关系数据库是最流行和最常用的数字数据库,在本文中,我们将讨论关系数据库、它的工作原理、示例、关系数据库和非关系数据库之间的差异等等。
什么是关系数据库?一个关系数据库是基于组织彼此相关的数据点的模型数据的集合,该术语最初由IBM 研究实验室的英国计算机科学家Edgar Frank “Ted” Codd 于 1970 年引入。
关系数据库将有价值的信息或数据组织成表格,这些表格可以根据彼此共有的数据链接到其他几个表格,它使用户能够使用单个查询从一个或多个相关表中的数据构建新数据集。
关系数据库使用的数据结构包括表、索引和视图,关系数据库的主要组件是表、列和行。
关系数据库管理系统 (RDBMS) 用于维护关系数据库,此外,许多 RDBMS 支持用于查询和管理的结构化查询语言 (SQL)。
关系数据库如何工作?关系数据库的工作原理是通过“键”链接来自多个相关表的信息或数据,键是可以分配给表中包含的一行唯一数据的唯一标识符。此唯一标识符称为“主键”,可能包括 ID、序列号、用户名等。
当记录与主表中的主记录有关系时,主键可以包含在另一个表的记录中,如果将主键添加到另一个表中的记录,则称为“外键”。主键和外键之间的连接创建了多个表中数据集之间的关系。
关系数据库示例最流行的标准关系数据库包括:
- 甲骨文
- MySQL
- PostgreSQL
- 微软 SQL 服务器
- IBM Db2
最常用的基于云的关系数据库包括:
- 甲骨文云
- AWS 关系数据库服务
- 谷歌云 SQL
- IBM Db2 on Cloud
- SQL Azure
关系数据库是为符合预定义数据模型的结构化数据而开发的,相反,非关系型数据库用于非结构化数据,例如,可以使用关系数据库进行销售跟踪、计费或资产管理。
非关系数据库往往有更具体的用例。非关系数据库用例的一个示例是使用需要高度优化的搜索索引的大数据。
关系和非关系数据库之间的差异如下:
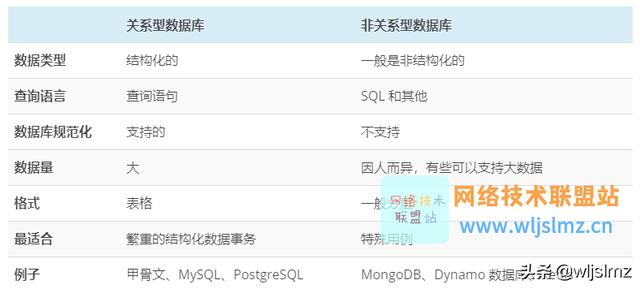
关系数据库模型将数据库表示为关系和关系集的集合,关系是相关数据值的表,其中每一行代表数据值的集合并表示关系或现实世界的实体,该表及其列用于解释每一行中的值。
在关系数据库模型中,信息或数据存储为表。
“
请注意,相关数据的物理存储与其逻辑组织方式无关。
”
实体之间的关系类型两个实体之间的关联称为关系。在关系数据库设计中,两个实体之间存在三种类型的关系:
- 一对一关系
- 一对多或多对一关系
- 多对多关系
在一对一关系中,表 X 中的每条记录都与表 Y 中的一个且仅一个记录相关,而表 Y 中的每个记录与表 X 中的一个且仅一个记录相关,例如,员工与其公司笔记本电脑之间的关系。
在一对多或多对一关系中,表X中的每条记录都与表Y中的多条记录相关,而表Y中的每条记录又与表X中的多条记录相关,例如,一个公司之间的关系及其员工笔记本电脑的库存。
在多对多关系中,表 X 中的许多记录与表 Y 中的许多记录相关,而表 Y 中的许多记录与表 X 中的许多记录相关,例如,公司笔记本电脑与其安装的应用程序之间的关系。
关系数据库让用户和企业更好地了解可用信息和数据之间的关系,多年来,关系数据库已经成功地管理了大量数据,并且变得更好、更快、更强且更易于使用——这就是为什么它们仍然是最受欢迎的数据库类型。
,




