select object_name from t whereobject_id=29;
PGA不同于SGA,它是仅供当前发起用户使用的私有内存空间,用于用户连接信息的保存和权限的保存,只要该会话不断开连接,下次系统不用再去硬盘中读取数据,而直接从PGA内存区中获取。

SQL指令会立即匹配成一个唯一的hash值,该SQL指令进入2区进行处理,首先根据唯一的 hash 值查找SGA区的共享池是否存储过这个SQL指令,
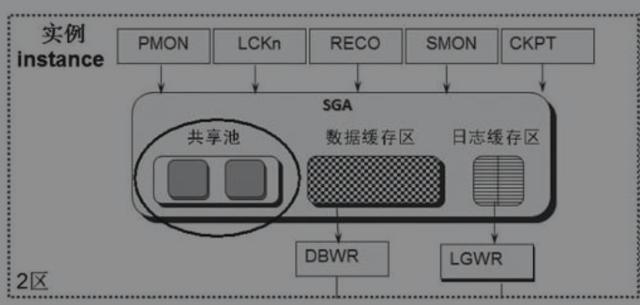
如果找不到,则:
首先检查SQL语句语法是否正确(比如from是否写成了form)、语义是否正确(比如id字段根本就不存在)、是否有权限,没问题则生成这条语句的唯一的hash值并存储下来了。
接下来进行解析,比如select object_name from t where object_id=29;在object_id列有索引的情况下,是用索引读更高效,还是全表扫描更高效呢?
Oracle要做出选择。Oracle把两种方式都估算一遍,看哪个代价(Cost)更低,就用哪种。这里不是真正地分别执行两次来比较。假设Oracle认定使用索引代价(Cost)更低,于是Oracle就选用了索引读的执行计划而放弃了全表扫描方式。接下来这个索引读的执行计划就立即被存储起来,并且和之前存储的该SQL指令的身份证(唯一hash值)对应在一起。
数据缓存区根据ID列上的索引从t表中查找object_id值为29的记录,如果记录不在缓冲区,数据缓存区则取Database数据文件区查找。如果查到了,就带回数据缓存区,并由展现给用户,如果找不到,也只有就此应答。


数据文件查数据
学习体系结构的意义Oracle 的共享池是为了第一次执行时保存解析过程,避免第二次执行时再做代价高昂的解析。而数据缓存区是为了第一次获取数据时将这些数据从磁盘读到数据缓存区,以便第二次可以避开磁盘查找,直接从数据缓存区找到数据,从而避免物理读。
排序在PGA内存区中操作,如果尺寸装得下就在内存中完成,否则超出部分会在临时表空间中完成,造成性能低下。
LGWR 从日志缓存区中把日志写出,并写进日志文件,写满第1个写第2个……全部写完要循环写的时候,在出现覆盖日志时要把即将被覆盖的日志先转移出去,形成归档文件保存起来,用于数据库的备份与恢复。
假如某数据库是一个很大的数据库,数据量庞大,访问量非常高,而共享池却非常小,共享池肯定很快就被放满了,缓存的东西要不断地被挤出,结果很多 SQL 语句都难以避免硬解析,于是整个数据库开始运行缓慢。“——加大共享池!
某主机总共才4GB 内存,而运行在其平台上的数据库是一个几乎没有什么访问量的小数据库,可能100MB的共享池就足够了,却被开辟了3GB的SGA内存,500MB的PGA内存。但是由于操作系统内存不足,导致主机运行缓慢,从而导致数据库运行缓慢——减少SGA的大小!
果由于数据缓存区过小导致大数据量的数据库产生大量的物理读——在SGA自动管理的情况下,加大SGA的大小,也等同于加大了数据缓存区的大小,这样数据缓存区够大,装的东西就多,物理读自然就减少了,性能自然就提高了。
如果一个尺寸很大的排序由于内存无法装下要在磁盘中进行,而操作系统却闲置着大量的内存未使用——增加PGA的大小,争取容纳下排序的尺寸,从而避免物理排序。
如果主机的内存不足,而某特定数据库几乎没有什么排序的应用——减小PGA,腾出占用的内存分配给操作系统使用。
假如一个数据库系统存在大量的更新操作,产生了大量的日志需要从RedoBuffer中写出到日志文件,结果日志写满然后切换到下一个日志的频率不断加快。切换过程中数据库需要等待切换完成才可以正常运作,因为切换没完成,LGWR就无法把Redo Buffer中的数据继续写出来,而数据库中Redo Buffer产生的记录总是先于数据缓存区产生的,这是串行的顺序,那此时数据库更新的动作就根本不可能成功,一定要等待日志切换成功。在日志频繁地切换,更新一直在停停走走——日志组的这些日志越大,就越经得住写,切换就越少,等待时间就越短,所以加大这些日志文件的尺寸
查询的一致性问题——当前镜像无法找回原来的记录,被覆盖重写时就会报错退出,错误号是ORA-01555,Oracle宁愿查询失败也不愿意查询出错误不一致的结果。
现在某应用系统因为查询老出ORA-01555错误返回不了结果给下一个模块使用,导致生产出现故障了——检查这个语句为什么执行这么慢,让这个语句执行得快一点,就不容易被更新直至覆盖重写啊;增大undo_retention的取值,比如写一个很大的时间,让回滚段在这段时间内都不允许被覆盖重写。
undo_retention只是参考保留时间并非强制,除非另外设置undo表空间的Retention Guarantee属性,使之强制保留。此外也可考虑增加undo表空间的大小。
案例构造环境

存储过程,实现了将1到10万的值插入t表的需求

执行脚本

共享池中缓存下来的SQL语句以及hash出来的唯一值,都可以在v$sql中对应的sql_text和sql_id字段中查询到,而解析的次数和执行的次数分别可以从PARSE_CALLS和EXECUTIONS字段中获取。

每条语句都只解析1次,执行1次,解析了10万次

insert into t values(99898)、insert into tvalues(99762)等这10万条语句能合并成一种写法,比如用变量代替具体值,成为insert into t values(:x),那这10万条语句可以被hash成一个sql_id值,可以做到解析1次,执行10万次?这样可以大大减少解析时间。

测试proc2过程(注意,重建表的目的是为了公平,测试都在无记录的空表上进行,并且共享池都清空)

语句被绑定变量了,解析次数变少了

虽然插入的语句值各不相同,但是都被绑定为:x,所以被hash成唯一一个hash值,名称为dxz576128adaw,很明显可以看出解析1次,执行10万次,这就是速度大幅度提升的原因了。
静态改写execute immediate是一种动态SQL的写法,常用于表名和字段名是变量、入参的情况,由于表名都不知道,当然不能直接写 SQL 语句了,所以要靠动态 SQL语句根据传入的表名参数来拼成一条SQL语句,由executeimmediate调用执行。但是这里显然不需要多此一举,因为insert into tvalues(i)完全可以满足需求,表名就是t啊。



proc3也实现了绑定变量,而且动态SQL的特点是执行过程中再解析,而静态SQL的特点是编译的过程就解析好了。这点差别就是速度再度提升的原因。
批量提交commit触发LGWR将Redo Buffer写出到Redo Log中,并且将回滚段的活动事务标记为不活动,同时在回滚段中记录对应前镜像记录的所在位置,并标记为可以重写,切记commit可不是写数据的动作,写数据将数据从DataBuffer刷出磁盘是由CKPT决定的。
所以commit开销并不大,单次提交可能需要0.001秒即可完成。另外不管多大批量操作后的提交,仅针对commit而言,也是做这三件事,所花费的总时间不可能超过1秒。打个比方,100万条更新批量执行后完成commit的提交可能也就需要0.8秒,但是100万×0.001的时间可是远大于1×0.8的时间。

测试proc4的性能



原先的一条一条插入的语句变成了一个集合的概念,变成了整批地写进Data Buffer区里,
直接路径

改用create table 的直接路径方式来新建t表

只需要10秒即可完成,等同于插入速度为每秒100万条
insert into t select ……的方式是将数据先写到Data Buffer中,然后再刷到磁盘中。
create table t 的方式却是跳过了数据缓存区,直接将数据写进磁盘,这种方式又称为直接路径读写方式,因为原本是数据先到内存,再到磁盘,更改为数据直接到磁盘,少了一个步骤,因而速度提升了许多。
直接路径读写方式的缺点在于由于数据不经过数据缓存区,所以在数据缓存区中一定读不到这些数据,因此一定会有物理读。但是在很多时候,尤其是海量数据需要迁移插入时,快速插入才是真正的第一目的,该表一般记录量巨大,DataBuffer甚至还装不下其十分之一、百分之一,这些数据共享的意义也不大,这时,一般会选择用直接路径读写的方式来完成海量数据的插入。
设置日志关闭nologging,并且设置parallel 16 表示用到机器的16个CPU,结果在笔记本环境下收效不是很明显,因为我的环境是单核的机器。后来把如下SQL语句运行在强劲的服务器上,有16个CPU,下面的语句仅仅在4秒不到的时间内就完成了,速度相对于前面的火箭速度而言,快多了,几乎是每秒300万条的插入速度

并行最大的缺点就是占用了大多数CPU的资源,如果是一个并发环境,很多应用在运行,因为这个影响了其他应用,导致其他应用资源不足,将引发很多严重问题,所以需要三思而后行,了解清楚该机器是否允许这样占用大部分资源。
,