作者:luozhiyun,腾讯IEG后台开发工程师博客:https://www.luozhiyun.com/archives/475本文使用的 Go 的源码1.15.7
创建后台标记 Worker
func gcBgMarkStartWorkers() {
// 遍历所有 P
for _, p := range allp {
// 如果已启动则不重复启动
if p.gcBgMarkWorker == 0 {
// 为全局每个处理器创建用于执行后台标记任务的 Goroutine
go gcBgMarkWorker(p)
// 启动后等待该任务通知信号量 bgMarkReady 再继续
notetsleepg(&work.bgMarkReady, -1)
noteclear(&work.bgMarkReady)
}
}
}
gcBgMarkStartWorkers 会为全局每个 P 创建用于执行后台标记任务的 Goroutine,每一个 Goroutine 都会运行 gcBgMarkWorker,notetsleepg 会等待 gcBgMarkWorker 通知信号量 bgMarkReady 再继续。
这里虽然为每个 P 启动了一个后台标记任务, 但是可以同时工作的只有 25%,调度器在调度循环 runtime.schedule中通过调用 gcController.findRunnableGCWorker方法进行控制。
在看这个方法之前,先来了解一个概念, Mark Worker Mode 标记工作模式,目前来说有三种,这三种是为了保证后台的标记线程的利用率。
type gcMarkWorkerMode int
const (
// gcMarkWorkerDedicatedMode indicates that the P of a mark
// worker is dedicated to running that mark worker. The mark
// worker should run without preemption.
gcMarkWorkerDedicatedMode gcMarkWorkerMode = iota
// gcMarkWorkerFractionalMode indicates that a P is currently
// running the "fractional" mark worker. The fractional worker
// is necessary when GOMAXPROCS*gcBackgroundUtilization is not
// an integer. The fractional worker should run until it is
// preempted and will be scheduled to pick up the fractional
// part of GOMAXPROCS*gcBackgroundUtilization.
gcMarkWorkerFractionalMode
// gcMarkWorkerIdleMode indicates that a P is running the mark
// worker because it has nothing else to do. The idle worker
// should run until it is preempted and account its time
// against gcController.idleMarkTime.
gcMarkWorkerIdleMode
)
通过代码注释可以知道:
- gcMarkWorkerDedicatedMode :P 专门负责标记对象,不会被调度器抢占;
- gcMarkWorkerFractionalMode:主要是由于现在默认标记线程的占用率要为 25%,所以如果 CPU 核数不是4的倍数,就无法除得整数,启动该类型的工作模式帮助垃圾收集达到利用率的目标;
- gcMarkWorkerIdleMode:表示 P 当前只有标记线程在跑,没有其他可以执行的 G ,它会运行垃圾收集的标记任务直到被抢占;
func (c *gcControllerState) findRunnableGCWorker(_p_ *p) *g {
...
// 原子减少对应的值, 如果减少后大于等于0则返回true, 否则返回false
decIfPositive := func(ptr *int64) bool {
if *ptr > 0 {
if atomic.Xaddint64(ptr, -1) >= 0 {
return true
}
// We lost a race
atomic.Xaddint64(ptr, 1)
}
return false
}
// 减少dedicatedMarkWorkersNeeded, 成功时后台标记任务的模式是Dedicated
if decIfPositive(&c.dedicatedMarkWorkersNeeded) {
_p_.gcMarkWorkerMode = gcMarkWorkerDedicatedMode
} else if c.fractionalUtilizationGoal == 0 {
// No need for fractional workers.
return nil
} else {
// 执行标记任务的时间
delta := nanotime() - gcController.markStartTime
if delta > 0 && float64(_p_.gcFractionalMarkTime)/float64(delta) > c.fractionalUtilizationGoal {
// Nope. No need to run a fractional worker.
return nil
}
_p_.gcMarkWorkerMode = gcMarkWorkerFractionalMode
}
gp := _p_.gcBgMarkWorker.ptr()
casgstatus(gp, _Gwaiting, _Grunnable)
return gp
}
在 findRunnableGCWorker 会通过 dedicatedMarkWorkersNeeded 来决定是否采用 gcMarkWorkerDedicatedMode 的 Mark Worker Mode 标记工作模式。dedicatedMarkWorkersNeeded 是在 gcControllerState.startCycle中进行初始化。
公式我就不贴了,在 gcControllerState.startCycle已经讲过了,通俗来说如果当前是 8 核 CPU,那么 dedicatedMarkWorkersNeeded 为 2 ,如果是 6 核 CPU,因为无法被 4 整除,计算得 dedicatedMarkWorkersNeeded 为 1,所以需要上面得 gcMarkWorkerFractionalMode 模式来保证 CPU 的利用率。
gcMarkWorkerIdleMode 会在调度器执行 findrunnable 抢占的时候调用:
func findrunnable() (gp *g, inheritTime bool) {
...
stop:
// 处于 GC 阶段的话,获取执行GC标记任务的G
if gcBlackenEnabled != 0 && _p_.gcBgMarkWorker != 0 && gcMarkWorkAvailable(_p_) {
_p_.gcMarkWorkerMode = gcMarkWorkerIdleMode
gp := _p_.gcBgMarkWorker.ptr()
//将本地 P 的 GC 标记专用 G 职位 Grunnable
casgstatus(gp, _Gwaiting, _Grunnable)
return gp, false
}
...
}
看过我的《详解Go语言调度循环源码实现》的同学应该都知道,抢占调度运行到这里的时候,通常是 P 抢占不到 G 了,打算进行休眠了,因此在休眠之前可以安全的进行标记任务的执行。
没看过调度循环的同学可以看这里:详解Go语言调度循环源码实现 https://www.luozhiyun.com/archives/448 。
并发扫描标记并发扫描标记可以大概概括为以下几个部分:
- 将当前传入的 P 打包成 parkInfo ,然后调用 gopark 让当前 G 进入休眠,在休眠前会将 P 的 gcBgMarkWorker 与 G 进行绑定,等待唤醒;
- 根据 Mark Worker Mode 调用不同的策略调用 gcDrain 执行标记;
- 判断是否所有后台标记任务都完成, 并且没有更多的任务,调用 gcMarkDone 准备进入完成标记阶段;
func gcBgMarkWorker(_p_ *p) {
gp := getg()
type parkInfo struct {
m muintptr
attach puintptr
}
gp.m.preemptoff = "GC worker init"
// 初始化 park
park := new(parkInfo)
gp.m.preemptoff = ""
// 设置当前的M并禁止抢占
park.m.set(acquirem())
// 设置当前的P
park.attach.set(_p_)
// 通知gcBgMarkStartWorkers可以继续处理
notewakeup(&work.bgMarkReady)
for {
// 让当前 G 进入休眠
gopark(func(g *g, parkp unsafe.Pointer) bool {
park := (*parkInfo)(parkp)
releasem(park.m.ptr())
// 设置关联的 P
if park.attach != 0 {
p := park.attach.ptr()
park.attach.set(nil)
// 把当前的G设到P的gcBgMarkWorker成员
if !p.gcBgMarkWorker.cas(0, guintptr(unsafe.Pointer(g))) {
return false
}
}
return true
}, unsafe.Pointer(park), waitReasonGCWorkerIdle, traceEvGoBlock, 0)
...
}
}
在 gcBgMarkStartWorkers 中我们看到,它会遍历所有的 P ,然后为每个 P 创建一个负责 Mark Work 的 G,这里虽然为每个 P 启动了一个后台标记任务, 但是不可能每个 P 都会去执行标记任务,后台标记任务默认资源占用率是 25%,所以 gcBgMarkWorker 中会初始化 park 并将 G 和 P 的 gcBgMarkWorker 进行绑定后进行休眠。
调度器在调度循环 runtime.schedule中通过调用 gcController.findRunnableGCWorker方法进行控制,让哪些 Mark Work 可以执行,上面代码已经贴过了,这里就不重复了。

在唤醒后,我们会根据 gcMarkWorkerMode 选择不同的标记执行策略,不同的执行策略都会调用 runtime.gcDrain :
func gcBgMarkWorker(_p_ *p) {
gp := getg()
...
for {
...
// 检查P的gcBgMarkWorker是否和当前的G一致, 不一致时结束当前的任务
if _p_.gcBgMarkWorker.ptr() != gp {
break
}
// 禁止G被抢占
park.m.set(acquirem())
// 记录开始时间
startTime := nanotime()
_p_.gcMarkWorkerStartTime = startTime
decnwait := atomic.Xadd(&work.nwait, -1)
systemstack(func() {
// 设置G的状态为等待中这样它的栈可以被扫描
casgstatus(gp, _Grunning, _Gwaiting)
// 判断后台标记任务的模式
switch _p_.gcMarkWorkerMode {
default:
throw("gcBgMarkWorker: unexpected gcMarkWorkerMode")
case gcMarkWorkerDedicatedMode:
// 这个模式下P应该专心执行标记
gcDrain(&_p_.gcw, gcDrainUntilPreempt|gcDrainFlushBgCredit)
if gp.preempt {
// 被抢占时把本地运行队列中的所有G都踢到全局运行队列
lock(&sched.lock)
for {
gp, _ := runqget(_p_)
if gp == nil {
break
}
globrunqput(gp)
}
unlock(&sched.lock)
}
// 继续执行标记
gcDrain(&_p_.gcw, gcDrainFlushBgCredit)
case gcMarkWorkerFractionalMode:
// 执行标记
gcDrain(&_p_.gcw, gcDrainFractional|gcDrainUntilPreempt|gcDrainFlushBgCredit)
case gcMarkWorkerIdleMode:
// 执行标记, 直到被抢占或者达到一定的量
gcDrain(&_p_.gcw, gcDrainIdle|gcDrainUntilPreempt|gcDrainFlushBgCredit)
}
// 恢复G的状态到运行中
casgstatus(gp, _Gwaiting, _Grunning)
})
...
}
}
在上面已经讲了不同的 Mark Worker Mode 的区别,不记得的同学可以往上翻一下。执行标记这部分主要在 switch 判断中,根据不同的模式传入不同的参数到 gcDrain 函数中执行。
需要注意的是,传入到 gcDrain 中的是一个 gcWork 的结构体,它相当于每个 P 的私有缓存空间,存放需要被扫描的对象,为垃圾收集器提供了生产和消费任务的抽象,,该结构体持有了两个重要的工作缓冲区 wbuf1 和 wbuf2:

当我们向该结构体中增加或者删除对象时,它总会先操作 wbuf1 缓冲区,一旦 wbuf1 缓冲区空间不足或者没有对象,会触发缓冲区的切换,而当两个缓冲区空间都不足或者都为空时,会从全局的工作缓冲区中插入或者获取对象:
func (w *gcWork) tryGet() uintptr {
wbuf := w.wbuf1
...
// wbuf1缓冲区无数据时
if wbuf.nobj == 0 {
// wbuf1 与 wbuf2 进行对象互换
w.wbuf1, w.wbuf2 = w.wbuf2, w.wbuf1
wbuf = w.wbuf1
if wbuf.nobj == 0 {
owbuf := wbuf
// 从 work 的 full 队列中获取
wbuf = trygetfull()
...
}
}
wbuf.nobj--
return wbuf.obj[wbuf.nobj]
}
继续上面的 gcBgMarkWorker 方法,在标记完之后就要进行标记完成:
func gcBgMarkWorker(_p_ *p) {
gp := getg()
...
for {
...
// 累加所用时间
duration := nanotime() - startTime
switch _p_.gcMarkWorkerMode {
case gcMarkWorkerDedicatedMode:
atomic.Xaddint64(&gcController.dedicatedMarkTime, duration)
atomic.Xaddint64(&gcController.dedicatedMarkWorkersNeeded, 1)
case gcMarkWorkerFractionalMode:
atomic.Xaddint64(&gcController.fractionalMarkTime, duration)
atomic.Xaddint64(&_p_.gcFractionalMarkTime, duration)
case gcMarkWorkerIdleMode:
atomic.Xaddint64(&gcController.idleMarkTime, duration)
}
incnwait := atomic.Xadd(&work.nwait, 1)
// 判断是否所有后台标记任务都完成, 并且没有更多的任务
if incnwait == work.nproc && !gcMarkWorkAvailable(nil) {
// 取消和P的关联
_p_.gcBgMarkWorker.set(nil)
// 允许G被抢占
releasem(park.m.ptr())
// 准备进入完成标记阶段
gcMarkDone()
// 休眠之前会重新关联P
// 因为上面允许被抢占, 到这里的时候可能就会变成其他P
// 如果重新关联P失败则这个任务会结束
park.m.set(acquirem())
park.attach.set(_p_)
}
}
}
gcBgMarkWorker 会根据 incnwait 来检查是否是最后一个 worker,然后调用 gcMarkWorkAvailable 函数来校验 gcwork的任务和全局任务是否已经全部都处理完了,如果都确认没问题,那么调用 gcMarkDone 进入完成标记阶段。
标记扫描下面我们来看看 gcDrain:
func gcDrain(gcw *gcWork, flags gcDrainFlags) {
gp := getg().m.curg
// 看到抢占标志时是否要返回
preemptible := flags&gcDrainUntilPreempt != 0
// 是否计算后台的扫描量来减少协助线程和唤醒等待中的G
flushBgCredit := flags&gcDrainFlushBgCredit != 0
// 是否只执行一定量的工作
idle := flags&gcDrainIdle != 0
// 记录初始的已扫描数量
initScanWork := gcw.scanWork
checkWork := int64(1<<63 - 1)
var check func() bool
if flags&(gcDrainIdle|gcDrainFractional) != 0 {
// drainCheckThreshold 默认 100000
checkWork = initScanWork drainCheckThreshold
if idle {
check = pollWork
} else if flags&gcDrainFractional != 0 {
check = pollFractionalWorkerExit
}
}
// 如果根对象未扫描完, 则先扫描根对象
if work.markrootNext < work.markrootJobs {
// 一直循环直到被抢占或 STW
for !(gp.preempt && (preemptible || atomic.Load(&sched.gcwaiting) != 0)) {
// 从根对象扫描队列取出一个值
job := atomic.Xadd(&work.markrootNext, 1) - 1
if job >= work.markrootJobs {
break
}
// 执行根对象扫描工作
markroot(gcw, job)
if check != nil && check() {
goto done
}
}
}
...
}
gcDrain 函数在开始的时候,会根据 flags 不同而选择不同的策略。
- gcDrainUntilPreempt:当 G 被抢占时返回;
- gcDrainIdle:调用 runtime.pollWork,当 P 上包含其他待执行 G 时返回;
- gcDrainFractional:调用 runtime.pollFractionalWorkerExit,当 CPU 的占用率超过 fractionalUtilizationGoal 的 20% 时返回;
设置完 check 变量后就可以执行 runtime.markroot进行根对象扫描,每次扫描完毕都会调用 check 函数校验是否应该退出标记任务,如果是那么就跳到 done 代码块中退出标记。
完成标记后会获取待执行的任务:
func gcDrain(gcw *gcWork, flags gcDrainFlags) {
...
// 根对象已经在标记队列中, 消费标记队列
// 一直循环直到被抢占或 STW
for !(gp.preempt && (preemptible || atomic.Load(&sched.gcwaiting) != 0)) {
// 将本地一部分工作放回全局队列中
if work.full == 0 {
gcw.balance()
}
// 获取任务
b := gcw.tryGetFast()
if b == 0 {
b = gcw.tryGet()
if b == 0 {
wbBufFlush(nil, 0)
b = gcw.tryGet()
}
}
// 获取不到对象, 标记队列已为空, 跳出循环
if b == 0 {
break
}
// 扫描获取到的对象
scanobject(b, gcw)
// 如果已经扫描了一定数量的对象,gcCreditSlack值是2000
if gcw.scanWork >= gcCreditSlack {
// 把扫描的对象数量添加到全局
atomic.Xaddint64(&gcController.scanWork, gcw.scanWork)
if flushBgCredit {
// 记录这次扫描的内存字节数用于减少辅助标记的工作量
gcFlushBgCredit(gcw.scanWork - initScanWork)
initScanWork = 0
}
checkWork -= gcw.scanWork
gcw.scanWork = 0
if checkWork <= 0 {
checkWork = drainCheckThreshold
if check != nil && check() {
break
}
}
}
}
done:
// 把扫描的对象数量添加到全局
if gcw.scanWork > 0 {
atomic.Xaddint64(&gcController.scanWork, gcw.scanWork)
if flushBgCredit {
// 记录这次扫描的内存字节数用于减少辅助标记的工作量
gcFlushBgCredit(gcw.scanWork - initScanWork)
}
gcw.scanWork = 0
}
}
这里在获取缓存队列之前会调用 runtime.gcWork.balance,会将 gcWork 缓存一部分工作放回全局队列中,这个方法主要是用来平衡一下不同 P 的负载情况。
然后获取 gcWork 的缓存任务,并将获取到的任务交给 scanobject 执行,该函数会从传入的位置开始扫描,并会给找到的活跃对象上色。runtime.gcFlushBgCredit 会记录这次扫描的内存字节数用于减少辅助标记的工作量。
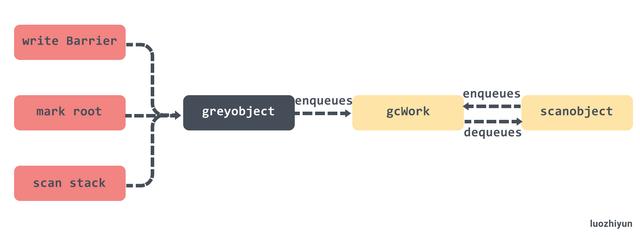
这里我来总结一下 gcWork 出入队情况。gcWork 的出队就是我们上面的 scanobject 方法,会获取到 gcWork 缓存对象并执行,但是同时如果找到活跃对象也会再次的入队到 gcWork 中。
除了 scanobject 以外,写屏障、根对象扫描和栈扫描都会向 gcWork 中增加额外的灰色对象等待处理。
根标记
func markroot(gcw *gcWork, i uint32) {
baseFlushCache := uint32(fixedRootCount)
baseData := baseFlushCache uint32(work.nFlushCacheRoots)
baseBSS := baseData uint32(work.nDataRoots)
baseSpans := baseBSS uint32(work.nBSSRoots)
baseStacks := baseSpans uint32(work.nSpanRoots)
end := baseStacks uint32(work.nStackRoots)
switch {
// 释放mcache中的所有span, 要求STW
case baseFlushCache <= i && i < baseData:
flushmcache(int(i - baseFlushCache))
// 扫描可读写的全局变量
case baseData <= i && i < baseBSS:
for _, datap := range activeModules() {
markrootBlock(datap.data, datap.edata-datap.data, datap.gcdatamask.bytedata, gcw, int(i-baseData))
}
// 扫描未初始化的全局变量
case baseBSS <= i && i < baseSpans:
for _, datap := range activeModules() {
markrootBlock(datap.bss, datap.ebss-datap.bss, datap.gcbssmask.bytedata, gcw, int(i-baseBSS))
}
// 扫描 finalizers 队列
case i == fixedRootFinalizers:
for fb := allfin; fb != nil; fb = fb.alllink {
cnt := uintptr(atomic.Load(&fb.cnt))
scanblock(uintptr(unsafe.Pointer(&fb.fin[0])), cnt*unsafe.Sizeof(fb.fin[0]), &finptrmask[0], gcw, nil)
}
// 释放已中止的 G 的栈
case i == fixedRootFreeGStacks:
systemstack(markrootFreeGStacks)
// 扫描 MSpan.specials
case baseSpans <= i && i < baseStacks:
markrootSpans(gcw, int(i-baseSpans))
// 扫描各个 G 的栈
default:
// 获取需要扫描的 G
var gp *g
if baseStacks <= i && i < end {
gp = allgs[i-baseStacks]
} else {
throw("markroot: bad index")
}
// 记录等待开始的时间
status := readgstatus(gp) // We are not in a scan state
if (status == _Gwaiting || status == _Gsyscall) && gp.waitsince == 0 {
gp.waitsince = work.tstart
}
// 转交给g0进行扫描
systemstack(func() {
userG := getg().m.curg
selfScan := gp == userG && readgstatus(userG) == _Grunning
// 如果是扫描自己的,则转换自己的g的状态
if selfScan {
casgstatus(userG, _Grunning, _Gwaiting)
userG.waitreason = waitReasonGarbageCollectionScan
}
// 挂起 G,让对应的 G 停止运行
stopped := suspendG(gp)
if stopped.dead {
gp.gcscandone = true
return
}
if gp.gcscandone {
throw("g already scanned")
}
// 扫描g的栈
scanstack(gp, gcw)
gp.gcscandone = true
resumeG(stopped)
if selfScan {
casgstatus(userG, _Gwaiting, _Grunning)
}
})
}
}
看到上面扫描的BSS和Date相关的内存块的时候我也是感到非常的疑惑,我们结合维基百科 Data segment https://en.wikipedia.org/wiki/Data_segment 的解释可以看到:
The .data segment contains any global or static variables which have a pre-defined value and can be modified.The BSS segment, also known as uninitialized data, is usually adjacent to the data segment.
Data 段通常是提前被初始化的全局变量,BSS 段通常是没有被初始化的数据。
因为涉及到太多缓存、数据段、栈内存的扫,很多位操作和指针操作,相关代码实现比较复杂。下面简单看看 scanblock,scanstack。
scanblock
func scanblock(b0, n0 uintptr, ptrmask *uint8, gcw *gcWork, stk *stackScanState) { b := b0 n := n0 // 遍历扫描的地址 for i := uintptr(0); i < n; { // 找到bitmap中对应的byte bits := uint32(*addb(ptrmask, i/(sys.PtrSize*8))) if bits == 0 { i = sys.PtrSize * 8 continue } // 遍历 byte for j := 0; j < 8 && i < n; j { // 如果该地址包含指针 if bits&1 != 0 { p := *(*uintptr)(unsafe.Pointer(b i)) if p != 0 { // 标记在该地址的对象存活, 并把它加到标记队列 if obj, span, objIndex := findObject(p, b, i); obj != 0 { greyobject(obj, b, i, span, gcw, objIndex) } else if stk != nil && p >= stk.stack.lo && p < stk.stack.hi { stk.putPtr(p, false) } } } bits >>= 1 i = sys.PtrSize } } }scanstack
func scanstack(gp *g, gcw *gcWork) { ... // 判断是否可以安全的进行 收缩栈 if isShrinkStackSafe(gp) { // Shrink the stack if not much of it is being used. // 收缩栈 shrinkstack(gp) } else { // Otherwise, shrink the stack at the next sync safe point. // 否则下次安全点再进行收缩栈 gp.preemptShrink = true } var state stackScanState state.stack = gp.stack if gp.sched.ctxt != nil { scanblock(uintptr(unsafe.Pointer(&gp.sched.ctxt)), sys.PtrSize, &oneptrmask[0], gcw, &state) } scanframe := func(frame *stkframe, unused unsafe.Pointer) bool { scanframeworker(frame, &state, gcw) return true } // 枚举所有调用帧 gentraceback(^uintptr(0), ^uintptr(0), 0, gp, 0, nil, 0x7fffffff, scanframe, nil, 0) // 枚举所有defer的调用帧 tracebackdefers(gp, scanframe, nil) // Find and trace other pointers in defer records. // 扫描defer中的代码块 for d := gp._defer; d != nil; d = d.link { ... } if gp._panic != nil { state.putPtr(uintptr(unsafe.Pointer(gp._panic)), false) } // 扫描并找到所有可达的栈对象 state.buildIndex() for { p, conservative := state.getPtr() if p == 0 { break } obj := state.findObject(p) if obj == nil { continue } t := obj.typ // 已被扫描过 if t == nil { continue } // 标记扫描 obj.setType(nil) gcdata := t.gcdata var s *mspan if t.kind&kindGCProg != 0 { s = materializeGCProg(t.ptrdata, gcdata) gcdata = (*byte)(unsafe.Pointer(s.startAddr)) } b := state.stack.lo uintptr(obj.off) if conservative { scanConservative(b, t.ptrdata, gcdata, gcw, &state) } else { scanblock(b, t.ptrdata, gcdata, gcw, &state) } if s != nil { dematerializeGCProg(s) } } for state.head != nil { x := state.head state.head = x.next x.nobj = 0 putempty((*workbuf)(unsafe.Pointer(x))) } if state.buf != nil || state.cbuf != nil || state.freeBuf != nil { throw("remaining pointer buffers") } }greyobject
func greyobject(obj, base, off uintptr, span *mspan, gcw *gcWork, objIndex uintptr) { // obj should be start of allocation, and so must be at least pointer-aligned. if obj&(sys.PtrSize-1) != 0 { throw("greyobject: obj not pointer-aligned") } mbits := span.markBitsForIndex(objIndex) // 检查是否所有可到达的对象都被正确标记的机制, 仅除错使用 if useCheckmark { ... } else { ... // 被标记过了直接返回 if mbits.isMarked() { return } // 设置标记 mbits.setMarked() // 标记 span arena, pageIdx, pageMask := pageIndexOf(span.base()) if arena.pageMarks[pageIdx]&pageMask == 0 { atomic.Or8(&arena.pageMarks[pageIdx], pageMask) } // span的类型是noscan, 则不需要把对象放入标记队列 if span.spanclass.noscan() { gcw.bytesMarked = uint64(span.elemsize) return } } // 尝试存入gcwork的缓存中,或全局队列中 if !gcw.putFast(obj) { gcw.put(obj) } }对象扫描
辅助标记 mutator assists
func scanobject(b uintptr, gcw *gcWork) { // 获取 b 的 heapBits 对象 hbits := heapBitsForAddr(b) // 获取 span s := spanOfUnchecked(b) // span 对应的对象大小 n := s.elemsize if n == 0 { throw("scanobject n == 0") } // 每次最大只扫描128KB if n > maxObletBytes { // Large object. Break into oblets for better // parallelism and lower latency. if b == s.base() { if s.spanclass.noscan() { // Bypass the whole scan. gcw.bytesMarked = uint64(n) return } // 把多于128KB的对象重新放回gcworker中,下次再扫描 for oblet := b maxObletBytes; oblet < s.base() s.elemsize; oblet = maxObletBytes { if !gcw.putFast(oblet) { gcw.put(oblet) } } } n = s.base() s.elemsize - b if n > maxObletBytes { n = maxObletBytes } } var i uintptr for i = 0; i < n; i = sys.PtrSize { // 获取对应的bit // Find bits for this word. if i != 0 { hbits = hbits.next() } bits := hbits.bits() // 检查scan bit判断是否继续扫描 if i != 1*sys.PtrSize && bits&bitScan == 0 { break // no more pointers in this object } // 如果不是指针则继续 if bits&bitPointer == 0 { continue // not a pointer } // 取出指针的值 obj := *(*uintptr)(unsafe.Pointer(b i)) if obj != 0 && obj-b >= n { // 根据地址值去堆中查找对象 if obj, span, objIndex := findObject(obj, b, i); obj != 0 { // 调用 greyobject 标记对象并把对象放到标记队列中 greyobject(obj, b, i, span, gcw, objIndex) } } } gcw.bytesMarked = uint64(n) gcw.scanWork = int64(i) }在分析的一开始也提到了一些关于 mutator assists 的作用,主要是为了防止 heap 增速太快, 在GC 执行的过程中如果同时运行的 G 分配了内存, 那么这个 G 会被要求辅助 GC 做一部分的工作,它遵循一条非常简单并且朴实的原则,分配多少内存就需要完成多少标记任务。
mutator assists 的入口是在 go\src\runtime\malloc.go 的mallocgc 函数中:
func mallocgc(size uintptr, typ *_type, needzero bool) unsafe.Pointer { ... var assistG *g if gcBlackenEnabled != 0 { assistG = getg() if assistG.m.curg != nil { assistG = assistG.m.curg } // 减去内存值 assistG.gcAssistBytes -= int64(size) if assistG.gcAssistBytes < 0 { // This G is in debt. gcAssistAlloc(assistG) } } ... return x }mallocgc 在分配内存的时候每次都会检查 gcAssistBytes 字段是否为负值,这个字段存储了当前 Goroutine 辅助标记的对象字节数。如果为负数,那么会调用 gcAssistAlloc 从全局信用 bgScanCredit 中获取:
func gcAssistAlloc(gp *g) { ... retry: // 计算需要完成的标记任务数量 debtBytes := -gp.gcAssistBytes scanWork := int64(gcController.assistWorkPerByte * float64(debtBytes)) if scanWork < gcOverAssistWork { scanWork = gcOverAssistWork debtBytes = int64(gcController.assistBytesPerWork * float64(scanWork)) } // 获取全局辅助标记的字节数 bgScanCredit := atomic.Loadint64(&gcController.bgScanCredit) stolen := int64(0) if bgScanCredit > 0 { if bgScanCredit < scanWork { stolen = bgScanCredit gp.gcAssistBytes = 1 int64(gcController.assistBytesPerWork*float64(stolen)) } else { stolen = scanWork gp.gcAssistBytes = debtBytes } // 全局信用扣除stolen点数 atomic.Xaddint64(&gcController.bgScanCredit, -stolen) scanWork -= stolen // 减到 0 说明 bgScanCredit 是由足够的信用可以处理 scanWork if scanWork == 0 { return } } // 到这里说明 bgScanCredit 小于 scanWork // 需要调用 gcDrainN 完成指定数量的标记任务并返回 systemstack(func() { // 执行标记任务 gcAssistAlloc1(gp, scanWork) }) completed := gp.param != nil gp.param = nil if completed { gcMarkDone() } if gp.gcAssistBytes < 0 { if gp.preempt { Gosched() goto retry } // 如果全局信用仍然不足将当前 Goroutine 陷入休眠 // 加入全局的辅助标记队列并等待后台标记任务的唤醒 if !gcParkAssist() { goto retry } } }如果全局信用仍然不足将当前 Goroutine 陷入休眠 ,加入全局的辅助标记队列并等待后台标记任务的唤醒。
扫描内存时调用 gcFlushBgCredit 会负责唤醒辅助标记 Goroutine :
func gcFlushBgCredit(scanWork int64) { // 辅助队列中不存在等待的 Goroutine if work.assistQueue.q.empty() { // 当前的信用会直接加到全局信用 bgScanCredit atomic.Xaddint64(&gcController.bgScanCredit, scanWork) return } scanBytes := int64(float64(scanWork) * gcController.assistBytesPerWork) lock(&work.assistQueue.lock) // 如果辅助队列不为空 for !work.assistQueue.q.empty() && scanBytes > 0 { gp := work.assistQueue.q.pop() // 唤醒 Goroutine if scanBytes gp.gcAssistBytes >= 0 { scanBytes = gp.gcAssistBytes gp.gcAssistBytes = 0 ready(gp, 0, false) } else { gp.gcAssistBytes = scanBytes scanBytes = 0 work.assistQueue.q.pushBack(gp) break } } // 标记任务量仍然有剩余,这些标记任务都会加入全局信用 if scanBytes > 0 { scanWork = int64(float64(scanBytes) * gcController.assistWorkPerByte) atomic.Xaddint64(&gcController.bgScanCredit, scanWork) } unlock(&work.assistQueue.lock) }gcFlushBgCredit 会获取睡眠的辅助队列 Goroutine ,如果当前信用足够,那么就会将辅助 Goroutine 唤醒,如果还有剩余的,那么就会将这些标记任务都会加入全局信用。
总体来说是如下的一套机制:
完成标记
上面我们在 gcBgMarkWorker 中分析了,在标记完成后会调用 gcMarkDone 执行标记完成操作。
func gcMarkDone() { semacquire(&work.markDoneSema) top: // 再次检查任务是否已执行完毕 if !(gcphase == _GCmark && work.nwait == work.nproc && !gcMarkWorkAvailable(nil)) { semrelease(&work.markDoneSema) return } semacquire(&worldsema) gcMarkDoneFlushed = 0 systemstack(func() { gp := getg().m.curg casgstatus(gp, _Grunning, _Gwaiting) // 遍历所有的 P forEachP(func(_p_ *p) { // 将 P 对应的write barrier buffer 中的对象加入到 gcWork 中 wbBufFlush1(_p_) // 将 gcWork 中的缓存对象加入到全局队列中 _p_.gcw.dispose() // 表示 gcWork 的数据都已迁移到 全局队列中 if _p_.gcw.flushedWork { atomic.Xadd(&gcMarkDoneFlushed, 1) _p_.gcw.flushedWork = false } else if debugCachedWork { ... } ... }) casgstatus(gp, _Gwaiting, _Grunning) }) if gcMarkDoneFlushed != 0 { if debugCachedWork { // Release paused gcWorks. atomic.Xadd(&gcWorkPauseGen, 1) } semrelease(&worldsema) goto top } // 记录完成标记阶段开始的时间和STW开始的时间 now := nanotime() work.tMarkTerm = now work.pauseStart = now // 禁止G被抢占 getg().m.preemptoff = "gcing" // STW systemstack(stopTheWorldWithSema) ... // 禁止辅助GC和后台标记任务的运行 atomic.Store(&gcBlackenEnabled, 0) // 唤醒所有因为辅助GC而休眠的G gcWakeAllAssists() semrelease(&work.markDoneSema) schedEnableUser(true) // 计算下一次触发gc需要的heap大小 nextTriggerRatio := gcController.endCycle() // 执行标记终止 gcMarkTermination(nextTriggerRatio) }gcMarkDone 会调用 forEachP 函数遍历所有的 P ,并将对应 P 中的 gcWork 中的任务移动到全局队列中,如果 gcWork 中有任务那么会将 gcMarkDoneFlushed 加1,遍历完所有的 P 之后会判断如果 gcMarkDoneFlushed 不为0,那么跳转到 top 标记位继续循环执行,直到本地队列中没有任务为止。
接下来会关将 gcBlackenEnabled 设置为0,表示关闭辅助标记协程以及后台标记;唤醒被阻塞的辅助标记协程;调用 schedEnableUser 恢复用户 Goroutine 的调度;需要注意的是,目前处在 STW 阶段,所以被唤醒的 Goroutine 不会立马执行,会等到 STW 结束后才执行。
最后调用 gcMarkTermination 执行标记终止。
标记终止
func gcMarkTermination(nextTriggerRatio float64) { // 禁止辅助GC和后台标记任务的运行 atomic.Store(&gcBlackenEnabled, 0) // 将 GC 阶段切换到 _GCmarktermination setGCPhase(_GCmarktermination) work.heap1 = memstats.heap_live // 记录开始时间 startTime := nanotime() mp := acquirem() mp.preemptoff = "gcing" _g_ := getg() _g_.m.traceback = 2 gp := _g_.m.curg // 设置 G 的状态为等待中 casgstatus(gp, _Grunning, _Gwaiting) gp.waitreason = waitReasonGarbageCollection // 切换到 g0 运行 systemstack(func() { // 开始 STW 中的标记 gcMark(startTime) }) systemstack(func() { work.heap2 = work.bytesMarked ... // 设置当前GC阶段到关闭, 并禁用写屏障 setGCPhase(_GCoff) // 唤醒后台清扫任务 gcSweep(work.mode) }) _g_.m.traceback = 0 casgstatus(gp, _Gwaiting, _Grunning) // 统计以及重置清扫状态相关代码 ... // 统计执行GC的次数然后唤醒等待清扫的G lock(&work.sweepWaiters.lock) memstats.numgc injectglist(&work.sweepWaiters.list) unlock(&work.sweepWaiters.lock) // 性能统计 mProf_NextCycle() // 重新 start The World systemstack(func() { startTheWorldWithSema(true) }) // 性能统计 mProf_Flush() // 移动标记队列使用的 workbuf 到 free list, 使得它们可以被回收 prepareFreeWorkbufs() // 释放未使用的栈 systemstack(freeStackSpans) // 确保每个 P 的 mcache 都被 flush systemstack(func() { forEachP(func(_p_ *p) { _p_.mcache.prepareForSweep() }) }) ... semrelease(&worldsema) semrelease(&gcsema) releasem(mp) mp = nil }gcMarkTermination 主要是做一些确认工作以及统计工作。进入到这个方法首先会将 GC 阶段设置到 _GCmarktermination,然后调用 gcMark 方法确认是否所有的 GC 标记工作已经完成。接着将 GC 阶段设置到 _GCoff,调用 gcSweep 开始清理工作。接着就是省略的数据统计相关的代码,包括正在使用的内存大小、GC 时间、CPU 利用率等。最后做一些确认工作,如确保每个 P 的 mcache 都被 flush ,栈都释放了,workbuf 都转移到 free list 以便回收等。
后台清扫
func gcSweep(mode gcMode) { if gcphase != _GCoff { throw("gcSweep being done but phase is not GCoff") } lock(&mheap_.lock) mheap_.sweepgen = 2 // 重置标记位 mheap_.sweepdone = 0 ... mheap_.pagesSwept = 0 mheap_.sweepArenas = mheap_.allArenas mheap_.reclaimIndex = 0 mheap_.reclaimCredit = 0 unlock(&mheap_.lock) if go115NewMCentralImpl { sweep.centralIndex.clear() } // 如果非并行GC if !_ConcurrentSweep || mode == gcForceBlockMode { ... return } // 唤醒后台清扫任务 lock(&sweep.lock) if sweep.parked { sweep.parked = false ready(sweep.g, 0, true) } unlock(&sweep.lock) }gcSweep 主要做的是重置清理阶段的相关状态,然后唤醒 sweep 清扫 Goroutine 。后台清扫任务是在初始化 main Goroutine 的时候调用 bgsweep 设置的:
gcenable
func gcenable() { // Kick off sweeping and scavenging. c := make(chan int, 2) // 设置异步清扫 go bgsweep(c) <-c }bgsweep
func bgsweep(c chan int) { // 设置清扫 Goroutine sweep.g = getg() // 等待唤醒 lockInit(&sweep.lock, lockRankSweep) lock(&sweep.lock) sweep.parked = true c <- 1 goparkunlock(&sweep.lock, waitReasonGCSweepWait, traceEvGoBlock, 1) // 循环清扫 for { // 清扫一个span, 然后进入调度 for sweepone() != ^uintptr(0) { sweep.nbgsweep Gosched() } // 释放一些未使用的标记队列缓冲区到heap for freeSomeWbufs(true) { Gosched() } lock(&sweep.lock) // 判断 sweepdone 标志位是否等于 0 // 如果清扫未完成则继续循环 if !isSweepDone() { unlock(&sweep.lock) continue } // 否则让后台清扫任务进入休眠 sweep.parked = true goparkunlock(&sweep.lock, waitReasonGCSweepWait, traceEvGoBlock, 1) } }bgsweep 的清扫任务实际上是由 sweepone 进行的,它会在堆内存中查找待清理的 span,并且会返回清扫了多少 page 到 heap 中,返回 ^uintptr(0)表示没有东西需要清扫:
func sweepone() uintptr { _g_ := getg() sweepRatio := mheap_.sweepPagesPerByte // For debugging _g_.m.locks // 校验是否清扫已完成 if atomic.Load(&mheap_.sweepdone) != 0 { _g_.m.locks-- return ^uintptr(0) } atomic.Xadd(&mheap_.sweepers, 1) //查找一个 span 并释放 var s *mspan sg := mheap_.sweepgen for { if go115NewMCentralImpl { s = mheap_.nextSpanForSweep() } else { s = mheap_.sweepSpans[1-sg/2%2].pop() } if s == nil { atomic.Store(&mheap_.sweepdone, 1) break } if state := s.state.get(); state != mSpanInUse { continue } // span 的 sweepgen 等于 mheap.sweepgen - 2,那么意味着当前单元需要清理 if s.sweepgen == sg-2 && atomic.Cas(&s.sweepgen, sg-2, sg-1) { break } } // 清理 span npages := ^uintptr(0) if s != nil { npages = s.npages // 回收内存 if s.sweep(false) { atomic.Xadduintptr(&mheap_.reclaimCredit, npages) } else { npages = 0 } } _g_.m.locks-- return npages }在查找 span 的时候会通过 state 状态以及 sweepgen 是否等于 mheap.sweepgen - 2 来判断是否需要清扫该 span。最终会通过 mspan.sweep 来进行清扫。
下面简单看一下 sweep的实现:
总结
func (s *mspan) sweep(preserve bool) bool { if !go115NewMCentralImpl { return s.oldSweep(preserve) } _g_ := getg() sweepgen := mheap_.sweepgen // 统计已清理的页数 atomic.Xadd64(&mheap_.pagesSwept, int64(s.npages)) spc := s.spanclass size := s.elemsize c := _g_.m.p.ptr().mcache ... // 计算释放的对象数量 nalloc := uint16(s.countAlloc()) nfreed := s.allocCount - nalloc s.allocCount = nalloc s.freeindex = 0 // reset allocation index to start of span. s.allocBits = s.gcmarkBits s.gcmarkBits = newMarkBits(s.nelems) s.refillAllocCache(0) // 设置 span.sweepgen 和 mheap.sweepgen 相等 atomic.Store(&s.sweepgen, sweepgen) if spc.sizeclass() != 0 { // 处理小对象的回收 // Handle spans for small objects. if nfreed > 0 { s.needzero = 1 c.local_nsmallfree[spc.sizeclass()] = uintptr(nfreed) } if !preserve { if nalloc == 0 { // 直接释放 span 到堆中 mheap_.freeSpan(s) return true } // 将 span 释放到 mcentral 中 if uintptr(nalloc) == s.nelems { mheap_.central[spc].mcentral.fullSwept(sweepgen).push(s) } else { mheap_.central[spc].mcentral.partialSwept(sweepgen).push(s) } } } else if !preserve { // 处理大对象的回收 if nfreed != 0 { // Free large object span to heap. if debug.efence > 0 { s.limit = 0 // prevent mlookup from finding this span sysFault(unsafe.Pointer(s.base()), size) } else { // 直接释放 span 到堆中 mheap_.freeSpan(s) } c.local_nlargefree c.local_largefree = size return true } // Add a large span directly onto the full swept list. mheap_.central[spc].mcentral.fullSwept(sweepgen).push(s) } return false }这篇文章和内存分配、循环调度的关联关系非常的大,所以必须要弄懂前两篇才能理解 GC 的原理。
,






