
19世纪,人类迎来了科学大爆发
物理学在电光热各个领域都迎来了突破性进展
元素周期表的发现,
让化学从一门毫无规律,极度考验记忆力的学科
变得有规律可循
而生物学,同样迎来了巨大的进步
细胞学说,进化论,遗传学说让生物学从一门分类学,
变成了独立的科学
细胞学说之于生物
如同原子论对化学一般重要
因为细胞是构建生命体的基石
每一个生命都是由不同细胞组成的知道的越多,恐惧的越少
大家好,我是头发永远比你少的晨晨爸爸
今天我们来看看细胞的工作
细胞
上篇我们通过有机化学了解了生命的基础物质
但并不是把这些物质凑一块就能变成细胞了
一套最基本的细胞设备需要拥有以下几个部件:
一本说明书(DNA)
一套能够阅读说明书的RNA和核糖体,
负责把这些东西包裹起来的膜以及胞质溶胶
这些部件产品凑一块
才能组成生命的基本单元
当然,这是最简陋的状态
形成的就是原核生物
原核生物主要包括细菌和古菌
比如我们肠道中的大肠杆菌就是原核生物
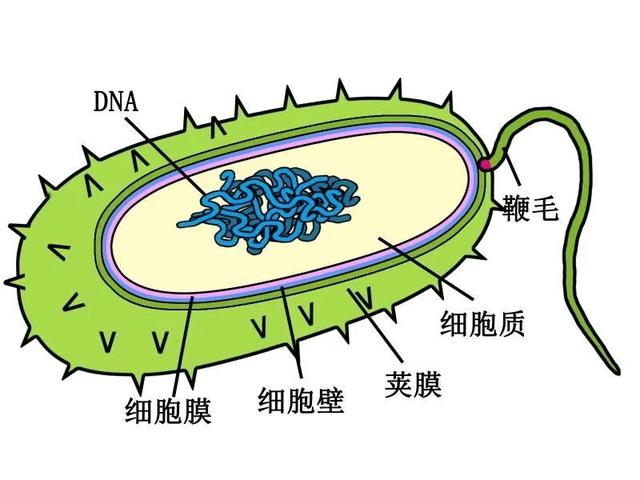
而我们肉眼能看见的绝大部分生物,
都属于另一大类
真核生物
我们可以理解为
真的有一个核的生物
啥核呢?
细胞核
相对于原核生物的简陋茅草屋
真核生物的细胞
那就是金碧辉煌的皇宫

真核生物有小部分以单细胞存在
其余大部分都是多细胞生物
我们眼睛能直接看到的生物
都是真核生物
比如人类,蚊子,树木等等
真核生物的细胞形状多样
尺寸差别也很大
比如
人类的皮肤细胞,神经细胞,血红细胞,肝脏细胞等等
长得都不一样
但无论人类的细胞长成啥样
都来源于同一个祖宗——受精卵
受精卵的一次又一次分裂
分化出了不同外形和功能的细胞

现在
让我们进入细胞内部看一看
每个真核细胞基本都会有下面这几个部件:
一层内膜包裹着DNA形成细胞核
在细胞核外
有线粒体,负责制造发动机ATP
有内质网,上面布满了核糖体用来制造蛋白质
在细胞内的胞质溶胶中还有游离的核糖体,作用一样
高尔基体负责将蛋白质分类包装运输到工作场所
外面一层是质膜
把这些物质打包包裹起来。
这就是个典型的真核细胞
当然,这是真核细胞最基本的组成
不同细胞还有不同的物质

植物的细胞略有不同
除了上面提到的物质
在质膜外面还有一圈细胞壁
主要由纤维素和其他多糖组成
因为植物无法走动到河边喝水
所以植物细胞会把水分储存在质膜和细胞壁中间
在植物细胞内部
还有一个不同于动物的特殊部件——叶绿体
用来吸收二氧化碳制造葡萄糖和氧气
这些我们后面再说

让我们先翻阅说明书DNA
生命的秘密全部藏在说明书DNA里
这是怎么做到的?
实际上细胞发挥作用主要靠各种蛋白质
我们在前面了解过蛋白质的四级结构
知道蛋白质是一种折叠的多聚体
虽然蛋白质的结构很复杂
但如果给定的氨基酸序列是固定的
蛋白质会总是以完全相同的方式折叠
所以如果细胞要制造蛋白质
只需要记住多肽的顺序就行
上面这段结论刚提出来的时候真是石破惊天
但是情况就是这么个情况
提出的人后来获得了诺奖

而记住这个顺序靠的就是DNA
这份蛋白质序列的清单就隐藏在DNA分子中
我们也可以换一个熟悉的词
那就是基因组
上个世纪开展的人类基因组计划
测定了人类染色体中包含的所有30亿个碱基对组成的核苷酸序列
基因的表达
基因组通过各种碱基配对
储存了生命信息
而细胞通过读取这些储存的信息制造蛋白质
这一过程是怎样的?
如果我们忽略细节,就很简单,
只有两步
转录和翻译
比把大象关进冰箱还少一步

当然,
事情没有我说的这么简单
首先是转录
因为DNA非常重要
被保护在细胞核中
所谓千金之子坐不垂堂
不能让DNA自己到外面冒险工作
只能是由一个信使把DNA的信息传达出去
这个信使需要能够清楚DNA的要求
怎么做到呢?
靠的就是转录
转录可以理解为把标准答案抄写到另一个本子上

一条DNA链
由两条脱氧核苷酸链互相缠绕配对
叫做双螺旋结构
这两条脱氧核苷酸链
由四种碱基反向互补组成
四种碱基分别是AGCT
组成规则很简单
A的对面一定是T
C的对面一定是G
反过来也一样
所以要传递DNA的信息就简单了
只要组成一条链跟它按照这个规则配对
配对完成后
相当于复制了一遍信息
这条配对的链就相当于把DNA的信息拷贝走了
再从细胞核中出来
到外面指导合成蛋白质的工作即可

所以转录的第一步
解开双螺旋结构
这需要一种酶
叫做RNA聚合酶
需要转录的时候
RNA聚合酶会到DNA的指定位置解旋并打开双链
细胞核中游离的核糖核苷酸
按照配对原则在聚合酶内一个一个的连上去
这个过程中
碱基U会替换掉碱基T与A配对
形成一条RNA链
当RNA聚合酶到了需要终止的位置
会得到一个结束信号。
于是我们得到了一个信使RNA
代号mRNA

转录过程就此结束
然后DNA,RNA聚合酶和信使RNA就此分离
当然,事情还没完
此时的信使RNA中
每隔一段会有不能编译蛋白质的内含子
所以还需要一个过程
一种叫做剪接体的蛋白质出现了
剪接体蛋白质“找到”内含子
把它们的首尾端连在一起
然后咔嚓,剪掉
剩下的部分就是能够翻译成蛋白质编码片段
叫做外显子
剪完之后,外显子会完美的连在一起
一个真正可以翻译的信使RNA就形成了
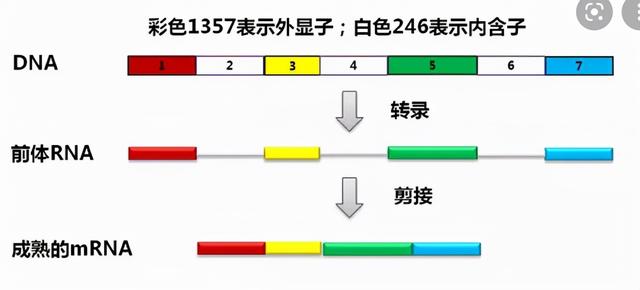
随后这个信使RNA离开细胞核进入到细胞质中
为了把基因翻译成蛋白质
细胞会读取这段信使RNA的信息
每三个碱基为一个词
叫做密码子
比如AUC,GAC,CGG等等
每个密码子会配对一个氨基酸
4个碱基中每三个组成一组的话
一共有64种组合
但是只有20种氨基酸
所以有一些不同密码子是“同义词”
它们编码的是相同的氨基酸
全套的翻译对照表叫做遗传密码
如下图这样

这套密码是通用的
每一种生物都在使用这套密码
其中有三个终止密码子
当翻译到这三种终止密码子中的某一个时
一个多肽链的制造就完成了
现在问题来了
氨基酸又没有密码子
他们是怎么套上去的?
这个问题一直被各种猜测
直到70多年前
人类才明白了其中的过程
一个真核细胞的mRNA起始端
会被加一个鸟嘌呤帽
一个核糖体被固定在鸟嘌呤帽的位置
此时就要呼叫另一个RNA出场了
它叫转运RNA,代号tRNA
转运RNA的头部有3个碱基的反密码子
尾部有一个和氨基酸结合位点
为什么叫反密码子?
因为和密码子是反的
比如遗传密码表里的AUG表达的甲硫氨酸
根据配对原则
与他相反的配对密码子是UAC
那么带有UAC三个碱基的转运RNA
配对的就是一个甲硫氨酸

那么后面就容易了
所有的信使RNA第一个密码子一定是AUG
一个头部带有UAC反密码子的转运RNA
来到核糖体内
正好跟信使RNA上的AUG结合
这个转运RNA携带的甲硫氨酸就成为了第一个氨基酸
核糖体不断从mRNA的5’方向朝3’方向移动
携带不同氨基酸的转运RNA
根据互补配对原则不断地进来
他们携带的氨基酸会脱离转运RNA
与后面的氨基酸结合形成多肽链
而没有氨基酸的转运RNA会离开继续寻找相配对的氨基酸
这过程不断地持续
多肽链越来越长
直到遇到三个终止密码子
翻译过程结束
一个多肽链就形成了

这里插播一个小知识,前面忘了讲了
就是什么是5’和3’
在前一篇里我们知道核糖的结构是这样的

因为在翻译过程中有方向
人们为了确定这个方向
给核糖体的每个碳标记了记号
1’一直到5’
这样我们要指出方向时
只要说说从5’到3’或者3’到5’就可以了。
当然,
你也可以不按这个规则来,
自己定义一套标记,
比如把五个碳定义为五根手指,
然后说从大拇指到中指的方向,
或者中指到大拇指方向运动也行
不过由于大家用上面那套话语体系时间长了,
你自己定义一套标记,
跟别人交流的时候还要翻译一下,比较麻烦。
上面的过程是真核细胞中转录和翻译的典型过程
而在原核细胞中
由于没有细胞核
这个过程是同时完成的
信使RNA在转录过程中
同时直接开始翻译
核糖体会从一个AGGAGG的序列开始结合到信使RNA上
然后一路向3’方向前进,
直到到达密码子AUG
也就是我们说的每个蛋白质的起始位置
开始进行翻译
剩下的过程大同小异。
一个多肽链形成之后
根据我们上一篇所讲
蛋白质会形成四级结构
这样一个过程我们叫做基因的表达
因为蛋白质是生命活动的主要承担着
基因通过这个过程来调控整个生命活动

那么蛋白质制造出来之后
该何去何从
他们又是如何参与这纷繁复杂的生命活动?
下一期
我们一起探索蛋白质在身体里的运作方式
你会发现一个无比精巧的世界!
知道的越多,恐惧的越少
我们是三个老爸实验室
你的每一次素质三连都将决定未来内容市场的方向
欢迎点赞,评论,转发支持我们
如果觉得我说的还不错
点个关注再走呗
拥有无比精巧设计的人类们!
,




