本篇内容讨论的是数据特征处理中数据标准化方案,相比于在【数据特征处理之数值型数据(归一化)】中介绍的归一化方案由于自身的不足而导致的应用场景受限(数据量较小的工程、不稳定),数据标准化方案几乎克服了特征极值的影响,且完全适用于数据工程较大的场景。
本文内容虽然很基础,但为了更加形象的理解知识内容,所以开始还是给出知识点的逻辑位置
什么是特征处理?
通过特定的统计方法(数学方法)将待处理数据转换为算法要求的数据的这个过程称为特征处理。

标准化的特点
对不同特征维度的伸缩变换使得不同度量之间的特征具有可比性
在数据量较多的场景比较稳定(适用于现代嘈杂大数据场景)
对于数据标准化,其数学(统计学)方法为
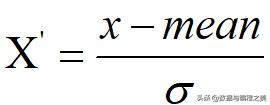
上述公式中,X’为标准化后的数据,mean为种特征的均值,σ为标准差。σ标准差理论计算公式为:
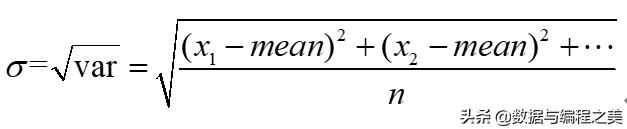
其中,n为每个特征的样本个数,mean依然为每种特征的均值,var在统计学中用来表示方差,其效果作用于每一列(划重点)

借助机器学习中的sklearn模块来完成数据的标准化特征处理

上述缩放结果是借助机器学习中的sklearn模块来完成的,完整的代码如下
# -*- coding:utf-8 -*-
# @Author: 数据与编程之美
# @File: standard_scaler.py
from sklearn.preprocessing import StandardScaler
def standard_scaler():
std = StandardScaler()
data = std.fit_transform([[425, 42, 0.16],
[544, 66, 1.28],
[509, 75, 0.87],
[496, 60, 0.99],
[580, 23, 1.15]])
print(data)
if __name__ == "__main__":
standard_scaler()
数据标准化后的特点:
数据标准化后的数据其每种特征的所有样本均值为0,方差、标准差为1。
数据标准化后没有改变数据的几何距离,即没有改变数据的分布(重点)。
上述内容便是数据特征处理中的数据标准化理论、操作流程。标准化由于自身的大数据量特性,因此很适合现今的诸多大数据量场景。
---END---
首发地址: 公众号:数据与编程之美
,