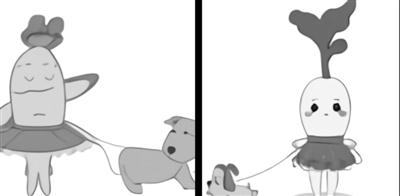
图为人工智能系统 DALL·E根据文本“穿着芭蕾舞裙遛狗的小萝卜”绘制的图像。图片来源:OpenAI官网
自然语言处理与视觉处理,都重在对不同模态数据所包含的语义信息进行识别和理解,但是两种数据的语义表现形式和处理方法不同,导致存在所谓的“语义壁垒”,现在这种壁垒正在被AI打破。
1月初,美国人工智能公司OpenAI推出两个跨越文本与图像次元的模型:DALL·E和CLIP,前者可以基于文本生成图像,后者则可以基于文本对图片进行分类。这个突破说明通过文字语言来操纵视觉概念现在已经触手可及。自然语言处理和视觉处理的边界已经被打破,多模态AI系统正在逐步建立。
“数据的来源或者形式是多种多样的,每一种都可以称为一种模态。例如图像、视频、声音、文字、红外、深度等都是不同模态的数据。单模态AI系统只能处理单个模态的数据。例如对于人脸识别系统或者语音识别系统来说,它们各自只能处理图像和声音数据。”中国科学院自动化研究所副研究员黄岩在接受科技日报记者采访时表示。
相对而言,多模态AI系统可以同时处理不止一种模态的数据,而且能够结合多种模态数据进行综合分析。“例如服务机器人系统或者无人驾驶系统就是典型的多模态系统,它们在导航的过程中会实时采集视频、深度、红外等多种模态的数据,进行综合分析后选择合适的行驶路线。”黄岩说。
不同层次任务强行关联会产生“壁垒”
就像人类有视觉、嗅觉、听觉一样,AI也有自己的“眼鼻嘴”,而为了研究的针对性和深入,科学家们通常会将其分为计算机视觉、自然语言处理、语音识别等研究领域,分门别类地解决不同的实际问题。
自然语言处理与视觉处理分别是怎样的过程,二者之间为什么会有壁垒?
语义是指文字、图像或符号之间的构成关系及意义。“自然语言处理与视觉处理,都重在对不同模态数据所包含的语义信息进行识别和理解,但是两种数据的语义表现形式和处理方法不同,导致存在所谓的‘语义壁垒’。”黄岩说。
视觉处理中最常见的数据就是图像,每个图像是由不同像素点排列而成的二维结构。像素点本身不具有任何语义类别信息,即无法仅凭一个像素点将其定义为图像数据,因为像素点本身只包含0到255之间的一个像素值。
“例如对于一张人脸图像来说,如果我们只看其中某些像素点是无法识别人脸图像这一语义类别信息的。因此,目前计算机视觉领域的研究人员更多研究的是如何让人工智能整合像素点数据,判断这个数据集合的语义类别。”黄岩说。
“语言数据最常见的就是句子,是由不同的词语序列化构成的一维结构。不同于图像像素,文本中每个词语已经包含了非常明确的语义类别信息。而自然语言处理则是在词语的基础上,进行更加高级的语义理解。”黄岩说,例如相同词语排列的顺序不同将产生不同的语义、多个句子联合形成段落则可以推理出隐含语义信息。
可以说,自然语言处理主要研究实现人与计算机直接用自然语言进行有效信息交流,这个过程包括自然语言理解和自然语言生成。自然语言理解是指计算机能够理解人类语言的意义,读懂人类语言的潜在含义;自然语言生成则是指计算机能以自然语言文本来表达它想要达到的意图。
由此可以看出,自然语言处理要解决的问题的层次深度超过了计算机视觉,自然语言处理是以理解人类的世界为目标,而计算机视觉所完成的就是所见即所得。这是两个不同层次的任务。目前来说,自然语言处理在语义分析层面来说要高于视觉处理,二者是不对等的。如果强行将两者进行语义关联的话,则会产生“语义壁垒”。
AI打破自然语言处理和视觉处理的边界
此前,OpenAI斥巨资打造的自然语言处理模型GPT-3,拥有1750亿超大参数量,是自然语言处理领域最强AI模型。人们发现GPT-3不仅能够答题、写文章、做翻译,还能生成代码、做数学推理、数据分析、画图表、制作简历。自2020年5月首次推出以来,GPT-3凭借惊人的文本生成能力受到广泛关注。
与GPT-3一样,DALL·E也是一个具有120亿参数的基于Transformer架构的语言模型,不同的是,GPT-3生成的是文本,DALL·E生成的是图像。
在互联网上,OpenAI大秀了一把DALL·E的“超强想象力”,随意输入一句话,DALL·E就能生成相应图片,这个图片内容可能是现实世界已经存在的,也可能是根据自己的理解创造出来的。
此前,关于视觉领域的深度学习方法一直存在三大挑战——训练所需大量数据集的采集和标注,会导致成本攀升;训练好的视觉模型一般只擅长一类任务,迁移到其他任务需要花费巨大成本;即使在基准测试中表现良好,在实际应用中可能也不如人意。
对此,OpenAI联合创始人曾发文声称,语言模型或是一种解决方案,可以尝试通过文本来修改和生成图像。基于这一愿景,CLIP应运而生。只需要提供图像类别的文本描述,CLIP就能将图像进行分类。
至此,AI已经打破了自然语言处理和视觉处理的边界。“这主要得益于计算机视觉领域中语义类别分析方面的飞速发展,使得AI已经能够进一步进行更高层次的视觉语义理解。”黄岩说。
具体来说,随着深度学习的兴起,计算机视觉领域从2012年至今已经接连攻克一般自然场景下的目标识别、检测、分割等语义类别分析任务。2015年至今,越来越多的视觉研究者们开始提出和研究更加高层的语义理解任务,包括基于图像生成语言描述、用语言搜索图片、面向图像的语言问答等。
“这些语义理解任务通常都需要联合视觉模型和语言模型才能够解决,因此出现了第一批横跨视觉领域和语言领域的研究者。”黄岩说,在他们推动下,两个领域开始相互借鉴优秀模型和解决问题的思路,并进一步影响到更多传统视觉和语言处理任务。
多模态交互方式会带来全新的应用
随着人工智能技术发展,科学家也正在不断突破不同研究领域之间的界限,自然语言处理和视觉处理的交叉融合并不是个例。
“语音识别事实上已经加入其中,最近业内出现很多研究视觉 语音的新任务,例如基于一段语音生成人脸图像或者跳舞视频。”黄岩说,但是要注意到,语音其实与语言本身在内容上可能具有较大的重合性。在现在语音识别技术非常成熟的前提下,完全可以先对语音进行识别将其转换为语言,进而把任务转换为语言与图像交互的常规问题。
无论是DALL·E还是CLIP,都采用不同的方法在多模态学习领域跨出了令人惊喜的一步。今后,文本和图像的界限是否会被进一步打破,能否顺畅地用文字“控制”图像的分类和生成,将会给现实生活带来怎样的改变,都值得期待。
对于多模态交互方式可能会带来哪些全新应用?黄岩举了两个具有代表性的例子。
第一个是手机的多模态语音助手。该技术可以丰富目前手机语音智能助手的功能和应用范围。目前的手机助手只能进行语音单模态交互,未来可以结合手机相册等视觉数据、以及网络空间中的语言数据来进行更加多样化的推荐、查询、问答等操作。
第二个是机器人的多模态导航。该技术可以提升服务机器人与人在视觉和语音(或语言)方面的交互能力,例如未来可以告诉机器人“去会议室看看有没有电脑”,机器人在理解语言指令的情况下,就能够结合视觉、深度等信息进行导航和查找。(记者 马爱平)
来源: 科技日报
,




