学了一周多的爬虫课后终于按捺不住了,小编决定自己手动编写爬虫程序,刚好LJ在鼓励学员分享成果,优秀作品有奖励,就把自己用Python编程爬取各大游戏高清壁纸的过程整理了出来进行投稿,与大家一起分享。
爬取了当前比较火的游戏壁纸,MOBA游戏《英雄联盟》,手游《王者荣耀》、《阴阳师》,FPS游戏《绝地求生》,其中《英雄联盟》的壁纸最难爬取,这里展示爬取《英雄联盟》全部英雄壁纸的过程,学会了这个,自己再去爬取其他游戏壁纸也就不成问题啦。
先看一下最终爬取的效果,每个英雄的壁纸都被爬取下来了:

“黑暗之女 安妮”的12张壁纸:

高清大图:

下面开始正式教学!
- 版本:Python 3.5
- 工具:Jupyter notebook实现各个环节,最终整合成LOL_scrawl.py文件
在使用爬虫前,先花一定时间对爬取对象进行了解,是非常有必要的,这样可以帮助我们科学合理地设计爬取流程,以避开爬取难点,节约时间。
1.1英雄基本信息
打开英雄联盟官网,看到所有英雄的信息:

若要爬取全部英雄,我们先要获取这些英雄的信息,在网页上“右击——检查——Elements”,就能在看到英雄的信息了,如下图所示,包括英雄昵称、英雄名称、英文名等等。由于这些信息是使用JavaScript动态加载的,普通爬取方法无法获取,我们考虑使用虚拟浏览器PhantomJS来获取这些信息。

我们点击进入“暗黑之女 安妮”的页面,页面地址为“http://lol.qq.com/web201310/info-defail.shtml?id=Annie”,地址中的“Annie”是这个英雄的英文名,若要访问其他英雄界面,只需要更改英文名就可以了。
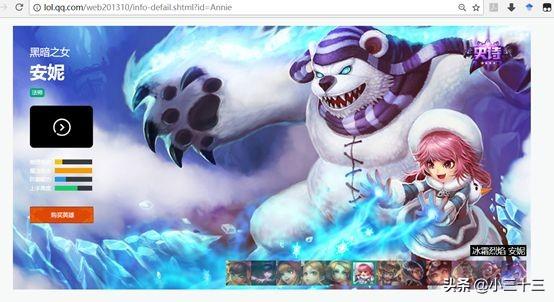
在英雄页面上,通过点击略缩图可以切换到不同的皮肤大图,在大图上“右击——在新标签页中打开图片”,就能打开大图,这就是我们要的高清壁纸:
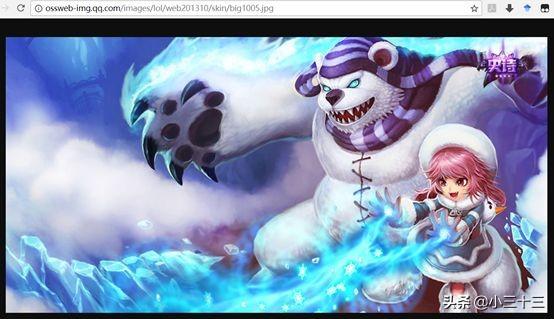
观察上图的地址信息,再打开其他几张安妮的皮肤壁纸来查看,发现不同壁纸仅在图片编号上有差别:
http://ossweb-img.qq.com/images/lol/web201310/skin/big1000.jpg
http://ossweb-img.qq.com/images/lol/web201310/skin/big1001.jpg
http://ossweb-img.qq.com/images/lol/web201310/skin/big1002.jpg
http://ossweb-img.qq.com/images/lol/web201310/skin/big1003.jpg
......
再观察英雄“盲僧 李青”的壁纸地址:
http://ossweb-img.qq.com/images/lol/web201310/skin/big64000.jpg
http://ossweb-img.qq.com/images/lol/web201310/skin/big64001.jpg
http://ossweb-img.qq.com/images/lol/web201310/skin/big64002.jpg
......
再观察英雄“卡牌大师 崔斯特”的壁纸地址:
http://ossweb-img.qq.com/images/lol/web201310/skin/big4000.jpg
http://ossweb-img.qq.com/images/lol/web201310/skin/big4001.jpg
http://ossweb-img.qq.com/images/lol/web201310/skin/big4002.jpg
......
可以总结出这样一条规则:壁纸地址由三部分组成,固定地址 英雄id 壁纸编号。
- 固定地址:“http://ossweb-img.qq.com/images/lol/web201310/skin/big”以及末尾的“.jpg”
- 英雄id:安妮的id是1,李青的id是64,崔斯特的是40,我们还需要找到所有英雄的id
- 壁纸编号:壁纸编号从000开始,001、002、003...,根据不同英雄的皮肤数量而不同,目前每个英雄壁纸都不超过20个,也就是最多编到020
1.2英雄ID
在上面的过程中,我们已经基本了解了要爬取对象的信息了,但每一个英雄的id是多少却还不知道,在网页源代码和用JavaScript加载后都找不到英雄和id的对应信息,猜测这个信息可能是放在某个js文件里,我们来找一找。
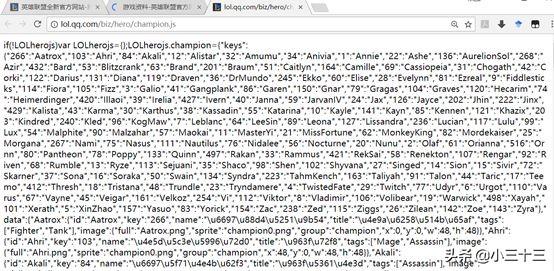
在所有英雄信息界面“右键——检查——Network”,再刷新一下界面,可以找到一个champion.js文件:

打开champion.js文件,发现里面就存着我们需要的信息,英雄英文名与英雄id一一对应:
1.3爬虫流程图
至此对我们要爬取的对象已经有了一定的了解,对于具体爬取方法也有了想法,我们可以设计如下爬虫流程图:

根据爬虫流程图,我们可以设计如下代码框架:
class LOL_scrawl: def __init__(self): #构造函数
pass def get_info(self): #输入爬取英雄名称、昵称或All
pass def create_lolfile(self): #在当前目录下创建文件夹LOL
pass def get_heroframe(self): #获取官网上所有英雄信息
pass def get_image(self,heroid,heroframe): #爬取英雄信息
pass def run(self): self.create_lolfile() #创建LOL文件夹
inputcontent = self.get_info() #获得键盘输入信息
heroframe = self.get_heroframe() #获得所有英雄信息
print('已获取英雄信息存于heroframe.csv,马上开始爬取壁纸...\n')
if inputcontent.lower() == 'all': #当输入all时,爬取全部英雄壁纸
pass else: #否则爬取单个英雄壁纸
passif __name__ == '__main__': lolscr = LOL_scrawl() #创建对象 lolscr.run() #运行爬虫
这个代码框架非常容易读懂,主要就是run()函数,run()函数完成了这样一套工作:创建LOL文件夹——获得键盘输入的信息——若信息为“All”则爬取全部英雄壁纸,否则爬取单个英雄壁纸。
在爬取所有或者单个英雄壁纸时,由于可能因为网络不稳定等因素导致爬取失败,因此我们要使用try-except来处理爬取壁纸时的代码:
if inputcontent.lower() == 'all': #当输入all时,爬取全部英雄壁纸
try: allline=len(heroframe) for i in range(1,allline):
heroid=heroframe['heroid'][[i]].values[:][0]
self.get_image(heroid,heroframe)
print('完成全部爬取任务!\n') except:
print('爬取失败或部分失败,请检查错误')else: #否则爬取单个英雄壁纸
try: hero=inputcontent.strip()
line = heroframe[(heroframe.heronickname==hero) | (heroframe.heroname==hero)].index.tolist()#找到所查英雄在dataframe中所在的行
heroid=heroframe['heroid'][line].values[:][0] #得到英雄id
self.get_image(heroid,heroframe)
print('完成全部爬取任务!\n') except: print('错误!请按照提示正确输入!\n')
至此已经打好了爬虫框架,下面对爬取过程中最核心的两个代码进行解释:get_heroframe()与get_image(heroid,heroframe)。
3.爬取所有英雄信息3.1解析js文件
首先我们要解析champion.js文件,得到英雄英文名与id的一一对应关系。使用urllib.request打开文件地址,读取内容并当作字符串处理,解析内容并转为字典{key:value},key为英文名,value为英雄id:
import urllib.request as urlrequest#获取英雄英文名及id,生成字典
herodict{Englishname:id}content=urlrequest.urlopen('http://lol.qq.com/biz/hero/champion.js').read()str1=r'champion={"keys":'str2=r',"data":{"Aatrox":'champion=str(content).split(str1)[1].split(str2)[0]herodict0=eval(champion) herodict = dict((k, v) for v, k in herodict0.items())#字典中的key和value互换print(herodict)
得到字典herodict{Englishname: id}如下:
{'Soraka': '16', 'Akali': '84', 'Skarner': '72', 'Tristana': '18', 'Zilean': '26', 'JarvanIV': '59', 'Varus': '110', 'Talon': '91', ...'Ashe': '22', 'Malphite':'54','Nocturne':'56','Khazix':'121'}
3.2 Selenium PhantomJS实现动态加载
对于官网网站上的所有英雄信息页面,由于是用JavaScript加载出来的,普通方法并不好爬取,我们使用Selenium PhantomJS的方法来动态加载英雄信息。Selenium 是自动化测试工具,它支持Chrome、Safari、Firefox 等浏览器驱动,在使用前先需要安装selenium模块。而PhantomJS是一个虚拟浏览器,它没有界面,但它的dom渲染、js运行、网络访问、canvas/svg绘制等功能都很完备,在页面抓取、页面输出、自动化测试等方面有广泛的应用。PhantomJS可以在官方网站上下载。
我们使用Selenium PhantomJS的方法来动态加载英雄信息,使用BeautifulSoup获取网址页面内容:
from selenium import webdriverimport timefrom bs4 import BeautifulSoup
#英雄联盟官网上所有英雄所在的网址
url_Allhero='http://lol.qq.com/web201310/info-heros.shtml#Navi'
#使用无头浏览器PhantomJS打开网址,解决JavaScript动态加载问题
driver=webdriver.PhantomJS(executable_path=r'D:\phantomjs-2.1.1-windows\bin\phantomjs')
#executable_path为PhantomJS的安装位置
driver.get(url_Allhero)time.sleep(1)
#暂停执行1秒,确保页面加载出来#使用BeautifulSoup获取网址页面内容
pageSource=driver.page_sourcedriver.close()bsObj=BeautifulSoup(pageSource,"lxml")
得到页面内容后,使用BeautifulSoup对页面内容进行解析,将英雄昵称、名称、id等信息存入heroframe中:
#使用BeautifulSoup解析页面内容,得到英雄信息表
heroframeherolist=bsObj.findAll('ul',{'class':'imgtextlist'})for hero in herolist: n=len(hero) m=0 heroframe=pd.DataFrame(index=range(0,n), columns=['herolink','heronickname','heroname','Englishname','heroid']) heroinflist=hero.findAll('a')
#抽取该英雄信息的超链接部分
for heroinf in heroinflist:
#对于英雄信息的超链接部分
herolink=heroinf['href']
eronickname=heroinf['title'].split(' ')[0].strip() heroname=heroinf['title'].split(' ')[1].strip() heroframe['herolink'][m]=herolink heroframe['heronickname'][m]=heronickname heroframe['heroname'][m]=heroname heroframe['Englishname'][m]=heroframe['herolink'][m][21:] heroframe['heroid'][m]=herodict[heroframe['Englishname'][m]] m=m 1heroframe.to_csv('./LOL/heroframe.csv',encoding='gbk',index=False)
至此,get_heroframe()函数实现了爬取所有英雄的信息,并存放在heroframe.csv文件中,如下所示:

得到每一个英雄的信息后,我们就可以开始愉快的爬取它们的壁纸啦~定义get_image(heroid,heroframe)函数,用于爬取单个英雄的全部壁纸。
首先在LOL文件夹中建立该英雄的子文件夹:
#创建存放该英雄壁纸的文件夹
line = heroframe[heroframe.heroid == heroid].index.tolist()
#找到所查英雄在dataframe中所在的行
nickname=heroframe['heronickname'][line].valuesname=heroframe['heroname'][line].valuesnickname_name=str((nickname ' ' name)[0][:])filehero='.\LOL' '\\' nickname_name if not os.path.exists(filehero): os.makedirs(filehero)
然后就可以爬取这个英雄的壁纸了。由于每个英雄壁纸都不超过20张,我们使用一个20以内的循环就能爬取到所有壁纸了:
#爬取多张壁纸for k in range(21):
#生成一张壁纸的地址
url='http://ossweb-img.qq.com/images/lol/web201310/skin/big' str(heroid) '0'*(3-len(str(k))) str(k) '.jpg'
#爬取一张壁纸
try: image=urlrequest.urlopen(url).read()
imagename=filehero '\\' '0'*(3-len(str(k))) str(k) '.jpg'
with open(imagename, 'wb') as f:
f.write(image) except HTTPError as e: continue
爬取完成后输出成功的提示:
#完成该英雄的爬取
print('英雄 ' nickname_name ' 壁纸已爬取成功\n')
到这里就大功告成啦!只要运行一下这个小程序,所有英雄的皮肤壁纸就都收入囊中了,当然也可以爬取单个英雄的所有皮肤,只要根据提示输入英雄的昵称或名称就好。
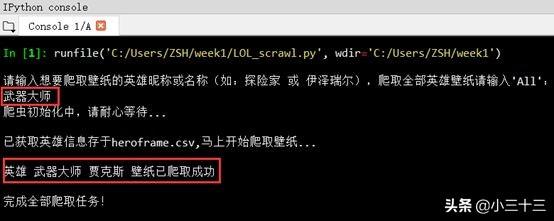
爬取单个英雄皮肤壁纸:
爬取所有英雄皮肤壁纸:

运行代码时注意保持网络畅通,如果网速太慢可能会爬取失败。在3兆有线网的网速下爬取全部139个英雄的全部高清壁纸(约一千张图)大概要3-4分钟。
《王者荣耀》、《阴阳师》、《绝地求生》等其他游戏的壁纸也是同样道理就可以爬取了,据我实践,《英雄联盟》的爬取难度是最高的,因此将上述过程弄懂了,自己再编写代码爬其他游戏就易如反掌了。
最后,放一张“至死不渝 瑞兹”壁纸,恭喜LPL夺冠!

如果你还是不会编写这个脚本,可以关注小编 转发此文,然后私信小编“皮肤”,就可以拿到完整代码,或者找我指导实现抓取全皮肤,原创不易!
点击了解更多,免费获取Python零基础入门爬虫进阶学习资料~~
,




