下图所示:

注意,此时会出现多余空行,我们需要进行简单的处理,加入参数“newline=‘’”解决。
- c = open(“test-01.csv”, “w”, encoding=“utf8”, newline=’’)

2.CSV文件读
基本流程如下:
- 导入CSV模块
- 创建一个CSV文件对象
- 读取CSV文件
- 关闭文件
# -*- coding: utf-8 -*-import csvc = open("test-01.csv", "r", encoding="utf8") #读文件reader = csv.reader(c)for line in reader: print(line[0],line[1],line[2])c.close()输出结果如下图所示:

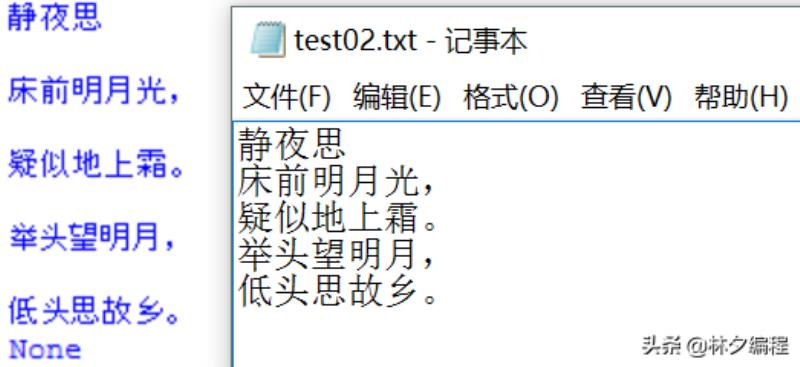
在文件操作中编码问题是最让人头疼的,尤其Python2的时候。但只需要环境编码一致,注意相关转换也能有效解决,而Python3文件读写操作写清楚encoding编码方式就能正常显示。如果是数据库、网页、后台语言,三者编码方式需要一致,比如utf8或gbk等,具体问题具体解决吧!后续作者会结合爬虫讲解CSV文件的操作。
三.面向对象基础
传统的编程方式是面向过程的,根据业务逻辑从上到下执行,而面向对象编程是另一种编程方式,此种编程方式需要使用“类”和“对象”来实现,将函数进行封装,更接近真实生活的一种编程方式。
面向对象是将客观事物看做属性和行为的对象,通过抽象同一类对象的共同属性和行为,形成类,通过对类的继承和多态实现代码重用等。对象(Object)是类(Class)的一个实例,如果将对象比作房子,那么类就是房子的设计图,并在类中定义了属性和方法。
面向对象的三个基本特征为:
- 封装:把客观事物封装成抽象的类,类中数据和方法让类或对象进行操作。
- 继承:子类继承父类后,它可以使用父类的所有功能,无需重新编写原有类,并且可以对功能进行扩展。
- 多态:类中定义的属性或行为,被特殊类继承后,可以具有不同的数据类型或表现不同的行为,各个类能表现不同的语义,实现的两种方法为覆盖和重载。
在Python中,类就是一个模板,模板里可以包含多个函数,函数里实现一些功能;对象则是根据模板创建的实例,通过实例对象可以执行类中的函数。如下:
#创建类class 类名: #创建类中的函数,self特殊参数,不能省略 def 函数名(self): #函数实现 #根据类创建对象objobj = 类名()假设需要编写一个计算长方形面积和周长的程序,其思想是定义两个变量长和宽,然后再在类中定义计算面积和周长的方法,实例化使用。代码如下:
#-*- coding:utf-8 -*-class Rect: def __init__(self, length, width): self.length = length; self.width = width; def detail(self): print(self.length, self.width) def showArea(self): area = self.length * self.width return area def showCir(self): cir = (self.length + self.width) * 2 return cir#实例化rect1 = Rect(4,5)#调用函数rect1.detail()area = rect1.showArea()cir = rect1.showCir()print('面积:', area)print('周长:', cir)输出结果面积为20,周长为18。对于面向对象的封装来说,其实就是使用构造方法将内容封装到对象中,然后通过对象直接或者self间接获取被封装的内容。

整体而言,面向对象是站在事物本身的角度去思考解决问题,如果上面采用面向过程定义函数的形式实现,当出现多个形状时,你需要对每一种形状都定义一种方法,而面向对象只需把这些形状的属性和方法抽象出来,形成各种形状,更符合真实情况。
注意:为了更简明快速的让读者学习Python数据爬取、数据分析、图像识别等知识,本系列中的代码很少采用定义类和对象的方式呈现,而是直接根据需要实现的功能或案例,直接编写对应的代码或函数实现。这是不规范和不合理的,在实际开发或更加规范的代码中,更推荐大家采用面向对象的方法去编程,但本系列更想通过最简洁的代码告诉你原理,然后你再去提升和锻炼自己的能力。
设计模式中的面向对象
再举个例子:为了方便儿童学习编程,X公司开发了一套Racing Car模拟器,使用这个模拟器每个孩子都可以用一种简单的语言来控制一辆赛车,例如right、left等。请设计一种简单的语言,给出它的语法以及该语言的类图。
这就是我们实际编程中联系到生活的问题,它涉及到了设计模式相关知识,其中我采用的方法是“命名模式”实现的,客户端是定义Children和Car,请求者是Children发出的Right、Left、Up、Down命令,接受者是Car执行Move(),抽象命令是上下左右的抽象接口,具体命令是Car的上下左右。我制作的类图如下:
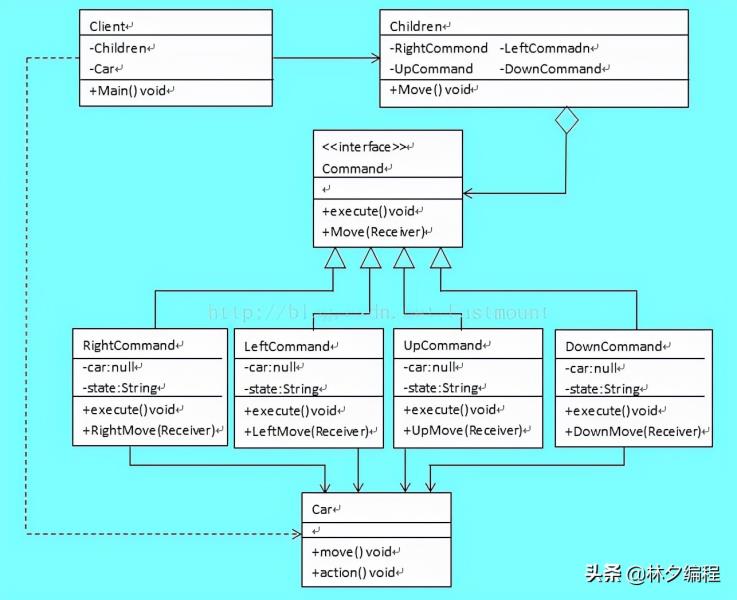
在这个例子中,我们使用了面向对象的思想,站在事物本身的角度去思考解决问题,而不是面向过程定义函数的形式实现。如果又出现一个空陆两地车,它不仅能上下左右移动,还能飞行,传统的方法还需要再写四个上下左右移动的方法,而面向对象直接继承Car,补充一个飞行新方法即可(不含方向),这就是面向对象的好处。
同样,通过这个例子我不是想证明所采用的命令模式或画的类图是否正确,我想阐述的是我们学习面向对象知识主要是用来解决实际生活中的问题,让它更加高效地解决问题和优化代码。同时,面向对象思想要适应需求的变化,解决用户的实际需求,在设计时就要尽量考虑到变化,会涉及到抽象、封装变化(重点)、设计模式等知识。
四.总结
无论如何,作者都希望这篇文章能给您普及一些Python知识,更希望您能跟着我一起写代码,一起进步。如果文章能给您的研究或项目提供一些微不足道的思路和帮助,就更欣慰了。作者最大的期望就是文章中的一些故事、话语、代码或案例对您有所帮助,致那些努力奋斗的人。