在这篇文章中,我们要讲到的是如何解决回归问题,以及如何通过使用特征转换、特征工程、聚类、提升算法等概念来提高机器学习模型的准确性。小白必入数据分析群,等你加入哦~

数据科学是一个迭代过程,只有经过反复实验,我们才能得到满足我们需求的最佳模型/解决方案。

数据科学过程流 — 作者图片
让我们通过一个例子来关注上面的每个阶段。我有一个健康保险数据集(CSV 文件),其中包含有关保险费用、年龄、性别、BMI 等的客户信息。根据数据集中的这些参数来预测保险费用。这是一个回归问题,我们的目标变量—费用/保险成本—是数字的。
让我们从加载数据集并探索属性开始(EDA — 探索性数据分析)


健康保险数据框
数据集有 1338 条记录和 6 个特征。吸烟者、性别和地区是分类变量,而年龄、BMI 和儿童是数字变量。
处理空值/缺失值
让我们检查数据集中缺失值的比例:

年龄和 BMI 有一些少量空值。首先将处理这些缺失的数据,然后开始数据分析。Sklearn 的SimpleImputer允许您根据相应列中的均值/中值/最频繁值替换缺失值。在这个例子中,我使用中值来填充空值。

现在我们的数据是干净的,我们将通过可视化和地图来分析数据。一个简单的seaborn pairplot可以给我们很多见解!

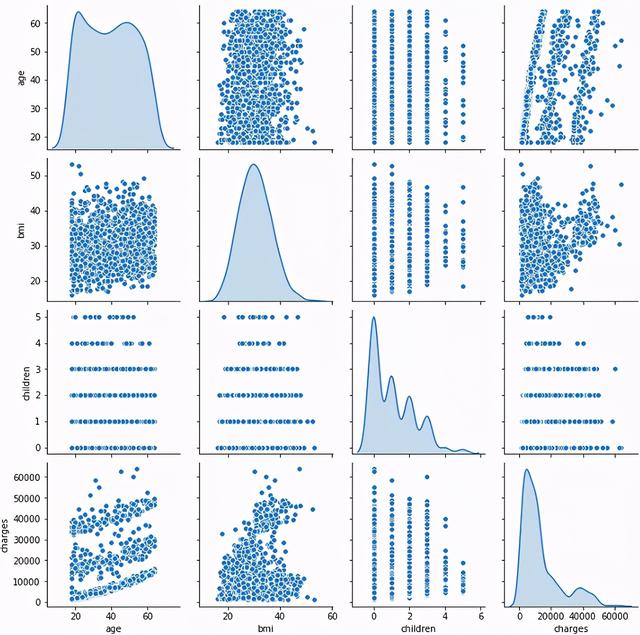
Seaborn Pairplot
看到了什么..?
- 收费和儿童是倾斜的。
- 年龄与收费呈正相关。
- BMI 正态分布!
Seaborn 的箱线图和计数图可用于显示分类变量对费用的影响。
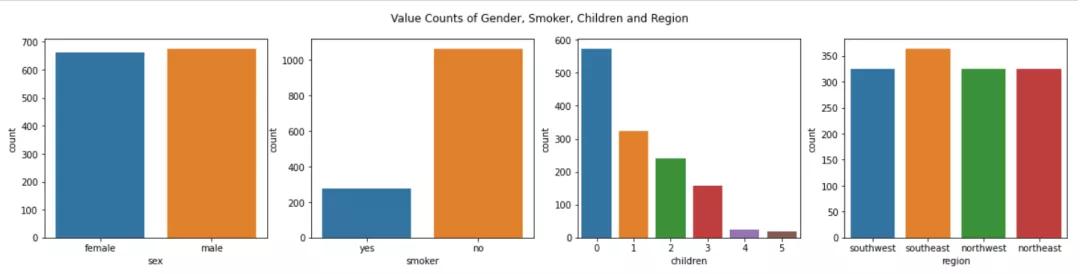
分类变量的 seaborn 计数图
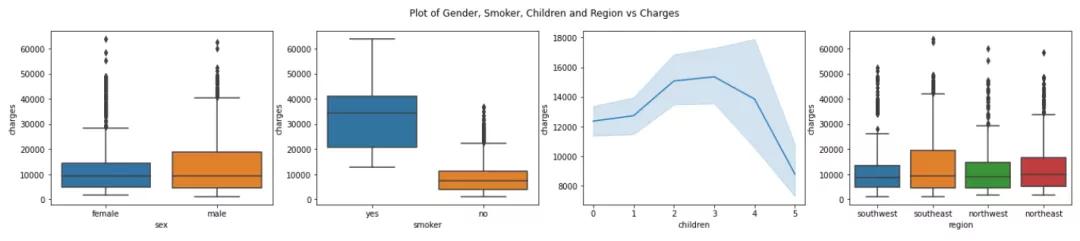
基于上述图的观察结果:
- 男性和女性的人数几乎相等,男性和女性的平均收费中位数也相同,但男性的收费范围更大。
- 吸烟者的保险费用相对较高。
- 有2-3个孩子的人收费最高
- 客户几乎平均分布在 4 个地区,而且所有地区 的费用几乎相同。
- 女性吸烟者的百分比低于男性吸烟者的百分比。
我们可以得出,“吸烟者”对保险费用的影响相当大,而性别的影响最小。
创建一个热图来了解费用和数字特征(年龄、BMI 和儿童)之间相关性的强度。


相关图
我们看到年龄和 BMI 与费用具有平均 ve 相关性。
我们现在将一一介绍模型准备和模型开发的步骤。
- 功能编码
在这一步中,我们将分类变量(吸烟者、性别和地区)转换为数字格式(0、1、2、3 等),因为大多数算法无法处理非数字数据。这个过程称为编码,有很多方法可以做到这一点:
- LabelEncoding — 将分类值表示为数字(例如,具有值意大利、印度、美国、英国的区域等特征可以表示为 1、2、3、4)
- OrdinalEncoding — 用于将基于等级的分类数据值表示为数字。(例如将高、中、低分别表示为 1、2、3)
- One-hot Encoding — 将分类数据表示为二进制值 — 仅 0,1。如果分类特征中没有很多唯一值,我更喜欢使用一次性编码而不是标签编码。在这里,我在 Region 上使用了 pandas 的一个热编码函数 ( get_dummies ) 并将其分成 4 别 — location_NE、location_SE、location_NW 和 location_SW。也可以对这一列使用标签编码,但是,一种热门编码给了我更好的结果。

2. 特征选择和缩放
接下来,我们将选择对“费用”影响最大的特征。我选择了除性别之外的所有功能,因为它对费用的影响非常小(从上面的可视化图表中得出结论)。这些特征将形成我们的“X”变量,而费用将成为我们的“y”变量。如果特征比较多,建议使用scikit-learn的SelectKBest进行特征选择,得到top特征。

一旦我们选择了特征,我们需要“标准化”数字——年龄、BMI、儿童。标准化过程将数据转换为 0 到 1 范围内的较小值,以便所有这些值都位于相同的范围内,并且不会压倒另一个。我在这里使用了StandardScaler。

现在,我们都准备好创建第一个基本模型。我们将尝试线性回归和决策树来预测保险费用

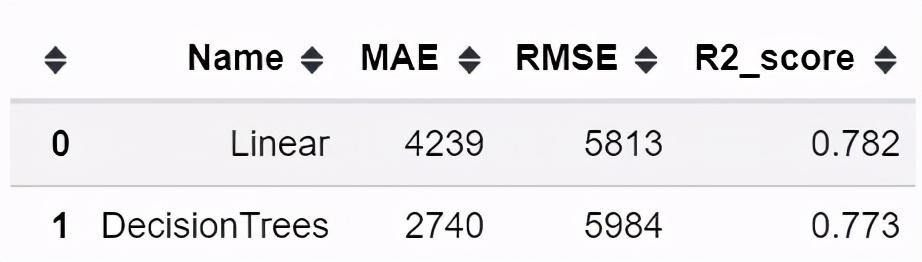
模型分数
平均绝对误差 ( MAE ) 和均方根误差 ( RMSE ) 是用于评估回归模型的指标。我们的基线模型给出了超过 76% 的分数。在 两种方法 之间,DecisionTrees 给出了更好的 MAE 为 2780。
让我们看看如何让我们的模型更好。
3A。特征工程
我们可以通过操纵数据集中的一些特征来提高我们的模型分数。经过几次试验,我发现以下项目可以提高准确性:
- 使用 KMeans 将类似客户分组到集群中。
- 在区域列中将东北和西北地区划分为“北部”,将东南和西南地区划分为“南部”。
- 将 'children' 转换为名为 'more_than_one_child' 的分类特征,如果孩子的数量 > 1 则为 'Yes'


所有功能
3B。特征变换
从我们的 EDA 中,我们知道Y的分布是高度偏斜的,因此我们将应用 scikit-learn 的目标转换器——QuantileTransformer来规范化这种行为。

高达 84%……而 MAE 已减少到 2189!
4. Ensemble 和 Boosting 算法的使用
现在我们将在基于集成的 RandomForest、GradientBoosting、LightGBM 和 XGBoost 上使用这些功能。如果您是初学者并且不了解 boosting 和 bagging 方法。

我们的 RandomForest 模型确实表现良好 — MAE为 2078。现在,我们将尝试使用一些增强算法,例如 Gradient Boosting、LightGBM 和 XGBoost。

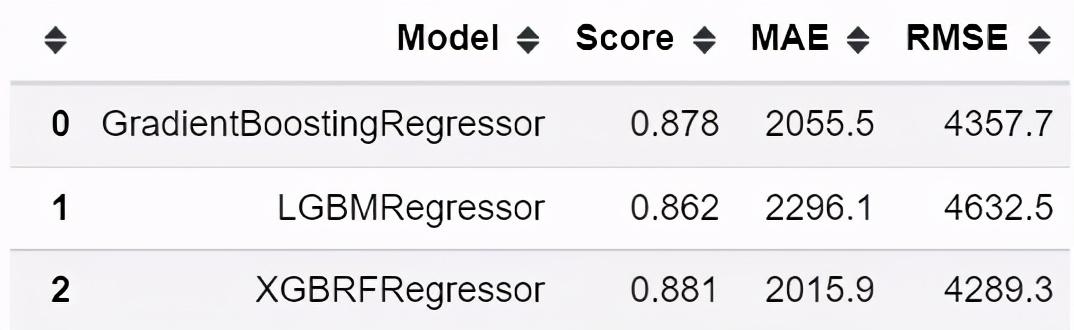
模型得分
似乎都表现得很好.
5. 超参数调优
让我们调整一些算法参数,例如树深度、估计量、学习率等,并检查模型的准确性。手动尝试不同的参数值组合非常耗时。Scikit-learn 的GridSearchCV自动执行此过程并计算这些参数的优化值。我已经将 GridSearch 应用于上述 3 种算法。下面是 XGBoost 的一个:


GridSearchCV 中参数的最佳值
一旦我们获得了参数的最佳值,我们将使用这些值再次运行所有 3 个模型。

模型得分
我们已经能够提高我们的准确性——XGBoost 给出了 88.6% 的分数,错误相对较少.
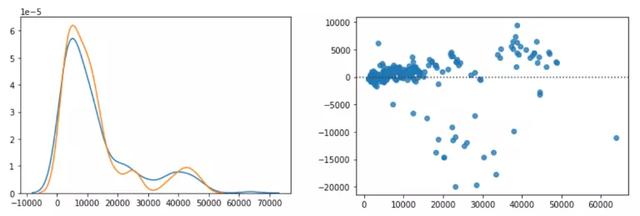
1. 费用预测值与实际值的分布图;2. 残差图 — 作者图片
分布图和残差图确认预测和实际存在良好的重叠。然而,有一些预测值远远超出了 x 轴,这使得我们的RMSE更高。这可以通过增加我们的数据点来减少,即收集更多数据。
我们现在准备将此模型部署到生产中并在未知数据上进行测试.
简而言之,提高我的模型准确性的点。
☛创建简单的新功能
☛转换目标变量
☛聚类公共数据点
☛提升算法的使用
☛Hyperparameter调优

,