语音技术的发展,将会给我们的产品设计带来极大的改变。未来的产品方向,或者说是人机交互的方式,极可能是视觉与听觉的更加立体的交互,我们会有机会来设计一种完全不一样的用户体验,和完全不同的产品认知。
一、什么是VUI?
作为新一代的交互模式,通俗的说,VUI(语音用户界面)就是用人类最自然的语言(开口说话)给机器下达指令,达成自己的目的的过程,这一过程包括三个环节:
能听、会说、懂你。
VUI是一种以人类内心意图为中心的人机交互方式,以交谈式为核心的智能人机交互体验。
最典型的应用就是语音助手,当下最热门的产品就是智能音箱了。
二、语音交互有什么优势?
- 输入更高效。研究结果表明,语音输入比键盘输入快3倍。如果你从解锁手机到设置闹钟需要两分钟,直接说一句话设置闹钟,可能只需要10秒钟;
- 表达更自然。人类是先有语音再有文字,每个人都会说话但有一部分人不会写字,语音交互比界面交互更自然,学习成本更低;
- 感官占用更少。一张嘴,将人的双手、眼睛从图形界面交互中解放出来,想象一下当你手握方向盘时,说一句话就直接接听电话、播放音乐,是不是更方便也更安全。腾出来的感官,意味着可以并行处理其他任务,理论上有更高的效率。
- 信息容量更大。语音中包含了语气、音量、语调和语速这些特征,交流的双方可以传达大量的信息,特别是情绪的表达,其表达的方式也更带有个人特色和场景特色。当见不着面,听不到声音的时候,人与人之间的真实感就会下降很多。
VUI不再依赖固定的路径完成操作指令,而且是每个人都可以有自己的方式和特色。
这是VUI与GUI革命性的改变。
对今天的App、浏览器而言,其直接下达指令的特性,使得语音交互可能成为一个全新的、去中心化的超级入口,也正是因为此,彻底引爆了整个市场。
从“百团大战”之后,我们又见到了“百箱大战”。
三、语音交互存在什么障碍?
语音百般好,应用一时难。
语音交互走到今天,已经付出了非常大的努力,但依然是有多少人工,就有多少智能。
“智能”与“智障”之间,隔着一线天。
当然,对从业者来说,当下的语音交互认为应该处于一种“没有想象的那么好,也没有想象的那么差”的境地。
1.注意力障碍
语音交互是非可视化的,带来的问题就是增加人的记忆负担。你打过银行的客户电话就知道,你必须集中精力听完语音播报之后才能做下一步动作,如果你比较着急的话,那你就会非常的难受。事实上,人在获取信息的适合,视觉要强过听觉。
别人讲话时你可能要等他说完你才理解,而你看文字的时候,甚至可以直接跳过部分文字你也能理解,特别是中文。所以,音箱添加屏幕是趋势。对于语音的效率问题,可以说是单方面的输入更高效,而双向互动反而效率不高。
或者说,获取信息的时候,视觉有很大的优势,而声音的效率并不高(现实中为什么总会出现“打断”对话的现象,就是因为语音的表达效率不高,听者等不及)。
2.心理障碍
想象一下你晚上一个人在家,你会不会突然开口叫一句”小明小明,明天什么天气?”莫名其妙的语音,会让人感到一丝不自在,特别是一旦小明存在一定缺陷的时候,所引发的错误。从心理感受出发,没有多少人愿意对着冰冷的机器说话,然后得到毫无感情的甚至是错误的回应。语音交互存在的另一个心理障碍是,语音交互的不可预设和预判性。
不同的人,在同样的情境下都可能产生完全不同的行为和预期。这给设计者来说带来很大困扰,也为用户带来不确定性的担忧。
在面对不可预知的状况下,设计者和使用者互相难以领会彼此的意图,就会形成一种博弈消耗。
为了应对这种不确定性,可能导致系统必须通过更多的场景理解和上下文关系,去解析用户的意图来做出可能合理的信息反馈,这将进一步带来技术的复杂度。
3.技术障碍
语音交互为什么如此受到期待,是因为太富有想象空间了,能够让我们尽可能的释放被占用的感官。想象一下,你只说一句“订一箱牛奶”,快递就会在约定好的时间送过来,多美好的生活。现实生活中,人与人的交流,甚至一个眼神一个动作就可以引起对方的注意和反馈。
而现阶段的智能音箱需要定义一个将助手从待机状态切换到工作状态的词语,即所谓的“唤醒词”,这是一个不得已而为之的蹩脚设计,你想做什么之前都要先来一句“小明小明”,这种叠词的对话方式特别让人反感。
实际上,语音交互的技术依然存在巨大挑战,还很难在复杂的环境和不确定的情景下,真实的理解用户的行为和意图,想要给出用户在不同场景下的期望值,软硬件技术都还有漫长的路要走。
今天的语音交互,在某些场景下,本身就是一种劣势。比如你站在电视机旁边,开关机这个动作最适合的交互应该是手——直接一按就可以解决,为什么还要开口说话?
这一点说明:不是什么设备都可以加一个屏幕,也不是什么什么都可以加一个麦克风。
语音交互是否能够广泛应用,有赖于对场景的深度理解,以及人能智能技术的进步。
语音交互好不好,不仅仅依赖硬件设备的识别准确率,更需要垂直场景下的语义理解,以及后端内容服务的连接。
四、语音交互能否取代图形界面?
结论是:语音和图形交互不存在取代,就像人的眼睛和耳朵一样。
不得不感叹造物主的神奇,千百万年来的进化,给了我们这样一个绚丽多姿的世界。
人类耳听、眼观、嘴说、手动的自然构造,说明适应环境最好的方式就是分工合作,协同感知和应对环境,并作出最合适的行为反馈。
所以,最符合于人类的人机交互体验,就是在不同的场景由不同的器官(方式)来完成,以一种自然的与外界进行信息交互。
随着技术的进步,交互的方式定将发生颠覆式革新,未来的人机交互将更趋向于立体和本能。GUI VUI,是一对有机的结合体,因为它符合人类的本能,语音交互不是取代触摸交互的升级,二者之间只会彼此共同促进,通过恰当的协作机制提供更好的用户体验。
但,我们需要清晰的理解二者之间存在着本质性差异:
- GUI是一种预设路径的交互方式,通过识别用户的下滑、点击、双击等交互行为以及用户所处的页面位置,判断用户的指令并作出准确的反馈。这是一种单一路径的操作方式,但足够清晰。
- VUI聚焦于如何发挥语言和表意的强大力量,采用人们日常的语言来交流,真实,自然的表达和获取反馈,获取用户的信任、传递信息。
语音交互的流程更加直接,用户甚至可以发出不同的语音指令来期望获得同一个反馈。
五、语音交互的未来会变成怎样?
1.无处不在
想象一下你在家里,最好的方式一定是不管你在那个房子,你都可以说一句“小明,明天送一箱牛奶”,而不是非要找到某一个音箱设备才能下达指令。
也就是未来的语音助手,一定是移动的,或者说是无处不在。
同时,借助一系列的传感设备,从声音纹路、体征指标、环境指标,综合评估和理解当下的真实环境,并给初恰当的反馈。
2.主动服务
现在所有的语音助手,都还是被动地交谈,你必须给出命令,它们才会应答。
但想像一下未来,当深度学习和大数据已经做好了充足的准备,语音助手能预知你接下来要去哪,要见什么人,甚至在想什么,只需要用语音的方式输出这些信息。你不再需要点亮手机去查看这些智能的提醒,随时随地,会有一个声音和你主动交谈。
也许,未来技术的发展,各种穿戴设备,甚至植入体内的芯片会带给我们完全不同的与外界交互的途径。
但以当下我们对自身的理解,人的获取外界信息和表达内在情绪的感官体验,依然无法被取代。
六、什么场景适合使用语音交互?
语音交互同互联网诞生以来用户就习惯的GUI界面交互相比,主要是输入方式不同导致的,最显著特性就是“解放了双手”——你在使用语音请求时,眼睛和手可以同时忙于其他的事情,从这点出发,语音交互在家居和出行领域有天然的优势。
- 家居:在家庭“相对封闭与安全”(特指针对语音信号采集的干扰程度),通过语音交互指令控制家居开关是很好的切入点。相信在不久的将来,搭载了语音交互系统的智能家居,都可以听你的话,你说所说的每个指令,都会直接影响/控制到当前家居的运行状态。“你可能越来越惬意,也可能越来越懒……”
- 出行车载语音交互系统:释放了驾驶员的手和眼,让司机专注于前方的路况,如接听电话、开关车窗、播放广播音乐、路线导航等语音交互指令。
- 企业应用:未来会有各种各样专业的知识工作者会在或大或小的程度被简化或者被替代,比如文本、数据的录入工作,比如客服机器人。但,极不太可能的是直接对着一个设备吼两嗓子做一个PPT的方式。
- 医疗&教育:如语音记录病历,不管对医生来说还是患者来说,都是提高看病效率的很好的辅助手段之一。
以目前的技术条件而言,单向的指令性动作是最适合语音来表达的,因为它足够清晰和直接。
七、语音交互涉及那些技术?
VUI(语音用户界面)所涉及的技术模块有 4 个部分,分别为:
- 自动语音识别:Automatic Speech Recognition, ASR
- 自然语言理解:Natural Language Understanding, NLU
- 自然语言生成:Natural Language Generation, NLG
- 文字转语音:Text to Speech, TTS
上图即为语音交互技术包括的识别、理解和对话三个部分。
整个过程通俗的说,就是通过麦克风让机器能听到用户说的话,然后听懂用户想要表达的意思,并把反馈的结果“说给用户听”。
举个例子就是:
小明:明天什么天气?
助手:晴,37摄氏度。
整个过程分解之后,就变成这样一个过程:
- 小明对着机器说一句话后,机器内置的麦克风识别到小明说的话,把口语化的文本归一、纠错,并书面化(ASR);
- 然后机器根据文本理解小明的意图(通常是在云端进行语义的理解)并进入对话管理,当意图不明确时,还需要机器发起确认对话,继续补充相关内容,这就是多轮对话;
- 在明确小明意图后,去获取相关的数据,或者执行相关的命令;
- 最后把内容通过扬声器播放给小明听(TTS,语义理解后获得的结果文本信息合成为声音)。
至此完成一个完成对话过程。(实际上,也是一个蛮晦涩的过程)
在上述的四个环节,都很关键,都存在很大的技术挑战。
值得特别提出来的是ASR和NLU两个环节。
ASR是通过声学模型和语言模型,将人的语音识别为文本的技术。
它依赖麦克风本身的性能和设计,如何确保在复杂的现实环节下,把干扰信息过滤,获取到准确的信息,我们场景的智能音箱,通常都是多个麦克风组成一个环形的设计,目的就在提供获取语音的准确率。
语音识别只是知道我们说了什么,但真正要理解我们说的是什么,就需要依靠 NLU 这项技术。主要解决分词、词性标注、实体识别、文本分类和情感分析这几个问题。
比如:
从北京飞上海要多久?
到广州呢?
上例中,实际上就是试图通过一个框架模型解析一句话的意图。
目前为止最成功的”框架语义(Frame Semantics)”,即采用领域(Domain)、意图(Intent)和词槽(Slot)来表示语义结果。
- 领域(Domain):领域是指同一类型的数据或资源,以及围绕这些数据或资源提供的服务。比如“天气”、“音乐”、“酒店”等。
- 意图(Intent):意图是指对于领域数据的操作,一般以动宾短语来命名,比如音乐领域有“查询歌曲”、“播放音乐”、“暂停音乐”等意图。
- 词槽(Slot):词槽用来存放领域的属性,比如音乐领域有“歌曲名”、“歌手”等词槽。
举个例子,从“北京明天天气怎么样”这句话中,NLU 可以得到以下语义结果:
- 领域(Domain):天气
- 意图(Intent):查询天气
- 词槽(Slot):
城市(city) = 北京
时间(date) = 明天
我们再通过问天气的例子,来理解要完成一个对话的过程:
小明:明天天气怎么样?
助手:您要查询哪个城市的天气?
在这个例子中,语音助手试图获取更完整的领域、意图和词槽数据,也就是语音助手在对话开始后,会结合本轮对话提供的语义信息和上下文数据,确定当前对话状态,同时会补全或替换词槽,并且根据对话状态和具体任务决定要执行什么动作,比如进一步询问用户以获得更多的信息、调用内容服务等。
这里的三个核心就是对话的上下文、对话的状态跟踪以及采取的对话策略,组成DM(对话管理),并最终把获取的文本结果,合成为人耳听到的声音(TTS)。
Q:明天天气怎么样?(intent=query_weather,date= 明天,city=null )
A:您要查询哪个城市的天气?(action= 询问查询哪个城市)
在回顾语音交互的全流程,可以看到它的核心就是用户的意图,如何识别意图以及如何处理意图。
换句话说,语音是完全以用户为出发点的技术,而图形交互更多的是让用户在引导下完成指定的任务。
也从这个特性可以看到,语音交互远比图形交互技术复杂,不同的语种会带来不同的词法、句法,然后在不同的语境下有着完全不同的语义(意图)。
随着技术的发展,机器结合更多的传感器技术和生物识别技术,它能感知人们的语音、肢体和手势甚至表情眼神,并通过调整自身的反馈来适应人们那一刻提出的需求(包括脾气性格、声音特点、外外貌印象),真正实现人机的自然(本能)交互。
八 、语音交互设计需要遵循什么原则?
语言学家Paul Grice 在1975年提出关于人们交际的4点合作原则,即:
- 量的准则:既要让人听懂,又不要说太多废话。尽量少添加不必要的措辞,比如用户问什么天气,直接回答“广州,晴”即可。
- 质的准则:说真话,没有证据的话不要说。如果你的语音助手只可以问天气,就不要被唤醒后说“有什么需要帮忙的”,当用户被引导而不能达成,只会给用户一种挫败感。
- 关系准则:不要前言不搭后语,说话要有联系。
- 方式准则:清晰明了,井井有条不要拐弯抹角也就是,我们所设计的语音助手,不要说自己做不到的事情,比如“有什么可以帮助到你?”,这显然就是超乎能力范围了。
也不要在没有弄明白意图的时候,随意强行反馈结果。
然而,人们在实际言语交际中,却常常故意违反合作原则,特别是中国人所说的“话里有话”,如何透过说话人话语的表面含义而理解其言外之意的,对语音交互设计而言,是极其巨大的挑战。
但,幽默也就时常在这时产生。
九、如何设计语音交互产品?
如同GUI(图形用户界面)以点击-触发为各个节点的交互逻辑一致,VUI(语音用户界面)是从提问到回答的流转过程逻辑,将一个场景以对话的形式贯穿起来。
回想在GUI时代,我们如何为用户设计一个功能。
通常,我们都需要理清楚需求的边界,做什么不做什么,然后把用户的需求做一个流程的梳理,把各个环节的流转以及可能出现的状况状态完整的表达出来,然后制作原型图,绘制界面,最终迭代开发上线。
我们通过“用户故事”来描述用户想要得到什么,会做什么,并把它设计成一个产品功能(对于VUI而言,称之为语音技能skill)。
不同的是,设计语音skill,是把户可能和语音助手发生的对话 (dialog) 通过脚本(script)和流程(flow)去定义交互的细节和多样化的表达方式。(variantions)
1.确定目标
首先需要搞清楚的是,用户为什么要用这个skill,也就是需要设计一个或者多个情境,让用户有使用这个技能的意愿。
为什么用户需要用它?用户会做什么?不做什么?
2.创建故事
user story,和GUI下的设计是一致的,必须完整的定义基本的功能点,以及每个交互节点,明确用户在使用这个技能的边界是什么,可以做什么,不能做什么。
这是设计一个skill的基本原则。
用户可以得到什么信息?用户可以通过什么方式得到这个信息?为了得到这个信息,是否需要更多的服务作为支撑,比如订外卖的skill?
3.建立流程
flow,也就是用户完成某项任务的过程路径。
在确定边界范围之后,需要为用户设计完成任务所能使用到的不同的路径,也就是需要尽可能的把各种正常的、异常的状况,正向和反向的各种应对措施完整的设计表达出来。
在设计语音skill的流程时,有几条基本的原则(实际在也通用于GUI的流程设计):
(1)最短路径
一次性给出所有的必须信息,在语音交互过程中一句话(一轮对话)即可实现,如:明天北京的天气怎样吗?
(2)替换路径
通常,用户说的话不会包括所有的必要信息。
比如:明天下雨吗?这里缺少了一个关键槽位(slot),地域。
也就是用户在表达这句话的是会有两种情况,默认已知地理位置(当前位置),或者需要听者追问。
在我们的日常生活中,我们常常将把这句话理解为“明天(北京,自动默认当前位置信息)下雨吗?”
所以,必须设计完整的替换路径和决策树补充用户对话中的缺失信息。
(3)决策机制
比如首次使用语音助手的时候“播放音乐”,和多次播放音乐之后的决策是会有很大的差异,后台系统的决策逻辑需要根据用户的使用情况,给出最优机制,试图为用户创建更好的使用体验。
(4)帮助系统
语音交互的特殊性决定它在出现未知和异常现象时,极容易让用户感到困惑。
所以,在设计一个语音skill的时候,必须清晰的给予引导,帮助用户针获得skill的使用方式或者全面的指引,以及当数据缺失的反馈流程。
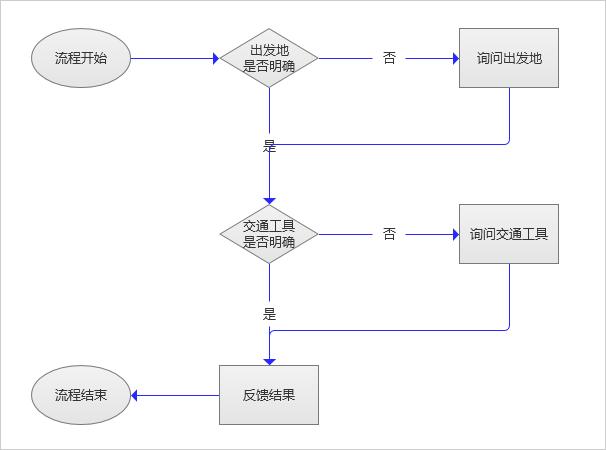
假设用户小明问“去北京要多久?”,你大概会需要画这样一个流程图。
4.撰写脚本
脚本(scripts),用户和语音助手之间的对话,这有点像一个电影或者戏剧的台本,这是一种非常有效的定义对话流程的方式。
撰写脚本的时候,需要尽可能的遵循前面提到的对话原则,简明扼要,同时又要能够挖掘到关键信息。
有两点需要特别注意:
- 不要假设用户知道做什么或者会发生什么
- 只提供用户所需要的信息
举个例子:
小明:明天出差要带伞吗?
助手:你要去哪里?
小明:北京
助手:别带了,这几天天气特别好。
#专栏作家#
杜松,公众号:产品微言,人人都是产品经理专栏作家。专注于人工智能方向,擅长产品规划和架构设计。
本文原创发布于人人都是产品经理。未经许可,禁止转载。
题图来自网络
,