目前这个系列的文章都挑着非常经典的,让人眼前一亮的算法,今天的堆排序算法就是其中一个。 首先理解什么是堆,这里面堆(Heap)并不是程序中内存区域,而是一种完全二叉树表示的数据结构。 堆具有以下特点
- 是一个完全二叉树
- 堆的每个节点的值必须大于等于左右树节点(大顶堆),或小于等于左右树节点(小顶堆)。
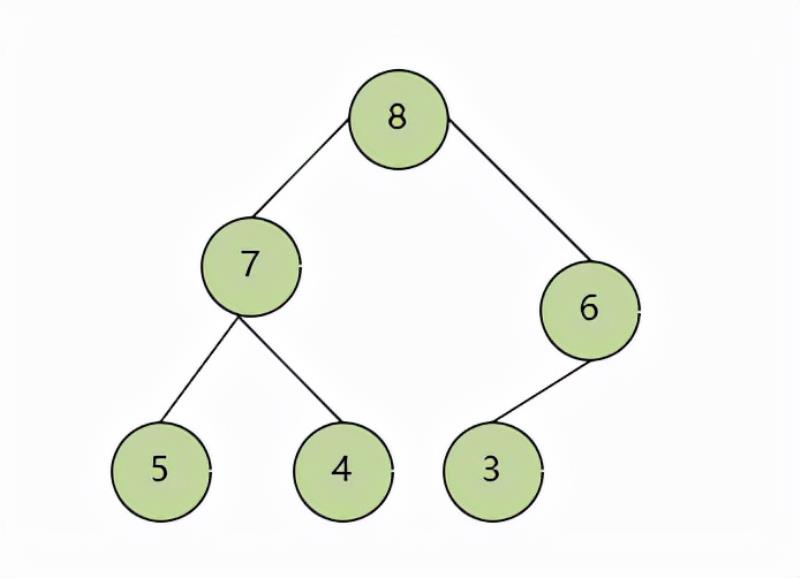
简单说明下,完全二叉树是除了最后一层叶子节点外,其他的节点都有两个子树,而叶子节点可以没有子树,或者只有左子树。 如下图就是个大顶堆:

小顶堆

堆存储
堆因为是完全二叉树,非常适合用数组存储,上图为大顶堆的存储情况,其中a[0]不用, a[1]为大顶堆的顶点,也就是最大的数据,a[12]= 7 为左子树顶点,a[12+1]= 6为右子树的顶点,其他节点情况依次类推。
堆的两种操作
向堆插入元素
用图来表示如下:

向堆插入元素,先插入到最后一个数组元素位置,然后和自己的父节点6比较,由于比6大不满足大顶堆的条件,所以9和6交换,然后9再和堆顶元素8比较,又不满足大顶堆条件,继续交换,最后形成一个大顶堆,这个步骤叫堆化。
删除堆顶元素
对于大顶堆来说,堆顶的元素为最大值,依次删除堆顶元素并输出,那么就是将数字从大向小排列了。
这里面又个技巧,就是删除堆顶元素的时候,不能直接删除,要用堆顶元素和最后一个元素做交换,然后根据堆的特点调整堆,直到满足条件。

完整代码如下:
package com.dianneng.lms;public class TestHeap { private int [] a; private int n; private int count; public TestHeap(int cap) { a = new int[cap+1]; n = cap; count = 0; } public void swap(int i,int j) { int tmp = a[i]; a[i] = a[j]; a[j] = tmp; return; } public void print(){ for (int i = 0; i <= count;i++) { System.out.print(a[i]+"t"); } } public int insert( int v) { if (count == n) { System.out.println("Heap is full!"); return -1; }else { a[++count] = v; int i = count; while (i/2 >0 && a[i] > a[i/2]) { swap(i,i/2); i = i/2; } } return 0; } public int removeMax() { if (count == 0) { return -1; } System.out.print(a[1]+"t"); a[1] = a[count]; --count; heapify(count,1); return 0; } private void heapify(int n, int i) { while(true) { int maxPos = i; //通过左右子树顶点比较获得最大数节点 if (i*2 <= n && a[i] <a[i*2] ){ maxPos = i*2; } if (i*2+1 <= n && a[maxPos] < a[i*2+1]) { maxPos = i*2+1; } //已经是最大的不用交换了 if (maxPos == i) { break; } //需要交换 swap(i,maxPos); //i指向待交换的 i = maxPos; } } public static void main(String [] args) { TestHeap th = new TestHeap(18); th.insert(8); th.insert(7); th.insert(6); th.insert(5); th.insert(4); th.insert(3); th.print(); System.out.println(); while(th.removeMax() == 0) { } }}可以利用大顶堆的特性,对要排序的数组进行先堆化排序,然后依次交换堆顶元素和最后一个元素,交换后堆化,将堆的大小减一,最终这样输出的就是从小到大排序的数组。 借用老师的一个图表示: